【linux】【ELK】搭建Elasticsearch+Logstash+Kibana+Filebeat日志收集系统
前言
ELK是Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部。
Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
Filebeat是本地文件的日志数据采集器。 作为服务器上的代理安装,Filebeat监视日志目录或特定日志文件,tail file,并将它们转发给Elasticsearch或Logstash进行索引、kafka 等。
linux本地docker.log--》filebeat(收集日志)--》logstash(过滤)--》elasticsearch(添加索引)--》kibana检索显示

docker-elk 服务端 :https://github.com/jiangxd0716/ELK-filebeat.git elasticsearch logstash kibana
elk-filebeat 客户端:https://github.com/jiangxd0716/ELK-filebeat.git filebeat用于收集日志,传给elk
环境
Centos7
192.168.8.20 elasticsearch logstash kibana filebeat
192.168.8.10 filebeat
192.168.8.30 filebeat
服务:
- elasticsearch:9200
- logstash:5000
- kibana:5601
安装
一、安装docker-elk服务端
1.拉取代码
- git clone https://github.com/jiangxd0716/ELK-filebeat.git
2.安装docker及docker-compose
参考:https://www.cnblogs.com/jxd283465/p/11542127.html
3.启动服务端
[root@localhost docker-elk]# pwd
/home/ELK-filebeat/docker-elk
[root@localhost docker-elk]# docker-compose up -d
Starting dockerelk_elasticsearch_1 ...
Starting dockerelk_elasticsearch_1 ... done
Starting dockerelk_kibana_1 ...
Starting dockerelk_logstash_1 ...
Starting dockerelk_kibana_1
Starting dockerelk_kibana_1 ... done
[root@localhost docker-elk]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7152edaa71dc dockerelk_kibana "/usr/local/bin/dumb…" 3 minutes ago Up 4 seconds 0.0.0.0:5601->5601/tcp dockerelk_kibana_1
63908878fb00 dockerelk_logstash "/usr/local/bin/dock…" 3 minutes ago Up 4 seconds 0.0.0.0:5000->5000/tcp, 0.0.0.0:9600->9600/tcp, 5044/tcp dockerelk_logstash_1
d3c44ac2264c dockerelk_elasticsearch "/usr/local/bin/dock…" 3 minutes ago Up 4 seconds 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp dockerelk_elasticsearch_1
4.访问kibana
浏览器访问 http://192.168.8.20:5601

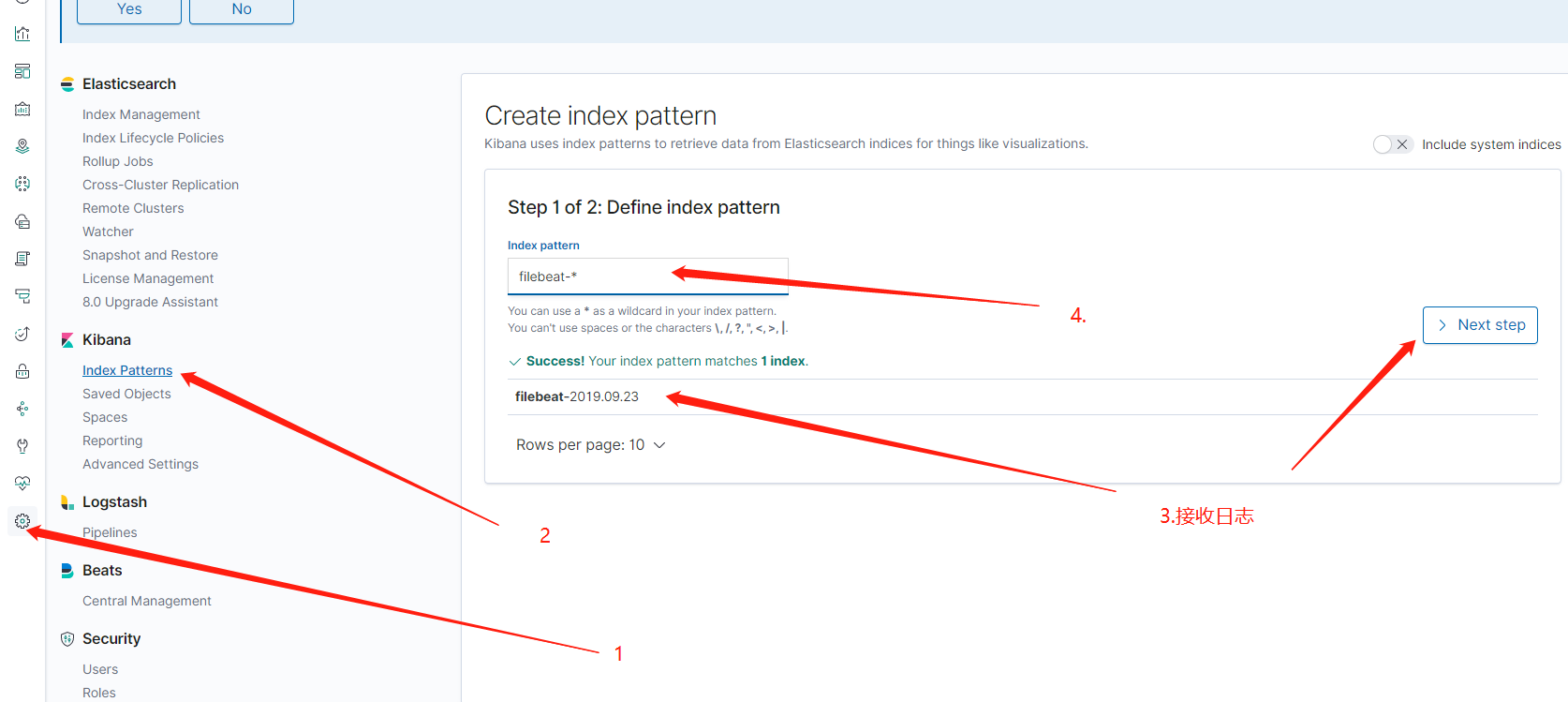
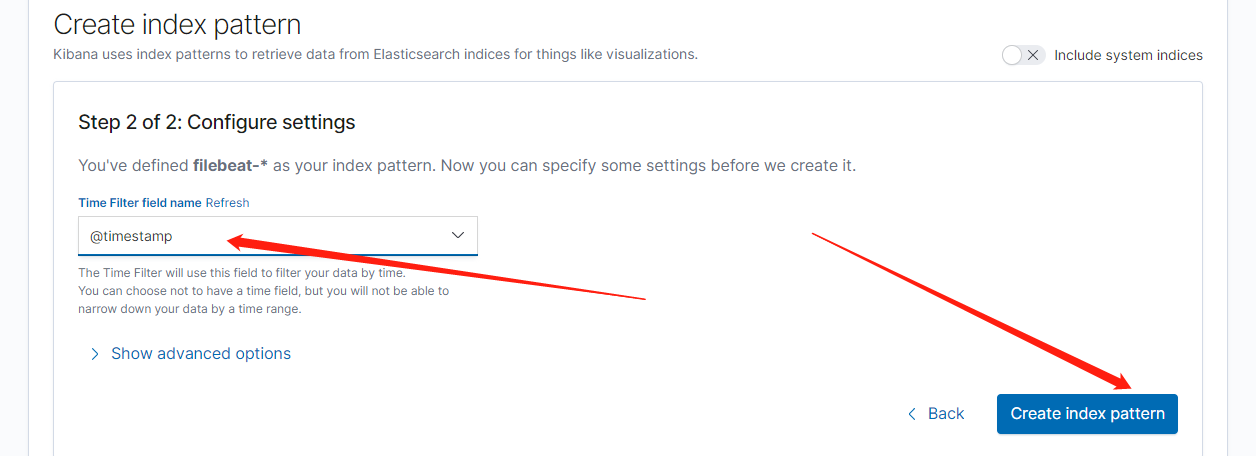
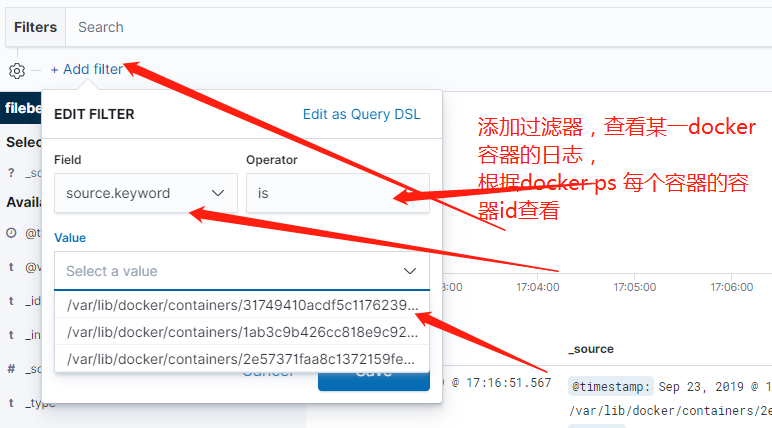
二、安装客户端
1.修改filebeat的配置文件filebeat.yml-------output到elasticsearch或者logstash
[root@localhost config]# pwd
/home/ELK/ELK/docker-elk/filebeat/config
[root@localhost config]# vi filebeat.yml
[root@localhost config]# cat filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/lib/docker/containers/*/*.log #需要读取日志的目录#这里读取的是docker的日志文件,也可以加入tomcat、nginx等配置文件
document_type: syslog
json.keys_under_root: true # 因为docker使用的log driver是json-file,因此采集到的日志格式是json格式,设置为true之后,filebeat会将日志进行json_decode处理
json.add_error_key: true #如果启用此设置,则在出现JSON解组错误或配置中定义了message_key但无法使用的情况下,Filebeat将添加“error.message”和“error.type:json”键。
json.message_key: log #一个可选的配置设置,用于指定应用行筛选和多行设置的JSON密钥。 如果指定,键必须位于JSON对象的顶层,且与键关联的值必须是字符串,否则不会发生过滤或多行聚合。
tail_files: true
# 将error日志合并到一行
multiline.pattern: '^([0-9]{4}|[0-9]{2})-[0-9]{2}'
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
# registry_file: /opt/filebeat/registry
#-------------------------- Elasticsearch output ------------------------------
# 直接输出到elasticsearch,这里的hosts是elk地址,端口号是elasticsearch端口#
#output.elasticsearch:
# hosts: ["192.168.8.100:9200"]
# username: "elastic"
# password: "changeme"
output:
logstash:
enabled: true
hosts:
- 192.168.8.20:5000 #这里将filebeat收集的日志output到logstash,此处为logstash的ip和端口,也可以直接输送到elasticsearch
#==================== Elasticsearch template setting ==========================
setup.template.name: "filebeat.template.json"
setup.template.fields: "filebeat.template.json"
setup.template.overwrite: true
setup.template.enabled: false
# 过滤掉一些不必要字段#
processors:
- drop_fields:
fields: ["input_type", "offset", "stream", "beat"]
2.启动客户端
[root@localhost elk-filebeat]# pwd
/home/ELK-filebeat/elk-filebeat
[root@localhost elk-filebeat]# docker-compose up -d
Creating network "elkfilebeat_default" with the default driver
Creating elkfilebeat_filebeat_1 ...
Creating elkfilebeat_filebeat_1 ... done
[root@localhost elk-filebeat]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
31749410acdf prima/filebeat "/docker-entrypoint.…" 5 minutes ago Up 5 minutes elkfilebeat_filebeat_1
2e57371faa8c dockerelk_kibana "/usr/local/bin/dumb…" 7 minutes ago Up 7 minutes 0.0.0.0:5601->5601/tcp dockerelk_kibana_1
09220beadd39 dockerelk_logstash "/usr/local/bin/dock…" 7 minutes ago Up 7 minutes 0.0.0.0:5000->5000/tcp, 0.0.0.0:9600->9600/tcp, 5044/tcp dockerelk_logstash_1
1ab3c9b426cc dockerelk_elasticsearch "/usr/local/bin/dock…" 7 minutes ago Up 7 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp dockerelk_elasticsearch_1
【linux】【ELK】搭建Elasticsearch+Logstash+Kibana+Filebeat日志收集系统的更多相关文章
- ELK日志系统:Elasticsearch+Logstash+Kibana+Filebeat搭建教程
ELK日志系统:Elasticsearch + Logstash + Kibana 搭建教程 系统架构 安装配置JDK环境 JDK安装(不能安装JRE) JDK下载地址:http://www.orac ...
- ELK (Elasticsearch , Logstash, Kibana [+FileBeat])
ELK 简述: ELK 是: Elasticsearch , Logstash, Kibana 简称, 它们都是开源软件. Elasticsearch[搜索]是个开源分布式基于Lucene的搜索引擎, ...
- Centos7下使用ELK(Elasticsearch + Logstash + Kibana)搭建日志集中分析平台
日志监控和分析在保障业务稳定运行时,起到了很重要的作用,不过一般情况下日志都分散在各个生产服务器,且开发人员无法登陆生产服务器,这时候就需要一个集中式的日志收集装置,对日志中的关键字进行监控,触发异常 ...
- ELK( ElasticSearch+ Logstash+ Kibana)分布式日志系统部署文档
开始在公司实施的小应用,慢慢完善之~~~~~~~~文档制作 了好作运维同事之间的前期普及.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 软件下载地址: https://www.e ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
- ELK(ElasticSearch+Logstash+Kibana)配置中的一些坑基于7.6版本
三个组件都是采用Docker镜像安装,过程简单不做赘述,直接使用Docker官方镜像运行容器即可,注意三个组件版本必须一致. 运行容器时最好将三个组件的核心配置文件与主机做映射,方便直接在主机修改不用 ...
- 搭建Elasticsearch Logstash Kibana 日志系统
分布式系统下由于日志文件分布在不同的系统上,分析比较麻烦,通过搭建elk日志系统,可快速排查日志信息. Elasticsearch是大数据处理框架,使用的分布式存储,可存储海量数据:基于Lucense ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
- 【Big Data - ELK】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticSearch,一款基于Apache Lucene的开源分布式搜索引擎)中便于查找和分析,在研究 ...
随机推荐
- Jupter NotebooK学习
1.参考资料 B站上学习视频 Jupyter 安装与使用 2.安装 在cmd窗口中输入(创建的文件会再当前的目录下):pip install jupyter 然后输入:jupyter notebook ...
- HandlerMethodArgumentResolver(三):基于消息转换器的参数处理器【享学Spring MVC】
每篇一句 一个事实是:对于大多数技术,了解只需要一天,简单搞起来只需要一周.入门可能只需要一个月 前言 通过 前面两篇文章 的介绍,相信你对HandlerMethodArgumentResolver了 ...
- Linux CentOS7 下设置tomcat 开机自启动
网上有很多教程说是可以设置Tomcat 自启动,但是一一验证了都不行.最后找到一个方法 验证可以: 1.改rc.local 位于/etc/rc.d/文件下的rc.local vi /etc/r ...
- CopyOnWriteArrayList笔记
CopyOnWriteArrayList笔记 一.前言 Java 5.0 在java.util.concurrent 包中提供了多种并发容器类来改进同步容器的性能. ConcurrentHashMap ...
- Spring框架入门之Spring4.0新特性——泛型注入
Spring框架入门之Spring4.0新特性——泛型注入 一.为了更加快捷的开发,为了更少的配置,特别是针对 Web 环境的开发,从 Spring 4.0 之后,Spring 引入了 泛型依赖注入. ...
- 数据的查找和提取[2]——xpath解析库的使用
xpath解析库的使用 在上一节,我们介绍了正则表达式的使用,但是当我们提取数据的限制条件增多的时候,正则表达式会变的十分的复杂,出一丁点错就提取不出来东西了.但python已经为我们提供了许多用于解 ...
- 逆向破解之160个CrackMe —— 025
CrackMe —— 025 160 CrackMe 是比较适合新手学习逆向破解的CrackMe的一个集合一共160个待逆向破解的程序 CrackMe:它们都是一些公开给别人尝试破解的小程序,制作 c ...
- 根据图中的盲点坐标,弹出div层
<div class="map_r" id="mapinfo" style="position: absolute; top: 20px; le ...
- HDU-DuoXiao第二场hdu 6315 Naive Operations 线段树
hdu 6315 题意:对于一个数列a,初始为0,每个a[ i ]对应一个b[i],只有在这个数字上加了b[i]次后,a[i]才会+1. 有q次操作,一种是个区间加1,一种是查询a的区间和. 思路:线 ...
- Codefroces 374 B Inna and Sequence (树状数组 || 线段树)
Inna and Sequence 题意:先给你一个n,一个m, 然后接下来输入m个数,表示每次拳击会掉出数的位置,然后输入n个数,每次输入1或0在数列的末尾加上1或0,如果输入-1,相应m序列的数的 ...