通俗地说决策树算法(三)sklearn决策树实战
前情提要
上面两篇介绍了那么多决策树的知识,现在也是时候来实践一下了。Python有一个著名的机器学习框架,叫sklearn。我们可以用sklearn来运行前面说到的赖床的例子。不过在这之前,我们需要介绍一下sklearn中训练一颗决策树的具体参数。
另外sklearn中训练决策树的默认算法是CART,使用CART决策树的好处是可以用它来进行回归和分类处理,不过这里我们只进行分类处理。
一. sklearn决策树参数详解
我们都知道,一个模型中很重要的一步是调参。在sklearn中,模型的参数是通过方法参数来决定的,以下给出sklearn中,决策树的参数:
DecisionTreeClassifier(criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
class_weight=None,
presort=False)
参数含义:
1.criterion:string, optional (default="gini")
(1).criterion='gini',分裂节点时评价准则是Gini指数。
(2).criterion='entropy',分裂节点时的评价指标是信息增益。
2.max_depth:int or None, optional (default=None)。指定树的最大深度。
如果为None,表示树的深度不限。直到所有的叶子节点都是纯净的,即叶子节点
中所有的样本点都属于同一个类别。或者每个叶子节点包含的样本数小于min_samples_split。
3.splitter:string, optional (default="best")。指定分裂节点时的策略。
(1).splitter='best',表示选择最优的分裂策略。
(2).splitter='random',表示选择最好的随机切分策略。
4.min_samples_split:int, float, optional (default=2)。表示分裂一个内部节点需要的做少样本数。
(1).如果为整数,则min_samples_split就是最少样本数。
(2).如果为浮点数(0到1之间),则每次分裂最少样本数为ceil(min_samples_split * n_samples)
5.min_samples_leaf: int, float, optional (default=1)。指定每个叶子节点需要的最少样本数。
(1).如果为整数,则min_samples_split就是最少样本数。
(2).如果为浮点数(0到1之间),则每个叶子节点最少样本数为ceil(min_samples_leaf * n_samples)
6.min_weight_fraction_leaf:float, optional (default=0.)
指定叶子节点中样本的最小权重。
7.max_features:int, float, string or None, optional (default=None).
搜寻最佳划分的时候考虑的特征数量。
(1).如果为整数,每次分裂只考虑max_features个特征。
(2).如果为浮点数(0到1之间),每次切分只考虑int(max_features * n_features)个特征。
(3).如果为'auto'或者'sqrt',则每次切分只考虑sqrt(n_features)个特征
(4).如果为'log2',则每次切分只考虑log2(n_features)个特征。
(5).如果为None,则每次切分考虑n_features个特征。
(6).如果已经考虑了max_features个特征,但还是没有找到一个有效的切分,那么还会继续寻找
下一个特征,直到找到一个有效的切分为止。
8.random_state:int, RandomState instance or None, optional (default=None)
(1).如果为整数,则它指定了随机数生成器的种子。
(2).如果为RandomState实例,则指定了随机数生成器。
(3).如果为None,则使用默认的随机数生成器。
9.max_leaf_nodes: int or None, optional (default=None)。指定了叶子节点的最大数量。
(1).如果为None,叶子节点数量不限。
(2).如果为整数,则max_depth被忽略。
10.min_impurity_decrease:float, optional (default=0.)
如果节点的分裂导致不纯度的减少(分裂后样本比分裂前更加纯净)大于或等于min_impurity_decrease,则分裂该节点。
加权不纯度的减少量计算公式为:
min_impurity_decrease=N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)
其中N是样本的总数,N_t是当前节点的样本数,N_t_L是分裂后左子节点的样本数,
N_t_R是分裂后右子节点的样本数。impurity指当前节点的基尼指数,right_impurity指
分裂后右子节点的基尼指数。left_impurity指分裂后左子节点的基尼指数。
11.min_impurity_split:float
树生长过程中早停止的阈值。如果当前节点的不纯度高于阈值,节点将分裂,否则它是叶子节点。
这个参数已经被弃用。用min_impurity_decrease代替了min_impurity_split。
12.class_weight:dict, list of dicts, "balanced" or None, default=None
类别权重的形式为{class_label: weight}
(1).如果没有给出每个类别的权重,则每个类别的权重都为1。
(2).如果class_weight='balanced',则分类的权重与样本中每个类别出现的频率成反比。
计算公式为:n_samples / (n_classes * np.bincount(y))
(3).如果sample_weight提供了样本权重(由fit方法提供),则这些权重都会乘以sample_weight。
13.presort:bool, optional (default=False)
指定是否需要提前排序数据从而加速训练中寻找最优切分的过程。设置为True时,对于大数据集
会减慢总体的训练过程;但是对于一个小数据集或者设定了最大深度的情况下,会加速训练过程。
虽然看起来参数众多,但通常参数都会有默认值,我们只需要调整其中较为重要的几个参数就行。
通常来说,较为重要的参数有:
- criterion:用以设置用信息熵还是基尼系数计算。
- splitter:指定分支模式
- max_depth:最大深度,防止过拟合
- min_samples_leaf:限定每个节点分枝后子节点至少有多少个数据,否则就不分枝
二. sklearn决策树实战
2.1 准备数据及读取
数据就是上次说到的赖床特征,
| 季节 | 时间已过 8 点 | 风力情况 | 要不要赖床 |
|---|---|---|---|
| spring | no | breeze | yes |
| winter | no | no wind | yes |
| autumn | yes | breeze | yes |
| winter | no | no wind | yes |
| summer | no | breeze | yes |
| winter | yes | breeze | yes |
| winter | no | gale | yes |
| winter | no | no wind | yes |
| spring | yes | no wind | no |
| summer | yes | gale | no |
| summer | no | gale | no |
| autumn | yes | breeze | no |
将它存储成 csv 文件
spring,no,breeze,yes
winter,no,no wind,yes
autumn,yes,breeze,yes
winter,no,no wind,yes
summer,no,breeze,yes
winter,yes,breeze,yes
winter,no,gale,yes
winter,no,no wind,yes
spring,yes,no wind,no
summer,yes,gale,no
summer,no,gale,no
autumn,yes,breeze,no
2.2 决策树的特征向量化DictVectorizer
sklearn的DictVectorizer能对字典进行向量化。什么叫向量化呢?比如说你有季节这个属性有[春,夏,秋,冬]四个可选值,那么如果是春季,就可以用[1,0,0,0]表示,夏季就可以用[0,1,0,0]表示。不过在调用DictVectorizer它会将这些属性打乱,不会按照我们的思路来运行,但我们也可以一个方法查看,我们看看代码就明白了。
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn.model_selection import train_test_split
#pandas 读取 csv 文件,header = None 表示不将首行作为列
data = pd.read_csv('data/laic.csv',header =None)
#指定列
data.columns = ['season','after 8','wind','lay bed']
#sparse=False意思是不产生稀疏矩阵
vec=DictVectorizer(sparse=False)
#先用 pandas 对每行生成字典,然后进行向量化
feature = data[['season','after 8','wind']]
X_train = vec.fit_transform(feature.to_dict(orient='record'))
#打印各个变量
print('show feature\n',feature)
print('show vector\n',X_train)
print('show vector name\n',vec.get_feature_names())
我们来看看打印的结果:
show feature
season after 8 wind
0 spring no breeze
1 winter no no wind
2 autumn yes breeze
3 winter no no wind
4 summer no breeze
5 winter yes breeze
6 winter no gale
7 winter no no wind
8 spring yes no wind
9 summer yes gale
10 summer no gale
11 autumn yes breeze
show vector
[[1. 0. 0. 1. 0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0. 1. 0. 0. 1.]
[0. 1. 1. 0. 0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 0. 1. 0. 1. 0. 0.]
[0. 1. 0. 0. 0. 1. 1. 0. 0.]
[1. 0. 0. 0. 0. 1. 0. 1. 0.]
[1. 0. 0. 0. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 0. 0. 1. 0.]
[0. 1. 1. 0. 0. 0. 1. 0. 0.]]
show vector name
['after 8=no', 'after 8=yes', 'season=autumn', 'season=spring', 'season=summer', 'season=winter', 'wind=breeze', 'wind=gale', 'wind=no wind']
通过DictVectorizer,我们就能够把字符型的数据,转化成0 1的矩阵,方便后面进行运算。额外说一句,这种转换方式其实就是one-hot编码。
2.4 决策树训练
可以发现在向量化的时候,属性都被打乱了,但我们也可以通过get_feature_names()这个方法查看对应的属性值。有了数据后,就可以来训练一颗决策树了,用sklearn很方便,只需要很少的代码
#划分成训练集,交叉集,验证集,不过这里我们数据量不够大,没必要
#train_x, test_x, train_y, test_y = train_test_split(X_train, Y_train, test_size = 0.3)
#训练决策树
clf = tree.DecisionTreeClassifier(criterion='gini')
clf.fit(X_train,Y_train)
#保存成 dot 文件,后面可以用 dot out.dot -T pdf -o out.pdf 转换成图片
with open("out.dot", 'w') as f :
f = tree.export_graphviz(clf, out_file = f,
feature_names = vec.get_feature_names())
2.5 决策树可视化
当完成一棵树的训练的时候,我们也可以让它可视化展示出来,不过sklearn没有提供这种功能,它仅仅能够让训练的模型保存到dot文件中。但我们可以借助其他工具让模型可视化,先看保存到dot的代码:
from sklearn import tree
with open("out.dot", 'w') as f :
f = tree.export_graphviz(clf, out_file = f,
feature_names = vec.get_feature_names())
决策树可视化我们用Graphviz这个东西。当然需要先用pip安装对应的库类。然后再去官网下载它的一个发行版本,用以将dot文件转化成pdf图片。
官网下载方式如下:

然后进入到上面保存好的dot所在目录,打开cmd运行dot out.dot -T pdf -o out.pdf 命令,pdf 图片就会出现了。
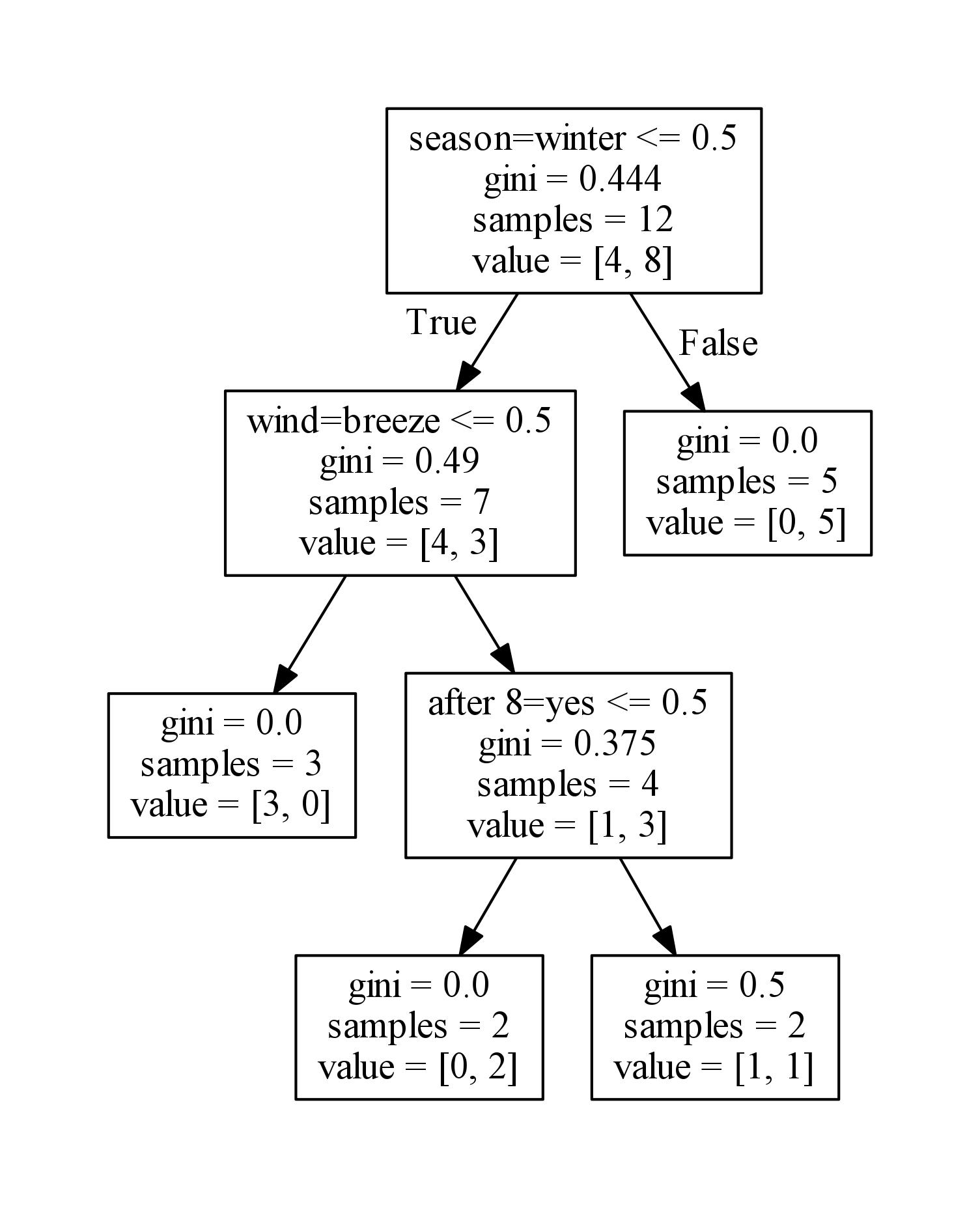
小结:
今天我们介绍了sklearn,决策树模型的各个参数,并且使用sklearn模型对上一节中的例子训练出一个决策树模型,然后用Graphviz让决策树模型可视化。到此,决策树算法算是讲完啦。
以上
通俗地说决策树算法(三)sklearn决策树实战的更多相关文章
- 【sklearn决策树算法】DecisionTreeClassifier(API)的使用以及决策树代码实例 - 鸢尾花分类
决策树算法 决策树算法主要有ID3, C4.5, CART这三种. ID3算法从树的根节点开始,总是选择信息增益最大的特征,对此特征施加判断条件建立子节点,递归进行,直到信息增益很小或者没有特征时结束 ...
- sklearn实现决策树算法
1.决策树算法是一种非参数的决策算法,它根据数据的不同特征进行多层次的分类和判断,最终决策出所需要预测的结果.它既可以解决分类算法,也可以解决回归问题,具有很好的解释能力.另外,对于决策树的构建方法具 ...
- 机器学习Sklearn系列:(三)决策树
决策树 熵的定义 如果一个随机变量X的可能取值为X={x1,x2,..,xk},其概率分布为P(X=x)=pi(i=1,2,...,n),则随机变量X的熵定义为\(H(x) = -\sum{p(x)l ...
- scikit-learn决策树算法类库使用小结
之前对决策树的算法原理做了总结,包括决策树算法原理(上)和决策树算法原理(下).今天就从实践的角度来介绍决策树算法,主要是讲解使用scikit-learn来跑决策树算法,结果的可视化以及一些参数调参的 ...
- day-8 python自带库实现ID3决策树算法
前一天,我们基于sklearn科学库实现了ID3的决策树程序,本文将基于python自带库实现ID3决策树算法. 一.代码涉及基本知识 1. 为了绘图方便,引入了一个第三方treePlotter模块进 ...
- 决策树算法的Python实现—基于金融场景实操
决策树是最经常使用的数据挖掘算法,本次分享jacky带你深入浅出,走进决策树的世界 基本概念 决策树(Decision Tree) 它通过对训练样本的学习,并建立分类规则,然后依据分类规则,对新样本数 ...
- Kaggle竞赛入门:决策树算法的Python实现
本文翻译自kaggle learn,也就是kaggle官方最快入门kaggle竞赛的教程,强调python编程实践和数学思想(而没有涉及数学细节),笔者在不影响算法和程序理解的基础上删除了一些不必要的 ...
- 4-Spark高级数据分析-第四章 用决策树算法预测森林植被
预测是非常困难的,更别提预测未来. 4.1 回归简介 随着现代机器学习和数据科学的出现,我们依旧把从“某些值”预测“另外某个值”的思想称为回归.回归是预测一个数值型数量,比如大小.收入和温度,而分类则 ...
- 就是要你明白机器学习系列--决策树算法之悲观剪枝算法(PEP)
前言 在机器学习经典算法中,决策树算法的重要性想必大家都是知道的.不管是ID3算法还是比如C4.5算法等等,都面临一个问题,就是通过直接生成的完全决策树对于训练样本来说是“过度拟合”的,说白了是太精确 ...
随机推荐
- Programming In Lua 第一章
1,Lua可以嵌入其他应用程序(如CGILua或IUPLua). 2,lua代码的语句,分号是可以省略的.同一行可以有多条lua语句,最好用分号隔开(当然也可以不隔开) 3,外壳与lua解释器的区别. ...
- 2. 2.1查找命令——linux基础增强,Linux命令学习
2.1.查找命令 grep命令 grep 命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并 把匹配的行打印出来. 格式: grep [option] pattern [file] 可使用 ...
- 如何查看jsplumb.js的API文档(YUIdoc的基本使用)
目录 一.问题描述 二. 处理方法 三. YUIdoc工具介绍 示例代码托管在:http://www.github.com/dashnowords/blogs 博客园地址:<大史住在大前端> ...
- CSU 1320:Scoop water(卡特兰数)
http://acm.csu.edu.cn/OnlineJudge/problem.php?id=1320 题意:……是舀的时候里面必须要有1L,而不是舀完必须要有1L. 思路:才知道是卡特兰数. 这 ...
- LightGBM,面试会问到的都在这了(附代码)!
1. LightGBM是什么东东 不久前微软DMTK(分布式机器学习工具包)团队在GitHub上开源了性能超越其他boosting工具的LightGBM,在三天之内GitHub上被star了1000次 ...
- 基于Django框架 CRM的增删改查
思路: 创建表------从数据库读出数据展示出来------配置路由-----写视图函数------写对应页面 练习点: 数据库建表 ORM 数据库数据读取 数据 ModelForm (form组 ...
- hdfs文件写入kafka集群
1. 场景描述 因新增Kafka集群,需要将hdfs文件写入到新增的Kafka集群中,后来发现文件不多,就直接下载文件到本地,通过Main函数写入了,假如需要部署到服务器上执行,需将文件读取这块稍做修 ...
- ~~Python解释器安装教程及环境变量配置~~
进击のpython Python解释器安装教程以及环境变量配置 对于一个程序员来说,能够自己配置python解释器是最基础的技能 那么问题来了,现在市面上有两种Python版本 Python 2.x ...
- Java 新特性总结——简单实用
lambda表达式 简介 lambda 表达式的语法 变量作用域 函数式接口 内置函数式接口 默认方法 Stream(流) 创建 stream Filter(过滤) Sorted(排序) Map(映射 ...
- list和list<map<String,object>>比较,不存在map的key赋值
package com; import java.math.BigDecimal; import java.text.ParseException; import java.text.SimpleDa ...