[spark程序]统计人口平均年龄(HDFS文件)(详细过程)
一、题目描述
(1)请编写Spark应用程序,该程序可以在分布式文件系统HDFS中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包含两列数据,第1列是序号,第2列是年龄。效果如下:
1 89
2 67
3 69
4 78
(2)请编写Spark应用程序,对分布式文件系统HDFS中的数据文件peopleage.txt的数据进行处理,计算出所有人口的平均年龄。
二、实现
1、在分布式文件系统HDFS中生成一个数据文件peopleage.txt
1)启动hadoop
start-dfs.sh
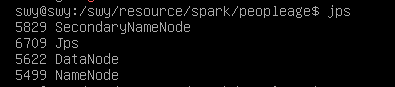
2)在HDFS中创建程序存放目录
hdfs dfs -mkdir -p /swy/resource/peopleage
3)编辑生成peopleage.txt的程序GeneratePeopleAgeHDFS.scala

代码:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import scala.util.Random object GeneratePeopleAgeHDFS {
def main(args: Array[String]) {
val outFile = "hdfs://localhost:9000/swy/resource/peopleage/peopleage.txt"
val conf = new SparkConf().setAppName("GeneratePeopleAgeHDFS").setMaster("local[2]")
val sc = new SparkContext(conf)
val rand = new Random()
val array = new Array[String](1000)
for(i <- 1 to 1000) {
array(i-1) = i +" "+ rand.nextInt(100)
}
val rdd = sc.parallelize(array)
rdd.foreach(println)
rdd.saveAsTextFile(outFile)
}
}
4)打包运行


5)可以看到HDFS中已经有了peopleage.txt文件
查看:
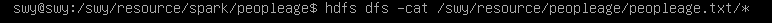
2、计算平均年龄
使用前面 创建的CountAvgage.scala文件
运行:

结果:

原文:http://dblab.xmu.edu.cn/blog/1756-2/
[spark程序]统计人口平均年龄(HDFS文件)(详细过程)的更多相关文章
- [spark程序]统计人口平均年龄(本地文件)(详细过程)
一.题目描述 (1)编写Spark应用程序,该程序可以在本地文件系统中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包含两列数据, ...
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- 记录一次用宝塔部署微信小程序Node.js后端接口代码的详细过程
一直忙着写毕设,上一次写博客还是元旦,大半年过去了.... 后面会不断分享各种新项目的源码与技术.欢迎关注一起学习哈! 记录一次部署微信小程序Node.js后端接口代码的详细过程,使用宝塔来部署. 我 ...
- Spark设置自定义的InputFormat读取HDFS文件
本文通过MetaWeblog自动发布,原文及更新链接:https://extendswind.top/posts/technical/problem_spark_reading_hdfs_serial ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
- HDFS文件读写过程
参考自<Hadoop权威指南> [http://www.cnblogs.com/swanspouse/p/5137308.html] HDFS读文件过程: 客户端通过调用FileSyste ...
- JNI初级:android studio生成so文件详细过程
本文主要参考blog:http://blog.csdn.net/jkan2001/article/details/54316375 下面是本人结合blog生成so包过程中遇到一些问题和解决方法 (1) ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- hdfs读写删除过程解析
一.hdfs文件读取过程 hdfs有一个FileSystem实例,客户端通过调用这个实例的open()方法就可以打开系统中希望读取的文件,hdfs通过rpc协议调用Nadmenode获取block的位 ...
随机推荐
- Web安全之注入点构造
在测试过程中,经常需要自己本地构造注入点来进行SQL测试,这边分享一下,不同环境下构造SQL注入的代码. PHP+MYSQL版 <?php $con = mysql_connect(" ...
- PHP绕过disable_function限制(一)
测试环境 php 5.4.5 0x01 利用系统组件绕过 1.window com组件(php 5.4)(高版本扩展要自己添加) (COM组件它最早的设计意图是,跨语言实现程序组件的复用.) 测试: ...
- 后门木马免杀-msfvenom和msf5(evasion)
贴上使用笔记 不多介绍了 很简单的东西 msfvenom各平台生成木马大全: windows:msfvenom -a x86 --platform Windows -p windows/meterpr ...
- PHP call_user_func的一些用法和注意点
版本:PHP 5.6.28 在call_user_func的调用中: 1.参数的传递过程,并不是引用传值. 1 error_reporting(E_ERROR); // 此处不是E_ALL 2 $cu ...
- Intel Ivy Bridge Microarchitecture Events
This is a list of all Intel Ivy Bridge Microarchitecture performance counter event types. Please see ...
- 记录一次gdb debug经历
目录 问题描述 查看core文件 使用gdb查看core文件 总结 问题描述 今天在写代码时,运行时奔溃了.segment fault,而且是在程序退出main()函数后,才报的. 唯一的信息是:Se ...
- Rust入坑指南:千人千构
坑越来越深了,在坑里的同学让我看到你们的双手! 前面我们聊过了Rust最基本的几种数据类型.不知道你还记不记得,如果不记得可以先复习一下.上一个坑挖好以后,有同学私信我说坑太深了,下来的时候差点崴了脚 ...
- Leetcode(3)无重复字符的最长子串
Leetcode(3)无重复字符的最长子串 [题目表述]: 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度. 第一种方法:暴力 执行用时:996 ms: 内存消耗:12.9MB 效果: ...
- Android9.0 如何区分SDK接口和非 SDK接口
刚刚有同学问我,不太了解 "非SDK接口" 是什么意思?android9.0有什么限制 ?apache的http也有限制 ? 而且现在的大部分系统都升级上来了,黑名单.灰名单和白名 ...
- video1
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...