TensorFlow笔记-模型的保存,恢复,实现线性回归
模型的保存
tf.train.Saver(var_list=None,max_to_keep=5)
•var_list:指定将要保存和还原的变量。它可以作为一个
dict或一个列表传递.
•max_to_keep:指示要保留的最近检查点文件的最大数量。
创建新文件时,会删除较旧的文件。如果无或0,则保留所有
检查点文件。默认为5(即保留最新的5个检查点文件。)
saver = tf.train.Saver()
saver.save(sess, "")
模型的恢复
恢复模型的方法是restore(sess, save_path),save_path是以前保存参数的路径,我们可以使用tf.train.latest_checkpoint来获取最近的检查点文件(也恶意直接写文件目录)
if os.path.exists("tmp/ckpt/checkpoint"):
saver.restore(sess,"")
print("恢复模型")
自定义命令行参数
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('data_dir', '/tmp/tensorflow/mnist/input_data',
"""数据集目录""")
tf.app.flags.DEFINE_integer('max_steps', 2000,
"""训练次数""")
tf.app.flags.DEFINE_string('summary_dir', '/tmp/summary/mnist/convtrain',
"""事件文件目录""")
def main(argv):
print(FLAGS.data_dir)
print(FLAGS.max_steps)
print(FLAGS.summary_dir)
print(argv)
if __name__=="__main__":
tf.app.run()
线性回归
准备数据
with tf.variable_scope("data"):
# 1、准备数据,x 特征值 [100, 1] y 目标值[100]
x = tf.random_normal([100, 1], mean=1.75, stddev=0.5, name="x_data")
# 矩阵相乘必须是二维的
y_true = tf.matmul(x, [[0.7]]) + 0.8
构建模型
with tf.variable_scope("model"):
# 2、建立线性回归模型 1个特征,1个权重, 一个偏置 y = x w + b
# 随机给一个权重和偏置的值,让他去计算损失,然后再当前状态下优化
# 用变量定义才能优化
weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name="w")
bias = tf.Variable(0.0, name="b")
y_predict = tf.matmul(x, weight) + bias
构造损失函数
with tf.variable_scope("loss"):
# 3、建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_true - y_predict))
利用梯度下降
with tf.variable_scope("optimizer"):
# 4、梯度下降优化损失 leaning_rate: 0 ~ 1, 2, 3,5, 7, 10
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
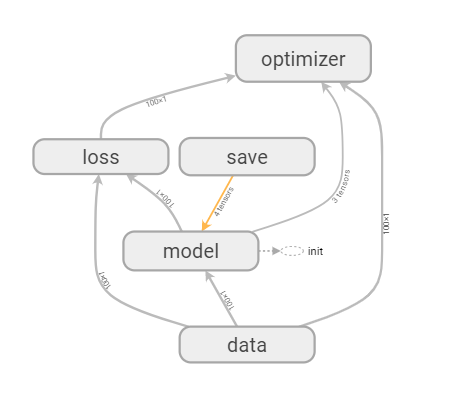
源码
import tensorflow as tf
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
# 在这里立flag
tf.app.flags.DEFINE_integer("max_step",100,"模型训练的步数")
tf.app.flags.DEFINE_string("model_dir","tmp/summary/test","模型文件的加载路径") FLAGS = tf.app.flags.FLAGS
def myregression():
with tf.variable_scope("data"):
x = tf.random_normal([100, 1], mean=1.75, stddev=0.5)
y_true = tf.matmul(x, [[0.7]]) + 0.8
with tf.variable_scope("model"):
# 权重 trainable 指定权重是否随着session改变
weight = tf.Variable(tf.random_normal([int(x.shape[1]), 1], mean=0, stddev=1), name="w")
# 偏置项
bias = tf.Variable(0.0, name='b')
# 构造y函数
y_predict = tf.matmul(x, weight) + bias
with tf.variable_scope("loss"):
# 定义损失函数
loss = tf.reduce_mean(tf.square(y_true - y_predict))
with tf.variable_scope("optimizer"):
# 使用梯度下降进行求解
train_op = tf.train.GradientDescentOptimizer(0.1).minimize((loss))
# 1.收集tensor
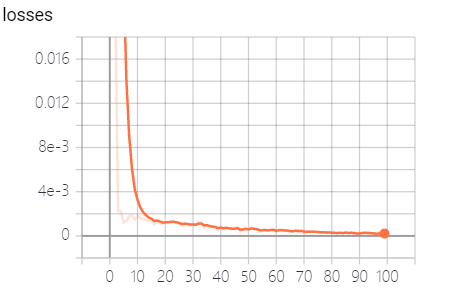
tf.summary.scalar("losses", loss)
tf.summary.histogram("weights", weight)
# 2.定义合并tensor的op
merged = tf.summary.merge_all()
# 定义一个保存模型的op
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
# import matplotlib.pyplot as plt
# plt.scatter(x.eval(), y_true.eval())
# plt.show()
print("初始化的权重:%f,偏置项:%f" % (weight.eval(), bias.eval()))
# 建立事件文件
filewriter = tf.summary.FileWriter('./tmp/summary/test/', graph=sess.graph)
# 加载模型
if os.path.exists("tmp/ckpt/checkpoint"):
saver.restore(sess,FLAGS.model_dir)
print("加载")
n = 0
while loss.eval() > 1e-6:
n += 1
if(n==FLAGS.max_step):
break
sess.run(train_op)
summary = sess.run(merged)
filewriter.add_summary(summary, n)
print("第%d次权重:%f,偏置项:%f" % (n, weight.eval(), bias.eval()))
saver.save(sess, FLAGS.model_dir)
return weight, bias myregression()
# x_min,x_max = np.min(x.eval()),np.max(x.eval())
# tx = np.arange(x_min,x_max,100)
TensorFlow笔记-模型的保存,恢复,实现线性回归的更多相关文章
- Tensorflow Learning1 模型的保存和恢复
CKPT->pb Demo 解析 tensor name 和 node name 的区别 Pb 的恢复 CKPT->pb tensorflow的模型保存有两种形式: 1. ckpt:可以恢 ...
- Tensorflow学习笔记----模型的保存和读取(4)
一.模型的保存:tf.train.Saver类中的save TensorFlow提供了一个一个API来保存和还原一个模型,即tf.train.Saver类.以下代码为保存TensorFlow计算图的方 ...
- Python之TensorFlow的模型训练保存与加载-3
一.TensorFlow的模型保存和加载,使我们在训练和使用时的一种常用方式.我们把训练好的模型通过二次加载训练,或者独立加载模型训练.这基本上都是比较常用的方式. 二.模型的保存与加载类型有2种 1 ...
- tensorflow 之模型的保存与加载(三)
前面的两篇博文 第一篇:简单的模型保存和加载,会包含所有的信息:神经网络的op,node,args等; 第二篇:选择性的进行模型参数的保存与加载. 本篇介绍,只保存和加载神经网络的计算图,即前向传播的 ...
- tensorflow 之模型的保存与加载(二)
上一遍博文提到 有些场景下,可能只需要保存或加载部分变量,并不是所有隐藏层的参数都需要重新训练. 在实例化tf.train.Saver对象时,可以提供一个列表或字典来指定需要保存或加载的变量. #!/ ...
- tensorflow 之模型的保存与加载(一)
怎样让通过训练的神经网络模型得以复用? 本文先介绍简单的模型保存与加载的方法,后续文章再慢慢深入解读. #!/usr/bin/env python3 #-*- coding:utf-8 -*- ### ...
- tensorflow:模型的保存和训练过程可视化
在使用tf来训练模型的时候,难免会出现中断的情况.这时候自然就希望能够将辛辛苦苦得到的中间参数保留下来,不然下次又要重新开始. 保存模型的方法: #之前是各种构建模型graph的操作(矩阵相乘,sig ...
- 【TensorFlow】TensorFlow基础 —— 模型的保存读取与可视化方法总结
TensorFlow提供了一个用于保存模型的工具以及一个可视化方案 这里使用的TensorFlow为1.3.0版本 一.保存模型数据 模型数据以文件的形式保存到本地: 使用神经网络模型进行大数据量和复 ...
- tensorflow模型的保存与恢复
1.tensorflow中模型的保存 创建tf.train.saver,使用saver进行保存: saver = tf.train.Saver() saver.save(sess, './traine ...
随机推荐
- mingw(gcc)默认使用的是dwarf格式
无意中发现的: C:\Users\my>gcc -vUsing built-in specs.COLLECT_GCC=gccCOLLECT_LTO_WRAPPER=C:/Qt/Qt5.6.2/T ...
- 基于Delphi实现客户端服务端通信Demo
在开始之前我们需要了解下这个Demo功能是啥 我们可以看到这是两个小project,左边的project有服务端和客户端1,右边的project只有一个客户端2 效果就是当两个客户端各自分别输入正确的 ...
- Delphi开发 Android 程序启动画面简单完美解决方案
原文在这里 还是这个方法好用,简单!加上牧马人做的自动生成工具,更是简单. 以下为原文,向波哥敬礼! 前面和音儿一起研究 Android 下启动画面的问题,虽然问题得到了解决,但是,总是感觉太麻烦,主 ...
- 关于这次KPL春季决赛的感悟
QG 4:0 横扫AG超玩会,关于这一点想写一些自己的感悟,AG超玩会一直都是 4:0 横扫别人,这次在冠军赛被别人横扫,一点喘息的机会都没有. 1.QGhappy 跟本没把AG超玩会放在眼里,很 ...
- Mount挂载/data时出现mount: /data is busy 如何解决?
1.df -h查看下挂载点/data是否正在使用,有时候会存在挂载了,但df -h不会显示出来,这时候 grep “/data” /proc/mounts 来进行查看 2.当确认挂载点/data正在使 ...
- 附005.Kubernetes身份认证
一 Kubernetes访问 1.1 Kubernetes交互 与Kubernetes交互通常有kubectl.客户端(Dashboard).REST API请求. 1.2 API访问流程 用户使用k ...
- Laravel --- Laravel 5.3 队列使用方法
一.设置存储方式 在config/queue.php中查看队列驱动,在.env 设置[QUEUE_DRIVER] 主要介绍数据库驱动 二.数据库驱动 1.修改.env CACHE_DRIVER=fil ...
- MCtalk对话尚德机构:AI讲师,假套路还是真功夫?
一间容纳百人的被挤得满满的教室,老师讲.学生听.线下课堂曾是职业教育最普遍的形式.随着移动互联网的普及,大量的学习行为逐渐转化到线上进行,传统教育机构如何抓住这轮技术转型的契机,而不是被它吞噬? 近日 ...
- maven_nexus私服搭建
搭建很简单,但是新版本运行方式有所区别,于此记录一下: 1.下载程序包:http://www.sonatype.org/nexus/downloads/ 官网比较慢,下了一小时.期间在csdn花了一积 ...
- Java学习笔记——String类型转换
一滴水里观沧海,一粒沙中看世界 ——一带一路欢迎宴致辞 上代码: package cn.stringtoobj; public class TypeConversion { public static ...