使用selenium进行爬取掘金前端小册的数据
Selenium 简介
百度百科介绍:
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),[Mozilla Firefox](https://baike.baidu.com/item/Mozilla Firefox/3504923),Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
使用流程
- 根据平台下载需要的webdrive
| Browser | Component |
|---|---|
| Chrome | chromedriver(.exe) |
| Internet Explorer | IEDriverServer.exe |
| Edge | MicrosoftWebDriver.msi |
| Firefox | geckodriver(.exe) |
| Safari | safaridriver |
根据自己的环境进行下载,将下载好的压缩包解压到项目的根目录不需要安装,各个浏览器的版本和dirver的版本的选择需要相近,不能盲目选择最新的版本,否则会出现意想不到的bug,建议最好将浏览器升级至最新的稳定版本并选择对应的包。
- 下载依赖包
npm install selenium-webdriver
- 玩一下官方demo, 做适当的代码修改并根据代码进行注释
// 1. 引入selenium-webdriver包,解构需要的对象和方法
const {Builder, By, Key, until} = require('selenium-webdriver');
// 2. 将需要的代码包在一个自执行函数中
(async function example() {
// 实例化 driver 对象, chrome 代表使用的浏览器
let driver = await new Builder().forBrowser('chrome').build();
try {
// 需要打开的网站地址
await driver.get('https://www.baidu.com/');
// Key.RETURN enter回车
// By.id('id') 百度查询滴输入内容
// 找到元素 向里面发送一个关键字并按回撤
await driver.findElement(By.id('kw')).sendKeys('酒店', Key.RETURN);
// 等1秒之后,验证是否搜索成功
// await driver.wait(until.titleIs('酒店_百度搜索'), 1000);
} finally {
// 关闭浏览器
// await driver.quit();
}
})();
爬取掘金小册数据
- 实现的功能
- 自动打开掘金页面的首页
- 自动点击小册、前端进行路由切换
- 将前端的全部小册数据爬取
- 注意点
- 由于selenium内部都是基于promise进行的封装,所有的方法调用其实返回的都是一个promise对象,因此会大量的使用async语法
自动打开掘金页面的首页
一句话搞定自动打开掘金首页
// 自动打开掘金
await driver.get('https://juejin.im/timeline');
自动点击进行路由跳转
在浏览器中,查看页面的布局结构,找到小册的位置,若是使用jq进行dom选择,则是 $('.main-header-box .nav-item:nth-of-type(4)')
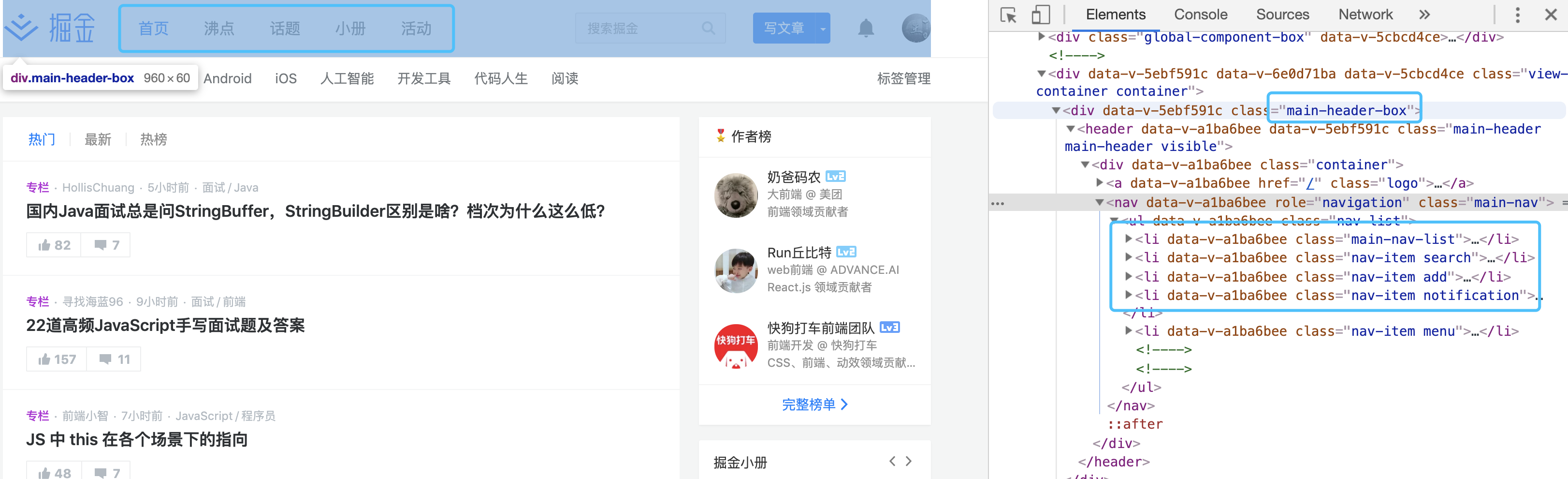
selenium中的By拥有很多的选择,其使用规则和jq非常相似,By.css('.main-header-box .nav-item:nth-of-type(4)')便可以找到对应的元素,调用click事件就可以模拟自动点击
// 点击小册子的navBar 切换路由到小册
await driver
.findElement(By.css('.main-header-box .nav-item:nth-of-type(4)'))
.click();
await driver.sleep(1000)
- 当点击小册之后,会调用 await driver.sleep(1000),因为当页面点击之后,页面会进行重新渲染,此时防止接下来的操作,获取不到数据或者获取的数据不是期望值,增加一个延迟确保数据的准确性
将前端的全部小册数据爬取
- 根据driver.findElements(By.css('.list-wrap .books-list .item'))获取前端小册列表,需要注意的是,当页面点击navBar之后,页面会进行重新渲染,但是此时若是直接去获取小测列表将会存在风险,因为在页面没有渲染完成之前获取不到期望值,而代码也会异常终止程序的运行
- 进行迭代取出希望获取的数据,根据itemInfo.findElement(By.css('.info .title')).getText()
while (true) {
let listViewError = true;
try {
// 获取小册列表
let _li = await driver.findElements(By.css('.list-wrap .books-list .item'));
console.log(_li.length);
for (let i = 0, _len = _li.length; i < _len; i++) {
const itemInfo = _li[i];
const title = await itemInfo.findElement(By.css('.info .title')).getText()
const desc = await itemInfo.findElement(By.css('.info .desc')).getText()
let price = await itemInfo.findElement(By.css('.info .price-text')).getText()
_result.push({
title,
desc,
price
})
}
console.log('_result',_result);
} catch (error) {
if (error) listViewError = false;
} finally {
if (listViewError) break;
}
}
在获取列表的时候,为什么会在最外层增加一个while呢?在 try catch 中的处理又是起到什么作用?
- while能确保会不断的获取数据,直到页面渲染完成获取到期望的数据
- try catch 可以保证程序在遇到异常时不会直接终止程序,可以继续运行
- listViewError表示程序是否存在异常情况,若是存在则会进入 catch 中,这个时候 listViewError 为 false,finally 则不会走break,会继续执行while程序,直到能获取到数据finally才为true,这个时候 finally中则会break 整个while的循环,跳出循环继续执行
总结
几十行的代码便可以将掘金的小册数据全部爬到,还是简单和好用的
全部代码
/*
* @Author: nordon-wang
* @Date: 2019-08-13 11:05:36
* @Description: 爬取掘金数据
*/
const { Builder, By, Key, until } = require('selenium-webdriver');
let _result = []; // 用来收集获取的数据
(async function start() {
let driver = await new Builder().forBrowser('chrome').build();
try {
// 自动打开掘金
await driver.get('https://juejin.im/timeline');
// 点击小册子的navBar 切换路由到小册
await driver
.findElement(By.css('.main-header-box .nav-item:nth-of-type(4)'))
.click();
await driver.sleep(1000)
// 点击二级菜单
await clickViewNav(driver);
await driver.sleep(1000)
// 获取数据
await getList(driver);
} catch (error) {
console.log(error);
} finally {
let timer = setTimeout(async () => {
clearTimeout(timer);
await driver.quit();
}, 600000);
}
})();
// 获取渲染完成的按钮
async function clickViewNav(driver) {
while (true) {
let viewNavError = true;
try {
await driver
.findElement(By.css('.main-container .view-nav .nav-item:nth-of-type(2)'))
.click();
} catch (error) {
if (error) viewNavError = false;
} finally {
if (viewNavError) break;
}
}
}
// 获取列表数据
// 页面在渲染完成之前无法获取到页面的元素
async function getList(driver) {
while (true) {
let listViewError = true;
try {
// 获取小册列表
let _li = await driver.findElements(By.css('.list-wrap .books-list .item'));
console.log(_li.length);
for (let i = 0, _len = _li.length; i < _len; i++) {
const itemInfo = _li[i];
const title = await itemInfo.findElement(By.css('.info .title')).getText()
const desc = await itemInfo.findElement(By.css('.info .desc')).getText()
let price = await itemInfo.findElement(By.css('.info .price-text')).getText()
_result.push({
title,
desc,
price
})
}
console.log('_result',_result);
} catch (error) {
if (error) listViewError = false;
} finally {
if (listViewError) break;
}
}
}
使用selenium进行爬取掘金前端小册的数据的更多相关文章
- 小爬爬6: 网易新闻scrapy+selenium的爬取
1.https://news.163.com/ 国内国际,军事航空,无人机都是动态加载的,先不管其他我们最后再搞中间件 2. 我们可以查看到"国内"等板块的位置 新建一个项目,创建 ...
- [python爬虫] Selenium定向爬取PubMed生物医学摘要信息
本文主要是自己的在线代码笔记.在生物医学本体Ontology构建过程中,我使用Selenium定向爬取生物医学PubMed数据库的内容. PubMed是一个免费的搜寻引擎,提供生物医学方 ...
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页
Python3.x:Selenium+PhantomJS爬取带Ajax.Js的网页 前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但 ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- selenium+phantomjs爬取bilibili
selenium+phantomjs爬取bilibili 首先我们要下载phantomjs 你可以到 http://phantomjs.org/download.html 这里去下载 下载完之后解压到 ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- selenium登录爬取知乎出现:请求异常请升级客户端后重试的问题(用Python中的selenium接管chrome)
一.问题使用selenium自动化测试爬取知乎的时候出现了:错误代码10001:请求异常请升级客户端后重新尝试,这个错误的产生是由于知乎可以检测selenium自动化测试的脚本,因此可以阻止selen ...
- 使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息 转载请注明出处. 爬取目标:每个电影的评分.名称.时长.主演.和类型 爬取思路: 源文件:(有注释) from selenium import webd ...
- scrapy中使用selenium来爬取页面
scrapy中使用selenium来爬取页面 from selenium import webdriver from scrapy.http.response.html import HtmlResp ...
随机推荐
- js常用设计模式实现(三)建造者模式
创建型模式 创建型模式是对一个类的实例化过程进行了抽象,把对象的创建和对象的使用进行了分离 关于创建型模式,已经接近尾声了,还剩下建造者模式和原型模式,这一篇说一说建造者模式 建造者模式的定义 将一个 ...
- IntelliJ Idea 常用快捷键总结-0 #<间断性更新中...>,部分有示例
IntelliJ Idea 常用快捷键总结-0 <间断性更新中...>,部分有示例 自动补齐代码 常用的有for循环体,fori可以输出循环语句: eg: public void test ...
- 走近Java之包装器类Integer
前几天,有个同事问了我一个关于Integer类赋值的问题,很有意思,我们一起来看一下(如果有说的不正确的地方,欢迎大家指正). 如上图,同样是赋值,但是两次比较的结果完全不同.我们走近了解一下. 在I ...
- Excel中PMT函数的Java实现
public class PMT { /** * * 计算月供 * * @param rate * 年利率 年利率除以12就是月利率 * @param nper * 贷款期数,单位月 该项贷款的付款总 ...
- [leetcode] 543. Diameter of Binary Tree (easy)
原题 思路: 题目其实就是求左右最长深度的和 class Solution { private: int res = 0; public: int diameterOfBinaryTree(TreeN ...
- [virtualenvwrapper] 命令小结
创建环境 mkvirtualenv env1 mkvirtualenv env2 环境创建之后,会自动进入该目录,并激活该环境. 切换环境 workon env1 workon env2 列出已有环境 ...
- CHM格式
转载请标明出处:https://www.cnblogs.com/tangZH/p/11176995.html CHM格式为CHM头,CHM头节,内容三部分组成. 总体格式图: 初始化头包含了CHM的相 ...
- Html5web全栈前端开发_angular框架
昵称领取全套angular视频教程 一.Typescript typescript简称ts,是js语法的超集,很多js新的语法就借鉴了ts语法.ts是由微软团队维护的 1.1 TS简介 1.1.1 G ...
- 没事别想不开做Halcon视觉工程师 halcon机器视觉如何学习?
今天我们来听听看来自一个机器视觉工程师的唠叨和吐槽,在这之后,你还想学人工智能,还想学机器视觉?恭喜你,你对人工智能机器视觉是真爱了! 既然自己选择了这条路,那么无论前进路上有多坎坷,跪着也要走完. ...
- 通过OpenGL理解前端渲染原理(1)
一.OpenGL OpenGL,是一套绘制3D图形的API,当然它也可以用来绘制2D的物体.OpenGL有一大套可以用来操作模型和图片的函数,通常编写OpenGL库的人是显卡的制造者.我们买的显卡都支 ...