[C9] 降维(Dimensionality Reduction)
降维(Dimensionality Reduction)
动机一:数据压缩(Motivation I : Data Compression)
数据压缩允许我们压缩数据,从而使用较少的计算机内存或磁盘空间,还会加快算法的学习速度。
下面举例说明下降维是什么?
在工业上,往往有成百上千个特征。比如,可能有几个不同的工程团队,一个团队给了你二百个特征,第二个团队给了你另外三百个的特征,第三团队给了你五百个特征,一千多个特征都在一起,那么实际上,如果你想去追踪一下你所知道的那些特征会变得相当困难,而你又不希望存在那么多高度冗余的特征。所以,就需要用到降维技术。
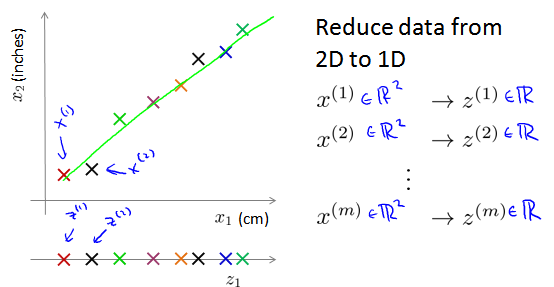
如上图,假设我们采用两种不同的仪器来测量的一个物体的尺寸,其中一个仪器测量结果的单位是英寸,另一个仪器测量结果的单位是厘米,我们希望将测量的结果作为我们机器学习的特征。现在问题是,两种仪器对同一个东西测量的结果不完全相等(由于误差、精度等),而将两者都作为特征又有些重复,因而,我们希望将这个二维的数据降至一维。具体地,对于2D -> 1D,我们可以把2D的特征投影到上图中的绿色线上,就变成1D数据了,得到一个新的向量Z。X 是 m * 2的,而新的Z是 m * 1的。
这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,例如将1000维的特征降至100维。但是这不能在图片中展示出来,所以接下来我们列举一个将数据从三维降至二维的例子,如下图:
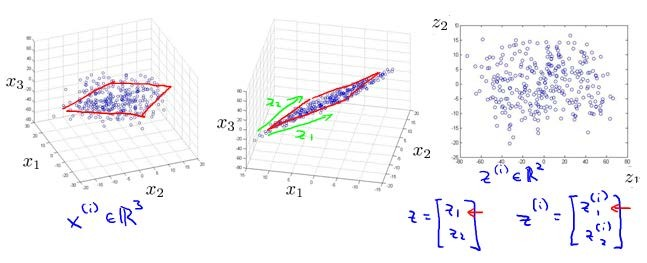
上面第一幅图为原始样本的可视化,可以看到呈现3D点云状,我们可以寻找一个平面,将它们都投影到该平面上,得到一个 m * 2 的向量 Z,如上面中间的图所示。然后就可以在一个二维图形中表示出来,如上面图三所示。这样就把数据从3D降至了2D。
动机二:数据可视化(Motivation II : Visualization)
在许多机器学习问题中,如果我们能将数据可视化,我们便能寻找到一个更好的解决方案,降维可以帮助我们。
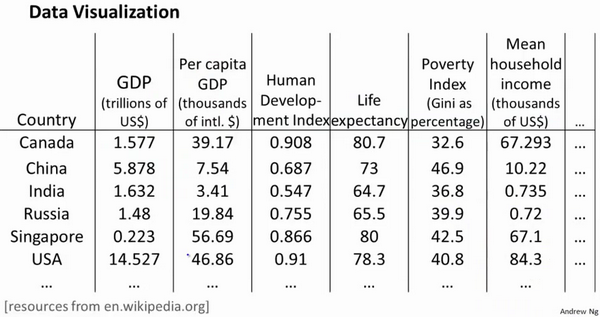
假设我们有关于许多不同国家的数据,每一个特征向量(代表一个国家)都有50个特征(如GDP,人均GDP,平均寿命等)。如果要将这个50维的数据可视化是不可能的。使用降维的方法将其降至2维,我们便可以将其可视化了。
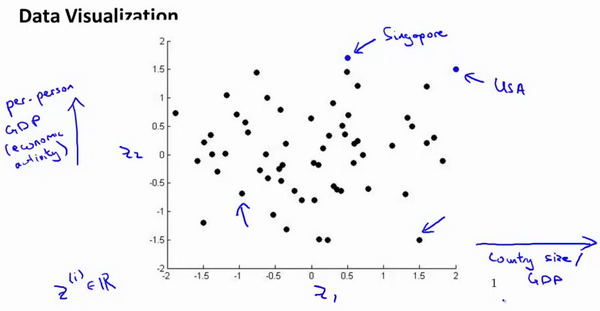
降维的算法只负责减少维数,新产生特征的实际意义需要我们自己去发现。
主成分分析问题(Principal Component Analysis Problem Formulation)
主成分分析(PCA)是最常见的降维算法。
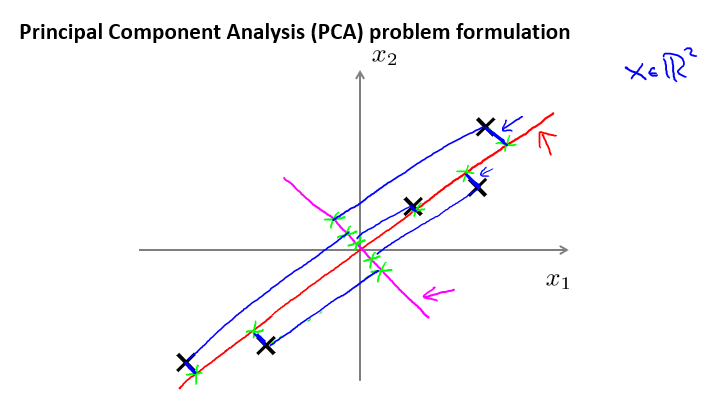
如上图,PCA的做法是找一个低维平面,然后把每个样本投射到该平面上(上图中的红色线),使样本到低维平面(红色直线)的距离(垂直)最短,也就是样本到低维平面的垂直距离的平方最小,它也叫投影误差。对比刚才的红色直线,如果把低维平面换成图中的粉色直线,那么你会发现那会相当的糟糕,投影的距离非常的大。这意味这,PCA会选择类似红色的线而不是粉色的线。
让我们更正式的表述一下PCA问题:
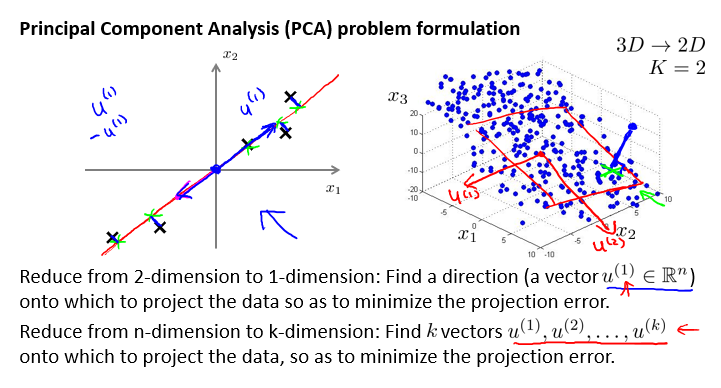
如果我们想把数据从二维降到一维,PCA做的是寻找一个方向向量(direction vector),假设是 \(u^{(i)}\),它属于 \(\mathbb{R}^n\),这里是 \(u^{(1)} \in \mathbb{R}^2\),如上图左侧图所示,我们要找一个投影后能够最小化投影误差的方向,也就是图中的 \(u^{(1)}\),当把数据投影到它和它的延展线上时可以得到非常小的重构误差(reconstruction error),另外无论PCA给出的是 \(u^{(1)}\),还是负的 \(u^{(1)}\)都没关系,因为两个方向都定义了同一个直线。这就是2D->1D的例子。
更通常的是,将数据从 n 维降到 k 维,这种情况下,我们不只是想找单个向量,而是寻找 k 个方向来对数据进行投影,来最小化投影误差,举个例子,如上面右侧的图所示,3D->2D,PCA需要找到两个向量 \(u^{(1)}\) 和 \(u^{(2)}\),这两个向量定义了一个二维平面,可以将数据投影到它上面。从线性代数的角度,更正式的定义是寻找到一组向量,\(u^{(1)}\),\(u^{(2)}\),...,\(u^{(k)}\),然后将数据投影到这 k 个向量展开后得到的线性子空间(linear subspace)上。所以对于PCA来讲,目的就是能够找出最小化投影距离(90度或正交投影)的方式来对数据进行投影。
PCA与线性回归比较
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投射误差(Projected Error),而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。
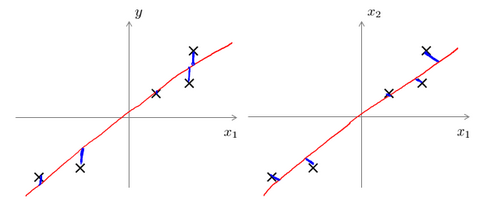
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。
PCA将\(n\)个特征降维到\(k\)个,可以用来进行数据压缩,如果100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩。但PCA 要保证降维后,还要保证数据的特性损失最小。
PCA技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
主成分分析算法(Principal Component Analysis Algorithm)
PCA 将数据从 \(n\) 维到 \(k\)维:
第一步是对数据进行预处理,即特征缩放或均值归一化(feature scaling / mean normalization)。我们需要计算出所有特征的均值 \(\mu_j = \frac{1}{m}\sum\limits_{i=1}^{m}x_j^{(i)}\),然后令 \(x_j= x_j - μ_j\)。如果不同的特征有非常不同的缩放(比如线性回归例子中的房屋尺寸和房间数量),那么还需要将其除以标准差 \(σ^2\)。
第二步是计算协方差矩阵(covariance matrix)\(Σ\):
\(\sum=\dfrac {1}{m}\sum\limits^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T}\),
协方差矩阵总是满足数学上的一个性质叫对称正定矩阵(symmetric positive definite matrix)第三步是计算协方差矩阵 \(Σ\) 的特征向量(eigenvectors):
在 Octave 里我们可以利用奇异值分解(singular value decomposition)来求解,[U, S, V]= svd(sigma)。
其中,\(U = \begin{bmatrix} \vdots & \vdots & & \vdots \\[0.3em] u^{(1)} & u^{(2)} & \cdots & u^{(n)} \\[0.3em] \vdots & \vdots & & \vdots \end{bmatrix} \in \mathbb{R}^{n \times n}\)
\(\Sigma\) 和 \(U\) 都是一个 \(n×n\) 维的矩阵,其中 \(U\) 是一个由具有与样本数据之间最小投射误差的方向向量构成的矩阵。如果我们希望将数据从\(n\) 维降至 \(k\) 维,我们只需要从 \(U\) 中选取前 \(k\) 个向量,获得一个\(n×k\) 维度的矩阵,我们用\(U_{reduce}\)表示,然后通过如下计算获得要求的新特征向量 \(z^{(i)}\) :
\(z^{(i)}=U^{T}_{reduce}*x^{(i)}\)
其中 \(x\) 是 \(n \times 1\) 维的,因此结果为 \(k \times 1\) 维。注,我们不对方差特征进行处理。
原始数据重构(reconstruction from compressed representation)
PCA作为压缩算法,你可能需要把1000维的数据压缩到100维特征,或是从3D压缩到2D or 1D。所以,如果这是一个压缩算法,那么它也应该能再次从压缩后的数据恢复到原始的数据,或者是恢复到原有的高维数据的一种近似。
所以,给定的\(z^{(i)}\),这可能100维,怎么回到你原来的\(x^{(i)}\),这可能是1000维的数据?
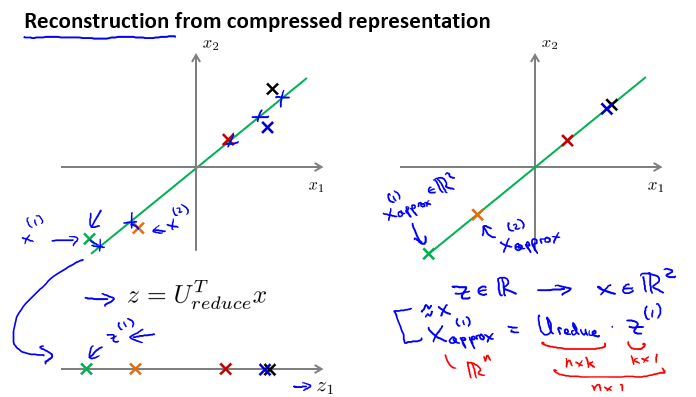
压缩是 \(z=U^{T}_{reduce}x\),其相反的方程为:\(x_{appox}=U_{reduce}\cdot z\), 其中 \(x_{appox} \approx x\)
选择主成分的数量(choosing the number of principal components)
我们希望在 均方投影误差 与 训练集方差 的比例尽可能小(差异小)的情况下选择尽可能小的 \(k\) 值。比例小于1%,意味着原始数据的偏差有99%都被保留,如保留95%的偏差,便能非常显著地降低模型中特征的维度了。具体做法是,我们可以先令 \(k=1\),然后运行PCA,获得 \(U_{reduce}\) 和 \(z\) 之后,计算出 \(x_{approx}\), 然后计算比例是否小于1%。如果不是的话再令 \(k=2\),如此类推,直到找到可以使得比例小于1%的最小\(k\) 值(我的理解是,想找到一个 \(k\) ,使得它之前的特征都不相关,而它后面的特征都多少有些相关性,冗余,所以省略掉 -- 有待验证)。比例的计算公式如下:
Average squared projection error(均方投影误差): \(\dfrac {1}{m}\sum\limits^{m}_{i=1}\left\| x^{\left( i\right) }-x^{\left( i\right) }_{approx}\right\| ^{2}\)
Total variation in the data(数据总变化量,即训练集的方差): \(\dfrac {1}{m}\sum\limits^{m}_{i=1}\left\| x^{\left( i\right) }\right\| ^{2}\)
Typically, choose \(k\) to be smallest value so that
\(\dfrac {\dfrac {1}{m}\sum\limits^{m}_{i=1}\left\| x^{\left( i\right) }-x^{\left( i\right) }_{approx}\right\| ^{2}}{\dfrac {1}{m}\sum\limits^{m}_{i=1}\left\| x^{(i)}\right\| ^{2}} \leq 1\%\)
注:有一种更好的方法来计算这个比例:
当我们在Octave中调用“svd”函数后会获得三个参数:[U, S, V] = svd(sigma)。其中的 S 如下:
\(S = \begin{bmatrix} S_{11} &0&0&0&0\\[0.3em] 0&S_{22}&0&0&0 \\[0.3em] 0&0&S_{33}&0&0 \\[0.3em] 0&0&0&\ddots&0 \\[0.3em] 0&0&0&0&S_{nn} \end{bmatrix}\)
它是一个 \(n \times n\) 的矩阵,只有对角线上有值,而其它单元都是0,我们可以使用这个矩阵来计算均方投影误差与训练集方差的比例,公式如下:
\(\dfrac {\dfrac {1}{m}\sum\limits^{m}_{i=1}\left\| x^{\left( i\right) }-x^{\left( i\right) }_{approx}\right\| ^{2}}{\dfrac {1}{m}\sum\limits^{m}_{i=1}\left\| x^{(i)}\right\| ^{2}}=1-\dfrac {\sum\limits^{k}_{i=1}S_{ii}}{\sum\limits^{n}_{i=1}S_{ii}}\leq 1\%\),即:\(\frac {\sum\limits^{k}_{i=1}s_{ii}}{\sum\limits^{n}_{i=1}s_{ii}} \geq 0.99\)
如此, "99% of variance is retained"
主成分分析法的应用建议(Advice for Applying PCA)
假使我们正在针对一张 100×100像素的图片进行某个计算机视觉的机器学习,即总共有10000 个特征。
- 第一步是运用主要成分分析将数据压缩至1000个特征
- 然后对训练集运行学习算法
- 在预测时,采用之前学习而来的\(U_{reduce}\)将输入的特征\(x\)转换成特征向量\(z\),然后再进行预测
注:如果我们有交叉验证集和测试集,也采用对训练集学习而来的\(U_{reduce}\)。
错误的使用PCA的情况:
将其用于减少过拟合(减少了特征的数量)。这样做非常不好,不如尝试正则化处理。原因在于主要成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征。然而当我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。
默认地将主要成分分析作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始。只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析。
程序代码
直接查看Principle Component Analysis.ipynb可点击
获取源码以其他文件,可点击右上角 Fork me on GitHub 自行 Clone。
[C9] 降维(Dimensionality Reduction)的更多相关文章
- Stanford机器学习笔记-10. 降维(Dimensionality Reduction)
10. Dimensionality Reduction Content 10. Dimensionality Reduction 10.1 Motivation 10.1.1 Motivation ...
- 海量数据挖掘MMDS week4: 推荐系统之数据降维Dimensionality Reduction
http://blog.csdn.net/pipisorry/article/details/49231919 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 数据降维(Dimensionality reduction)
数据降维(Dimensionality reduction) 应用范围 无监督学习 图片压缩(需要的时候在还原回来) 数据压缩 数据可视化 数据压缩(Data Compression) 将高维的数据转 ...
- 机器学习(十)-------- 降维(Dimensionality Reduction)
降维(Dimensionality Reduction) 降维的目的:1 数据压缩 这个是二维降一维 三维降二维就是落在一个平面上. 2 数据可视化 降维的算法只负责减少维数,新产生的特征的意义就必须 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- 斯坦福第十四课:降维(Dimensionality Reduction)
14.1 动机一:数据压缩 14.2 动机二:数据可视化 14.3 主成分分析问题 14.4 主成分分析算法 14.5 选择主成分的数量 14.6 重建的压缩表示 14.7 主成分分析法 ...
- Ng第十四课:降维(Dimensionality Reduction)
14.1 动机一:数据压缩 14.2 动机二:数据可视化 14.3 主成分分析问题 14.4 主成分分析算法 14.5 选择主成分的数量 14.6 重建的压缩表示 14.7 主成分分析法 ...
- [UFLDL] Dimensionality Reduction
博客内容取材于:http://www.cnblogs.com/tornadomeet/archive/2012/06/24/2560261.html Deep learning:三十五(用NN实现数据 ...
- 第八章——降维(Dimensionality Reduction)
机器学习问题可能包含成百上千的特征.特征数量过多,不仅使得训练很耗时,而且难以找到解决方案.这一问题被称为维数灾难(curse of dimensionality).为简化问题,加速训练,就需要降维了 ...
随机推荐
- 2019-2020-1 20199305《Linux内核原理与分析》第五周作业
系统调用的三层机制(上) (一)用户态.内核态和中断 (1)Intel x86 CPU有4种不同的执行级别 分别是0.1.2.3,数字越小,特权越高.Linux操作系统中只是采用了其中的0和3两个特权 ...
- jQuery的延迟对象(十一)
在前端这个领域里面,ajax请求非常常见. // 前提引入jquery $.ajax({ type: 'get', url: '/path/to/data', success: function (r ...
- IDEA创建maven项目慢的不行
方法二 下载archetype-catalog.xml文件,在maven的VM Options加上-DarchetypeCatalog=local 默认情况下,创建maven项目是从网络下载catal ...
- okhttp浅析
转载自:http://www.ishenping.com/ArtInfo/69561.html 1.okhttp工作的大致流程 1.1.整体流程 (1).当我们通过OkhttpClient创建一个Ca ...
- ASP.NET(1)
1.IIS安装问题,先装VS再装IIS,处理程序映射有问题,使用VS自带的控制台输入命令,注册路径 2.开发模式,一般处理程序,使用IO操作读取html文件,使前后端分离 3.post请求和get请求 ...
- Python笔记:设计模式之命令模式
命令模式,正如模式的名字一样,该模式中的不同操作都可以当做不同的命令来执行,可以使用队列来执行一系列的命令,也可以单独执行某个命令.该模式重点是将不同的操作封装为不同的命令对象,将操作的调用者与执行者 ...
- 反射实体类拼接SQL语句
实体类基类: using System; using System.Collections.Generic; using System.Linq; using System.Reflection; u ...
- 易优CMS:小白学代码之notempty
[基础用法] 名称:notempty 功能:判断某个变量是否为空,可以嵌套到任何标签里面使用,比如:channel.type等 语法: {eyou:notempty name='$eyou.field ...
- LeetCode题解002:两数相加
两数相加 题目 给出两个 非空 的链表用来表示两个非负的整数.其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字 如果,我们将这两个数相加起来,则会返回一个新的链表 ...
- iOS 国际本地化(对新项目集成和已有项目集成)
第一推荐一篇金先生的博客,受益非浅,在这里真诚的感谢 https://www.jianshu.com/p/7cb0fad6d06f金小白 首先金小白先生把两种方式都做了介绍,第一种我就不在过多详细的讲 ...