[spark程序]统计人口平均年龄(本地文件)(详细过程)
一、题目描述
(1)编写Spark应用程序,该程序可以在本地文件系统中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包含两列数据,第1列是序号,第2列是年龄。效果如下:
1 89
2 67
3 69
4 78
(2)编写Spark应用程序,对本地文件系统中的数据文件peopleage.txt的数据进行处理,计算出所有人口的平均年龄。
二、实现
1、生成数据文件peopleage.txt
1)创建程序的目录结构
创建一个存放代码的目录,进入目录下创建一个目录用来保存该题目所有文件(/swy/resource/spark/peopleage)
在peopleage目录下建立src/main/scala代码目录,专门用来保存scala代码文件,命令如下:

2)生成数据文件peopleage.txt的代码
创建一个代码文件GeneratePeopleAge.scala,用来生成数据文件peopleage.txt,命令如下:


代码如下:
import java.io.FileWriter
import java.io.File
import scala.util.Random object GeneratePeopleAge{ def main(args:Array[String]){
val fileWriter = new FileWriter(new File("/swy/resource/spark/peopleage/peopleage.txt"),false)
val rand = new Random()
for (i <- 1 to 1000){
fileWriter.write(i+" "+rand.nextInt(100))
fileWriter.write(System.getProperty("line.separator"))
}
fileWriter.flush()
fileWriter.close()
}
}
3)sbt打包
退回到people目录下:

输入如下:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
输入命令打包:
sbt package
打包成功:

4)运行文件,生成peopleage.txt

可以看到目录下已经生成peopleage.txt,查看文件:

2、计算所有人口的平均年龄
1)创建CountAvgage.scala

2)代码
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object CountAvgAge {
def main(args:Array[String]) {
if (args.length < 1) {
println("Usage: CountAvgAge inputdatafile")
System.exit(1)
}
val conf = new SparkConf().setAppName("Count average age")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0),3)
val peopleNum =lines.count()
val totalAge = lines.map(line => line.split(" ")(1)).map(t => t.trim.toInt).collect().reduce((a,b) => a+b)
println("Total Age is: " +totalAge+ "; Number of People is: " +peopleNum)
val avgAge : Double = totalAge.toDouble / peopleNum.toDouble
println("Average Age is: " +avgAge)
}
}
3)打包
退回people文件夹,输入命令打包:

4)运行程序
输入如下命令:

结果:
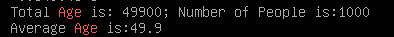
原文:http://dblab.xmu.edu.cn/blog/1756-2/
[spark程序]统计人口平均年龄(本地文件)(详细过程)的更多相关文章
- [spark程序]统计人口平均年龄(HDFS文件)(详细过程)
一.题目描述 (1)请编写Spark应用程序,该程序可以在分布式文件系统HDFS中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包 ...
- 记录一次用宝塔部署微信小程序Node.js后端接口代码的详细过程
一直忙着写毕设,上一次写博客还是元旦,大半年过去了.... 后面会不断分享各种新项目的源码与技术.欢迎关注一起学习哈! 记录一次部署微信小程序Node.js后端接口代码的详细过程,使用宝塔来部署. 我 ...
- R语言—统计结果输出至本地文件方法总结
1.sink()在代码开始前加一行:sink(“output.txt”),就会自动把结果全部输出到工作文件夹下的output.txt文本文档.这时在R控制台的输出窗口中是看不到输出结果的.代码结束时用 ...
- JNI初级:android studio生成so文件详细过程
本文主要参考blog:http://blog.csdn.net/jkan2001/article/details/54316375 下面是本人结合blog生成so包过程中遇到一些问题和解决方法 (1) ...
- Spark保存到HDFS或本地文件相关问题
spark中saveAsTextFile如何最终生成一个文件 http://www.lxway.com/641062624.htm 一般而言,saveAsTextFile会按照执行task的多少生成多 ...
- 5、创建RDD(集合、本地文件、HDFS文件)
一.创建RDD 1.创建RDD 进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD.该RDD中,通常就代表和包含了Spark应用程序的输入源数据.然后在创建了初始的RDD之后,才可 ...
- Spark程序本地运行
Spark程序本地运行 本次安装是在JDK安装完成的基础上进行的! SPARK版本和hadoop版本必须对应!!! spark是基于hadoop运算的,两者有依赖关系,见下图: 前言: 1.环境 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- spark本地环境的搭建到运行第一个spark程序
搭建spark本地环境 搭建Java环境 (1)到官网下载JDK 官网链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8- ...
随机推荐
- 三维动画形变算法(Mixed Finite Elements)
混合有限元方法通入引入辅助变量后可以将高阶微分问题变成一系列低阶微分问题的组合.在三维网格形变问题中,我们考虑如下泛函极值问题: 其中u: Ω0 → R3是变形体的空间坐标,上述泛函极值问题对应的欧拉 ...
- kubectl get 后按2次tab键命令补全的失效原因分析
kubectl get 后按2次tab键命令补全的失效原因分析 2019/10/28 Chenxin a.bash客户端工具 在centos用户下, cd ~;echo "source &l ...
- < Window10更新后VWwareWorkstationPro无法运行(显示更新至新版本) >
< Window10更新后VWwareWorkstationPro无法运行(显示更新至新版本) > 问题描述 我的Win10在国庆节后更新了微软发布的新补丁,由于当前正在上操作系统课,用到 ...
- 关闭ESlint 语法检测配置方法
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qappleh/article/detai ...
- Nginx专题(1):Nginx之反向代理及配置
摘要:本文从Nginx的概念出发,分别从反向代理的概念.优势.配置代码3个方面介绍了Nginx的特性之一反向代理. 文章来源:宜信技术学院 & 宜信支付结算团队技术分享第一期-宜信支付结算八方 ...
- 哪种方式更适合在React中获取数据?
作者:Dmitri Pavlutin 译者:小维FE 原文:dmitripavlutin.com 国外文章,笔者采用意译的方式,以保证文章的可读性. 当执行像数据获取这样的I/O操作时,你必须发起获取 ...
- NLP预训练模型-百度ERNIE2.0的效果到底有多好【附用户点评】
ERNIE是百度自研的持续学习语义理解框架,该框架支持增量引入词汇(lexical).语法 (syntactic) .语义(semantic)等3个层次的自定义预训练任务,能够全面捕捉训练语料中的词法 ...
- python的位置参数、关键字参数、收集参数,关键字收集参数混合调用问题
参数混合调用顺序用法: 函数中参数顺序为:普通参数,收集参数,关键字参数,关键字收集参数,其顺序不能颠倒,颠倒会报错. 普通参数.关键字参数可以有n个,对量没有具体要求,收集参数和关键字收集参数要么没 ...
- windows 利用环境变量%PATH%中目录可写提权
使用PowerUp的时候有时候会有这种结果 [*] Checking %PATH% for potentially hijackable DLL locations... Permissions : ...
- NOIP模拟 16
嗯我已经是个不折不扣的大辣鸡了 上次的T3就弃了,这次又弃 颓废到天际 T1 巨贪贪心算法 我就是一个只会背板子的大辣鸡 全裸的贪心看不出来,只会打板子 打板子,加特判,然后一无进展,原题不会,这就是 ...