【sklearn决策树算法】DecisionTreeClassifier(API)的使用以及决策树代码实例 - 鸢尾花分类
决策树算法
决策树算法主要有ID3, C4.5, CART这三种。
ID3算法从树的根节点开始,总是选择信息增益最大的特征,对此特征施加判断条件建立子节点,递归进行,直到信息增益很小或者没有特征时结束。
信息增益:特征 A 对于某一训练集 D 的信息增益 \(g(D, A)\) 定义为集合 D 的熵 \(H(D)\) 与特征 A 在给定条件下 D 的熵 \(H(D/A)\) 之差。
熵(Entropy)是表示随机变量不确定性的度量。
\]
C4.5是使用了信息增益比来选择特征,这被看成是 ID3 算法的一种改进。
但这两种算法都会导致过拟合的问题,需要进行剪枝。
决策树的修剪,其实就是通过优化损失函数来去掉不必要的一些分类特征,降低模型的整体复杂度。
CART 算法在生成树的过程中,分类树采用了基尼指数(Gini Index)最小化原则,而回归树选择了平方损失函数最小化原则。
CART 算法也包含了树的修剪,CART 算法从完全生长的决策树底端剪去一些子树,使得模型更加简单。
具体代码实现上,scikit-learn 提供的 DecisionTreeClassifier 类可以做多分类任务。
1. DecisionTreeClassifier API 的使用
和其他分类器一样,DecisionTreeClassifier 需要两个数组作为输入:
X: 训练数据,稀疏或稠密矩阵,大小为 [n_samples, n_features]
Y: 类别标签,整型数组,大小为 [n_samples]
from sklearn import tree
X = [[0, 0], [1, 1]]
Y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
模型拟合后,可以用于预测样本的分类
clf.predict([[2., 2.]])
array([1])
此外,可以预测样本属于每个分类(叶节点)的概率,(输出结果:0%,100%)
clf.predict_proba([[2., 2.]])
array([[0., 1.]])
DecisionTreeClassifier() 模型方法中也包含非常多的参数值。例如:
criterion = gini/entropy可以用来选择用基尼指数或者熵来做损失函数。splitter = best/random用来确定每个节点的分裂策略。支持 “最佳” 或者“随机”。max_depth = int用来控制决策树的最大深度,防止模型出现过拟合。min_samples_leaf = int用来设置叶节点上的最少样本数量,用于对树进行修剪。
2. 由鸢尾花数据集构建决策树
鸢尾花数据集:
数据集名称的准确名称为 Iris Data Set,总共包含 150 行数据。每一行数据由 4 个特征值及一个目标值组成。
其中 4 个特征值分别为:萼片长度、萼片宽度、花瓣长度、花瓣宽度。
而目标值为三种不同类别的鸢尾花,分别为:Iris Setosa,Iris Versicolour,Iris Virginica。
DecisionTreeClassifier 既可以用于二分类,也可以用于多分类。
对于鸢尾花数据集,可以如下构建决策树:
from sklearn.datasets import load_iris
from sklearn import tree
X, y = load_iris(return_X_y=True)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
2.1 简单绘制决策树
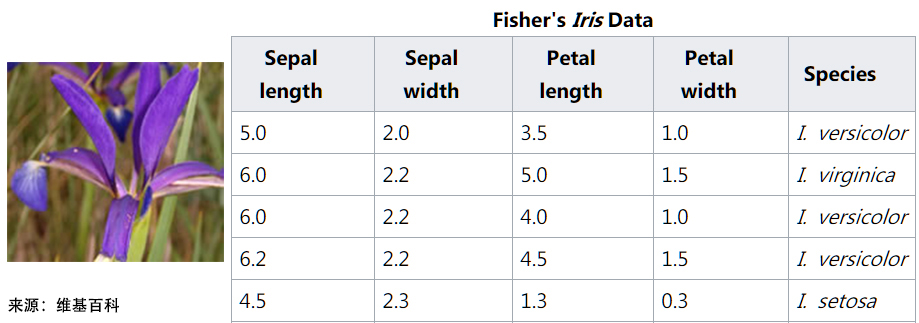
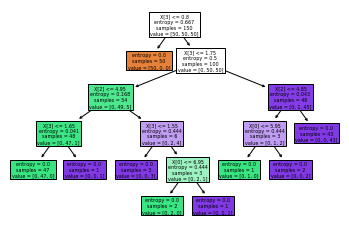
拟合完后,可以用plot_tree()方法绘制出决策树来,如下图所示
tree.plot_tree(clf)
2.2 Graphviz形式输出决策树
也可以用 Graphviz 格式(export_graphviz)输出。
如果使用的是 conda 包管理器,可以用如下方式安装:
conda install python-graphviz
pip install graphviz
以下展示了用 Graphviz 输出上述从鸢尾花数据集得到的决策树,结果保存为 iris.pdf
import graphviz
iris = load_iris()
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("iris")
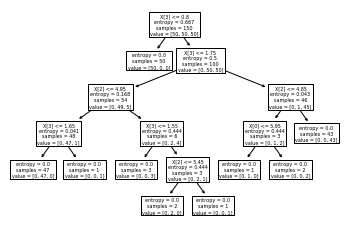
export_graphviz 支持使用参数进行视觉优化,包括根据分类或者回归值绘制彩色的结点,也可以使用显式的变量或者类名。
Jupyter Notebook 还可以自动内联呈现这些绘图。
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
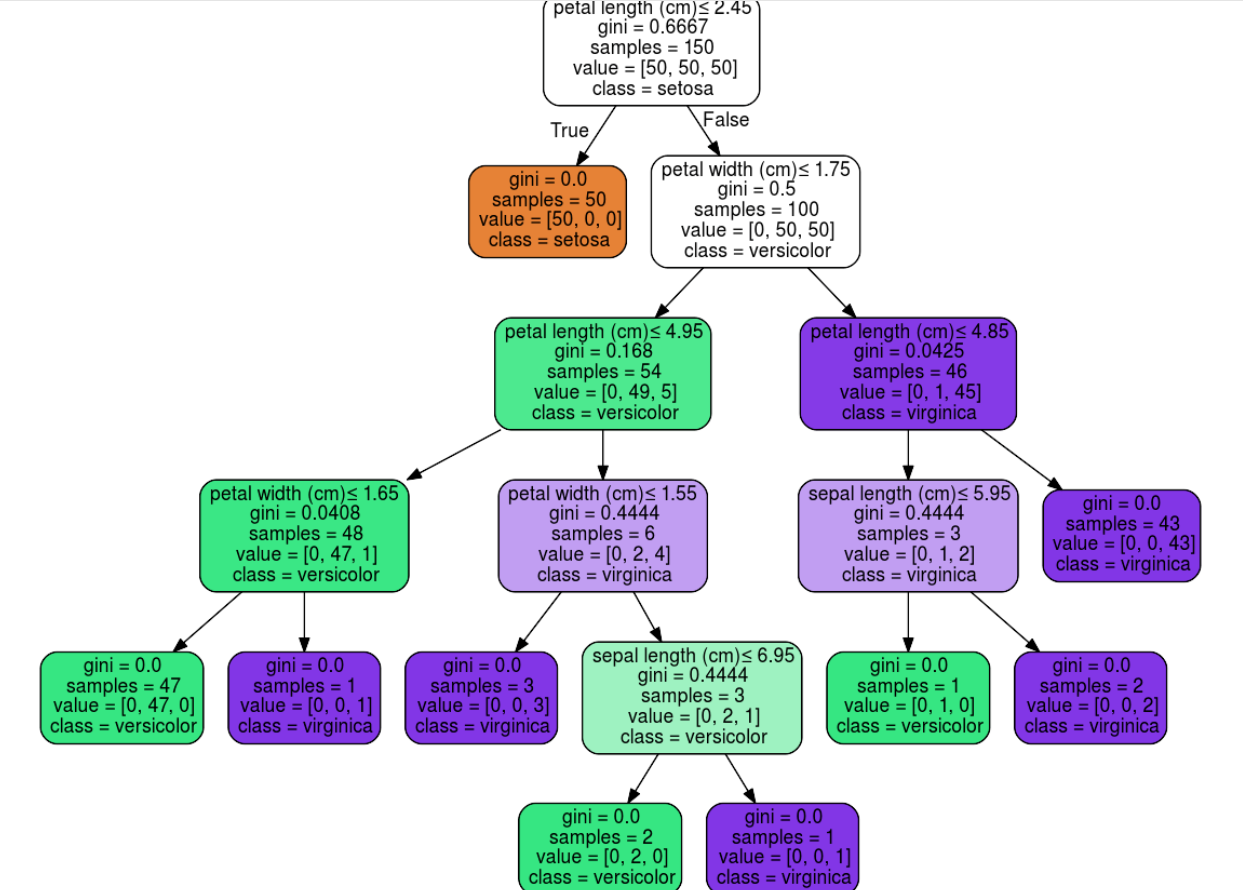
2.3 文本形式输出决策树
此外,决策树也可以使用 export_text 方法以文本形式输出,这个方法不需要安装其他包,也更加的简洁。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree.export import export_text
iris = load_iris()
decision_tree = DecisionTreeClassifier(random_state=0, max_depth=2)
decision_tree = decision_tree.fit(iris.data, iris.target)
r = export_text(decision_tree, feature_names=iris['feature_names'])
print(r)
|--- petal width (cm) <= 0.80
| |--- class: 0
|--- petal width (cm) > 0.80
| |--- petal width (cm) <= 1.75
| | |--- class: 1
| |--- petal width (cm) > 1.75
| | |--- class: 2
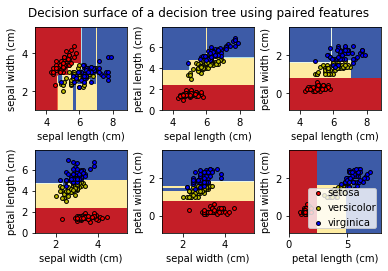
3. 绘制决策平面
绘制由特征对构成的决策平面,决策边界由训练集得到的简单阈值组成。
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
# Parameters
n_classes = 3
plot_colors = "ryb"
plot_step = 0.02
# Load data
iris = load_iris()
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3],
[1, 2], [1, 3], [2, 3]]):
# We only take the two corresponding features
X = iris.data[:, pair]
y = iris.target
# Train
clf = DecisionTreeClassifier().fit(X, y)
# Plot the decision boundary
plt.subplot(2, 3, pairidx + 1)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu)
plt.xlabel(iris.feature_names[pair[0]])
plt.ylabel(iris.feature_names[pair[1]])
# Plot the training points
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i],
cmap=plt.cm.RdYlBu, edgecolor='black', s=15)
plt.suptitle("Decision surface of a decision tree using paired features")
plt.legend(loc='lower right', borderpad=0, handletextpad=0)
plt.axis("tight")
plt.figure()
clf = DecisionTreeClassifier().fit(iris.data, iris.target)
plot_tree(clf, filled=True)
plt.show()
Automatically created module for IPython interactive environment
4. 数据集划分及结果评估
数据集获取
from sklearn import datasets # 导入方法类
iris = datasets.load_iris() # 加载 iris 数据集
iris_feature = iris.data # 特征数据
iris_target = iris.target # 分类数据
数据集划分
from sklearn.model_selection import train_test_split
feature_train, feature_test, target_train, target_test = train_test_split(iris_feature, iris_target, test_size=0.33, random_state=42)
模型训练及预测
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier() # 所有参数均置为默认状态
dt_model.fit(feature_train,target_train) # 使用训练集训练模型
predict_results = dt_model.predict(feature_test) # 使用模型对测试集进行预测
结果评估
scores = dt_model.score(feature_test, target_test)
scores
1.0
参考文档
scikit-learn 1.10.1 DecisionTreeClassifier API User Guide
Example: a decision tree on the iris dataset
【sklearn决策树算法】DecisionTreeClassifier(API)的使用以及决策树代码实例 - 鸢尾花分类的更多相关文章
- Spark 实践——用决策树算法预测森林植被
本文基于<Spark 高级数据分析>第4章 用决策树算法预测森林植被集. 完整代码见 https://github.com/libaoquan95/aasPractice/tree/mas ...
- 《BI那点儿事》Microsoft 决策树算法
Microsoft 决策树算法是由 Microsoft SQL Server Analysis Services 提供的分类和回归算法,用于对离散和连续属性进行预测性建模.对于离散属性,该算法根据数据 ...
- 通俗地说决策树算法(三)sklearn决策树实战
前情提要 通俗地说决策树算法(一)基础概念介绍 通俗地说决策树算法(二)实例解析 上面两篇介绍了那么多决策树的知识,现在也是时候来实践一下了.Python有一个著名的机器学习框架,叫sklearn.我 ...
- sklearn实现决策树算法
1.决策树算法是一种非参数的决策算法,它根据数据的不同特征进行多层次的分类和判断,最终决策出所需要预测的结果.它既可以解决分类算法,也可以解决回归问题,具有很好的解释能力.另外,对于决策树的构建方法具 ...
- scikit-learn决策树算法类库使用小结
之前对决策树的算法原理做了总结,包括决策树算法原理(上)和决策树算法原理(下).今天就从实践的角度来介绍决策树算法,主要是讲解使用scikit-learn来跑决策树算法,结果的可视化以及一些参数调参的 ...
- 转载:scikit-learn学习之决策树算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 决策树算法的Python实现—基于金融场景实操
决策树是最经常使用的数据挖掘算法,本次分享jacky带你深入浅出,走进决策树的世界 基本概念 决策树(Decision Tree) 它通过对训练样本的学习,并建立分类规则,然后依据分类规则,对新样本数 ...
- day-8 python自带库实现ID3决策树算法
前一天,我们基于sklearn科学库实现了ID3的决策树程序,本文将基于python自带库实现ID3决策树算法. 一.代码涉及基本知识 1. 为了绘图方便,引入了一个第三方treePlotter模块进 ...
- Kaggle竞赛入门:决策树算法的Python实现
本文翻译自kaggle learn,也就是kaggle官方最快入门kaggle竞赛的教程,强调python编程实践和数学思想(而没有涉及数学细节),笔者在不影响算法和程序理解的基础上删除了一些不必要的 ...
随机推荐
- 修改 VS2013 项目属性的默认包含路径(全局)
1. 这里已不能更改. 2. 修改位置: C:\Users\N3verL4nd\AppData\Local\Microsoft\MSBuild\v4.0 Microsoft.Cpp.Win32.use ...
- Codeforces_478_C
http://codeforces.com/problemset/problem/478/C 水. #include<stdio.h> int main() { long long a,b ...
- Python中zip()函数的解释和可视化
zip()的作用 先看一下语法: zip(iter1 [,iter2 [...]]) -> zip object Python的内置help()模块提供了一个简短但又有些令人困惑的解释: 返回一 ...
- 深度学习中的特征(feature)指的是什么?
一般在machine learning意义上,我们常说的feature,是一种对数据的表达.当然,要衡量一种feature是否是合适的表达,要根据数据,应用,ML的模型,方法....很多方面来看.一般 ...
- 【WPF学习】第四十四章 图画
通过上一章的学习,Geometry抽象类表示形状或路径.Drawing抽象类扮演了互补的角色,它表示2D图画(Drawing)——换句话说,它包含了显示矢量图像或位图需要的所有信息. 尽管有几类画图类 ...
- API 接口设计规范
概述 这篇文章分享 API 接口设计规范,目的是提供给研发人员做参考. 规范是死的,人是活的,希望自己定的规范,不要被打脸. 路由命名规范 动作 前缀 备注 获取 get get{XXX} 获取 ge ...
- 【Java并发工具类】CountDownLatch和CyclicBarrier
前言 下面介绍协调让多线程步调一致的两个工具类:CountDownLatch和CyclicBarrier. CountDownLatch和CyclicBarrier的用途介绍 CountDownLat ...
- 渡一教育公开课重点笔记之html
常用的编码字符集:(charset) 1)gb2312 (国标第2312条)缺点:只能识别简体中文 2)gbk (国标扩展字符集,可识别所有亚裔字符) 3)Unicode (万国码) 4)Utf-8 ...
- 中文维基百科分类提取(jwpl)--构建知识图谱数据获取
首先感谢 : 1.https://blog.csdn.net/qq_39023569/article/details/88556301 2.https://www.cnblogs.com/Cheris ...
- css实现表单label文字两端对齐
如图,在我们写页面的时候,经常遇到这种的情况,而需求是想让label文字两端对齐,我们来看看如何用css解决 /**css代码**/ ul li{ list-style: none; } .info- ...