深入集合类系列——HashMap和HashTable的区别
含义:HashMap是基于哈希表的Map接口的非同步实现。允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
数据结构:HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
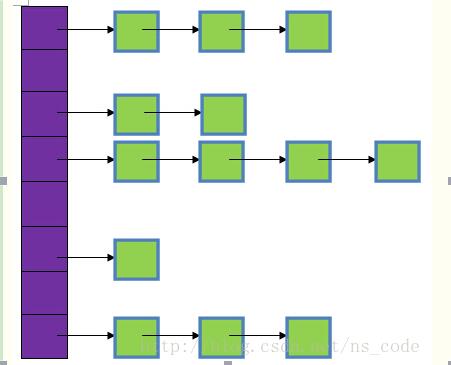
HashMap存数据的基本流程:
1、当调用put(key,value)时,首先获取key的hashcode,int hash = key.hashCode();
2、再把hash通过一下运算得到一个int h.
hash ^= (hash >>> 20) ^ (hash >>> 12);
int h = hash ^ (hash >>> 7) ^ (hash >>> 4);
为什么要经过这样的运算呢?这就是HashMap的高明之处。先看个例子,一个十进制数32768(二进制1000 0000 0000 0000),经过上述公式运算之后的结果是35080(二进制1000 1001 0000 1000)。看出来了吗?或许这样还看不出什么,再举个数字61440(二进制1111 0000 0000 0000),运算结果是65263(二进制1111 1110 1110 1111),现在应该很明显了,它的目的是让“1”变的均匀一点,散列的本意就是要尽量均匀分布。那这样有什么意义呢?看第3步。
3、得到h之后,把h与HashMap的承载量(HashMap的默认承载量length是16,可以自动变长。在构造HashMap的时候也可以指定一个长 度。这个承载量就是上图所描述的数组的长度。)进行逻辑与运算,即 h & (length-1),这样得到的结果就是一个比length小的正数,我们把这个值叫做index。其实这个index就是索引将要插入的值在数组中的 位置。第2步那个算法的意义就是希望能够得出均匀的index,这是HashTable的改进,HashTable中的算法只是把key的 hashcode与length相除取余,即hash % length,这样有可能会造成index分布不均匀。还有一点需要说明,HashMap的键可以为null,它的值是放在数组的第一个位置。
4、我们用table[index]表示已经找到的元素需要存储的位置。先判断该位置上有没有元素(这个元素是HashMap内部定义的一个类Entity, 基本结构它包含三个类,key,value和指向下一个Entity的next),没有的话就创建一个Entity对象,在 table[index]位置上插入,这样插入结束;如果有的话,通过链表的遍历方式去逐个遍历,看看有没有已经存在的key,有的话用新的value替 换老的value;如果没有,则在table[index]插入该Entity,把原来在table[index]位置上的Entity赋值给新的 Entity的next,这样插入结束。
流程总结:key->hashcode->h->index->遍历链表->插入
(1)int hash = key.hashCode();
(2)
hash ^= (hash >>> 20) ^ (hash >>> 12);
int h = hash ^ (hash >>> 7) ^ (hash >>> 4);
(3)h&(length-1)得到index
(4)遍历链表并插入
1、HashTable的实现原理(源代码)
含义:Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、Java.io.Serializable接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的。
它的key、value都不可以为null。
此外,Hashtable中的映射不是有序的。
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量:是哈希表中桶的数量,初始容量,就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
HashMap和HashTable的区别
(1)两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全
Hashtable的实现方法里面都添加了synchronized关键字来确保线程同步,因此相对而言HashMap性能会高一些,我们平时使用时若无特殊需求建议使用HashMap,在多线程环境下若使用HashMap需要使用Collections.synchronizedMap()方法来获取一个线程安全的集合。
(2)HashMap可以使用null作为key,而Hashtable则不允许null作为key,HashMap以null作为key时,总是存储在table数组的第一个节点上。
(3)HashMap是对Map接口的实现,HashTable实现了Map接口和Dictionary抽象类
(4)HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75
HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即:capacity*2+1。
(5)两者计算hash的方法不同
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸,key->hashcode->h->index->遍历链表->插入
(6)HashMap和Hashtable的底层实现都是数组+链表结构实现
深入集合类系列——HashMap和HashTable的区别的更多相关文章
- Java 集合系列 11 hashmap 和 hashtable 的区别
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- 面试题·HashMap和Hashtable的区别(转载再整理)
原文链接: Javarevisited 翻译: ImportNew.com- 唐小娟 译文链接: http://www.importnew.com/7010.html HashMap和Hashtabl ...
- HashMap和Hashtable的区别(转载)
转载声明:转载自原文http://www.importnew.com/7010.html HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是 ...
- HashMap与HashTable的区别?
HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以随机应变使用多种思路解决问题.HashMap的工作原理.ArrayList与Vect ...
- Java集合详解4:一文读懂HashMap和HashTable的区别以及常见面试题
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- java面试题——HashMap和Hashtable 的区别
一.HashMap 和Hashtable 的区别 我们先看2个类的定义 public class Hashtable extends Dictionary implements Map, Clonea ...
- Map集合及与Collection的区别、HashMap和HashTable的区别、Collections、
特点:将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值. Map集合和Collection集合的区别 Map集合:成对出现 (情侣) ...
- hashMap和hashTable的区别
每日总结,每天进步一点点 hashMap和hashTable的区别 1.父类:hashMap=>AbstractMap hashTable=>Dictionary 2.性能:hashMap ...
- java分享第七天-01(Hashmap和Hashtable的区别&Property)
一.Hashmap和Hashtable的区别 1 主要:Hashtable线程安全,同步,效率相对低下 HashMap线程不安全,非同步,效率相对高 2 父类:Hashtable是Dictionary ...
随机推荐
- mysql 实战
建表语句: CREATE TABLE employee ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(150) NOT NULL DEFAULT ...
- Docker资源管理
一台宿主机可以放多个容器,默认的情况下,Docker 没有对容器进行硬件资源的限制,当容器负载过高时会尽可能的占用宿主机资源,所以有时候我们需要对容器的资源使用设置一个上限,今天我们就来看看如何管理 ...
- Unity Shader 卡通渲染 基于退化四边形的实时描边
从csdn转移过来,顺便把写过的文章改写一下转过来. 一.边缘检测算法 3D模型描边有两种方式,一种是基于图像,即在所有3D模型渲染完成一张图片后,对这张图片进行边缘检测,最后得出描边效果.一种是基于 ...
- 迁移桌面程序到MS Store(10)——在Windows S Mode运行
首先简单介绍Windows 10 S Mode,Windows在该模式下,只能跑MS Store里的软件,不能通过其他方式安装.好处是安全有保障,杜绝一切国产流氓软件.就像iOS一样,APP进商店都需 ...
- 007 Linux系统优化进阶
一.更改 ssh 服务远程登录的配置 windows:默认远程端口和管理员用户 管理员:administrator port :3389 Linux:远程连接默认端口和超级用户 管理员:root ...
- 利用poi包装一个简单的Excel读取器.一(适配一个Reader并提供readLine方法)
通常,读文本我们会使用BufferedReader,它装饰或者说管理了InputStreamReader,同时提供readLine()简化了我们对文本行的读取.就像从流水线上获取产品一样,每当取完一件 ...
- JMeter简介及使用JMeter来访问网站
参考: http://jmeter.apache.org/ http://blog.chinaunix.net/uid-26884465-id-3416869.html http://www.ltes ...
- Codeforces Round #486 (Div. 3)988D. Points and Powers of Two
传送门:http://codeforces.com/contest/988/problem/D 题意: 在一堆数字中,找出尽量多的数字,使得这些数字的差都是2的指数次. 思路: 可以知道最多有三个,差 ...
- codeforces 459 E. Pashmak and Graph(dp)
题目链接:http://codeforces.com/contest/459/problem/E 题意:给出m条边n个点每条边都有权值问如果两边能够相连的条件是边权值是严格递增的话,最长能接几条边. ...
- c博客作业00--我的第一篇博客
1.你对网络专业或计算机专业了解是怎样? 一开始以为计算机网络专业就是搞跟计算机有关的东西,后来查了网络才知道,网络专业主要学计算机科学基础理论软硬件系统及应用知识 .网络工程的专业及应用知识. 2. ...