Elasticsearch 7.x Nested 嵌套类型查询 | ES 干货
一、什么是 ES Nested 嵌套
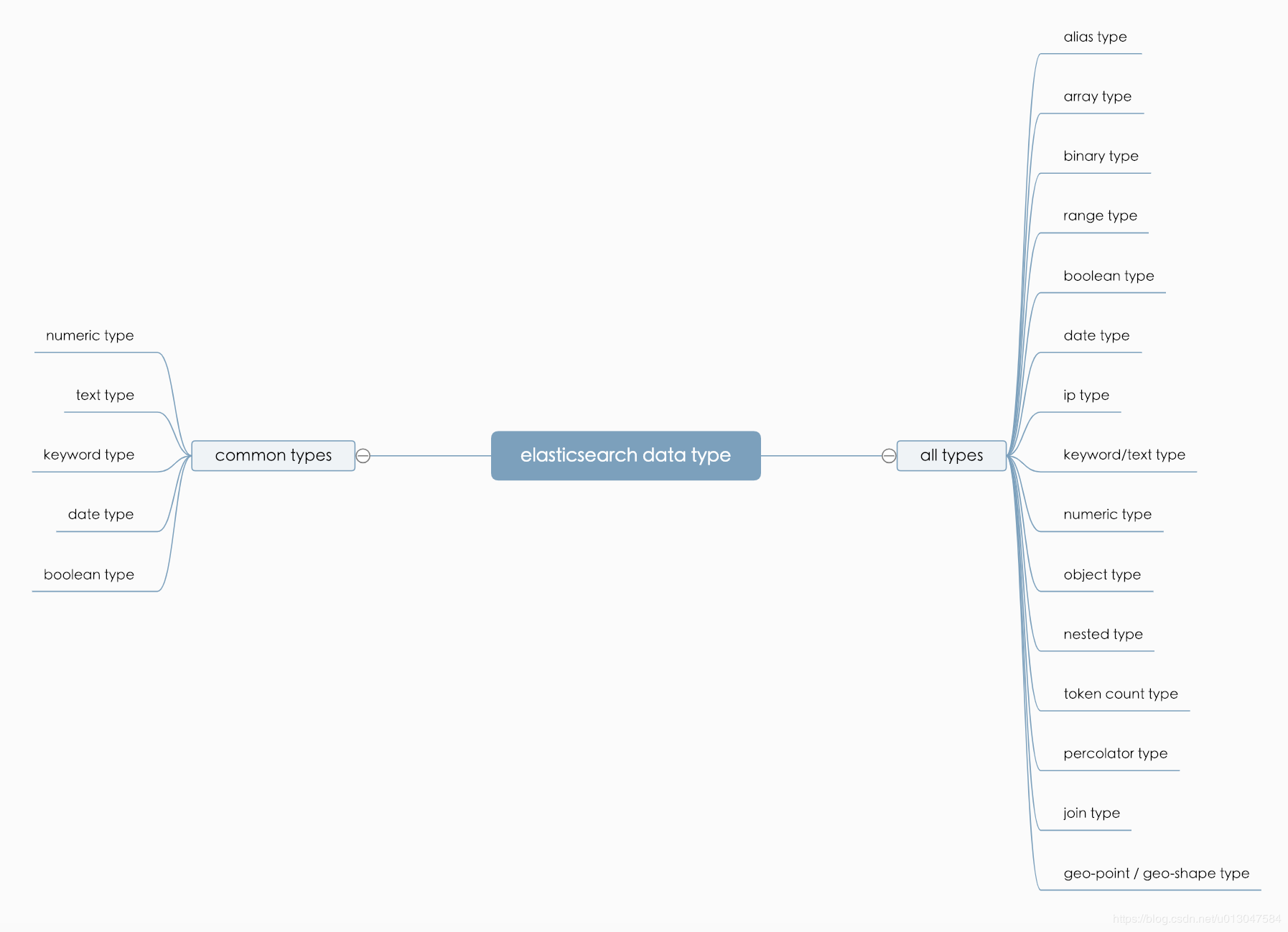
Elasticsearch 有很多数据类型,大致如下:
- 基本数据类型:
- string 类型。ES 7.x 中,string 类型会升级为:text 和 keyword。keyword 可以排序;text 默认分词,不可以排序。
- 数据类型:integer、long 等
- 时间类型、布尔类型、二进制类型、区间类型等
- 复杂数据类型:
- 数组类型:Array
- 对象类型:Object
- Nested 类型
- 特定数据类型:地理位置、IP 等
注意:tring/nested/array 类型字段不能用作排序字段。因此 string 类型会升级为:text 和 keyword。keyword 可以排序,text 默认分词,不可以排序。
2.1 那什么是 Nested 类型?
Elasticsearch 7.x 文档中,这样写到:
The nested type is a specialised version of the object datatype that allows arrays of objects to be indexed in a way that they can be queried independently of each other.Nested (嵌套)类型,是特殊的对象类型,特殊的地方是索引对象数组方式不同,允许数组中的对象各自地进行索引。目的是对象之间彼此独立被查询出来。
2.2 如何使用 Nested 类型?
在 ES 的 my_index 索引中存储 users 字段。比如说:
{
"group" : "fans",
"users" : [
{
"name" : "John",
"age" : "23"
},
{
"name" : "Alice",
"age" : "18"
}
]
}其实存储看上去跟 Object 类型一样,只不过底层原理对数组 users 字段索引方式不同。设置 users 字段的索引方式 Nested 嵌套类型:
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"users": {
"type": "nested"
}
}
}
}
'二、Nested Query 应用场景或案例
比如小老弟我有一波小粉丝,users 字段类型是 object。存储如下:
{
"group" : "bysocket_fans",
"users" : [
{
"name" : "John",
"age" : "23"
},
{
"name" : "Alice",
"age" : "18"
}
]
}
{
"group" : "路人甲_fans",
"users" : [
{
"name" : "Alice",
"age" : "22"
},
{
"name" : "Jeff",
"age" : "18"
}
]
}比如 18 岁大姑娘 Alice 是小老弟我的粉丝,她也可能是周杰伦的粉丝。那这边就有一个需求,即应用场景:
如何找到 18 岁大姑娘 Alice {"name" : "Alice","age" : "18"} 关注的所有明星呢?
如果用老的查询语句是这样搜索的:
GET /my_index/_search?pretty
{
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "Alice"
}
},
{
"match": {
"users.age": 18
}
}
]
}
}
}结果发现结果是不对的,路人甲 这条记录也出现了。
因为匹配到了第一个 Alice + 第二个 Jeff 的 18。所以这种查询不满足这个场景
那么需要使用 Nested 类型并用 Nested 查询,即让数组中的对象各自地进行索引。目的是对象之间彼此独立被查询出来。
三、Nested Query 实战
3.1 设置 Nested 类型
根据 2.2 如何使用 Nested 类型,将 users 字段类型从 object 修改为 nested:
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"users": {
"type": "nested"
}
}
}
}
'3.2 Nested Query
修改后,对应的 Nested Query ,如下:
GET /my_index/_search?pretty
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "users",
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "Alice"
}
},
{
"match": {
"users.age": 18
}
}
]
}
}
}
}
]
}
}
}语法很简单就是:
- key 以 "nested" 开头
- path 就是嵌套对象数组的字段名
- 其他
- score_mode (可选的)匹配子对象的分数相关性分数。avg (默认,使用所有匹配子对象的平均相关性分数)
- ignore_unmapped (可选的)是否忽略 path 未映射,不返回任何文档而不是错误。默认为 false,如果 path 不对就报错
这样查询得结果就是对的。
四、Nested Query 性能
这边测试过,给大家一个测试报告和建议。
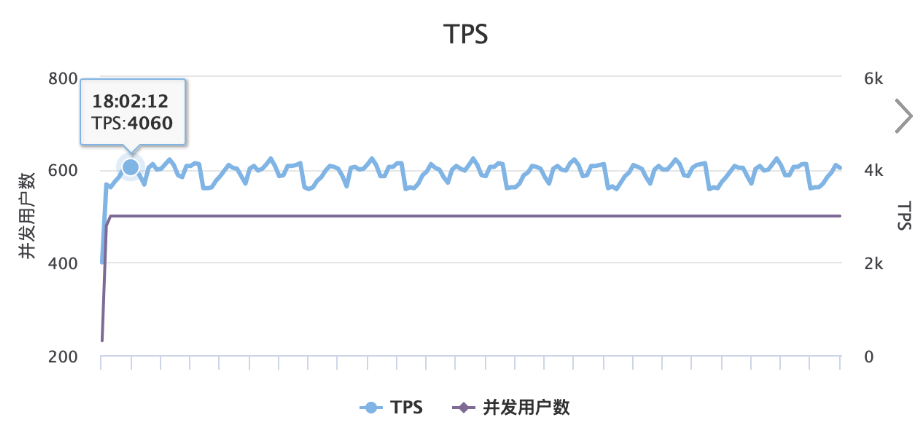
压测环境:3 个 server ,6 个 ES 节点
压测结论: 使用上小节查询语句,50 并发情况下,导致千兆网卡被打满了。TPS 4000 左右,如果提高并发,就会增加 RT。所以如果高性能大流量情况下,必须用 Nested 应该从网络流量方向进行优化。二者,尽量减少大数据对象的返回
建议:泥瓦匠建议,你听听看
- 性能:Common Query 远远大于 Nested Query 远远大于 Parent/Child Query
- 性能优化:首先考虑减少后面两种 Query
- 性能优化:Nested Query 业务可以优化下。比如上一小节完全可以多存一个 fanIds 数组。搜索两次,第一次查确定 18 岁大姑娘 Alice 的 fanId,第二次根据 fanId 搜索即可
- 性能优化:实在没办法,高性能大流量情况下,必须用 Nested 应该从网络流量方向进行优化。二者,尽量减少大数据对象的返回
(完)
参考资料:
- https://blog.csdn.net/laoyang360/article/details/82950393
- https://www.elastic.co/guide/en/elasticsearch/reference/7.2/search-aggregations-bucket-reverse-nested-aggregation.html
Elasticsearch 7.x Nested 嵌套类型查询 | ES 干货的更多相关文章
- 使用ElasticSearch完成百万级数据查询附近的人功能
上一篇文章介绍了ElasticSearch使用Repository和ElasticSearchTemplate完成构建复杂查询条件,简单介绍了ElasticSearch使用地理位置的功能. 这一篇我们 ...
- [ES]Python查询ES导出数据为Excel
版本 elasticsearch==5.5.0 python==3.7 说明 用python查询es上存储的状态数据,将查询到的数据用pandas处理成excel code # -*- coding: ...
- RestHighLevelClient查询es
本篇分享的是es官网推荐的es客户端组件RestHighLevelClient的使用,其封装了操作es的crud方法,底层原理就是模拟各种es需要的请求,如put,delete,get等方式:本篇主要 ...
- 解决 Elasticsearch 超过 10000 条无法查询的问题
解决 Elasticsearch 超过 10000 条无法查询的问题 问题描述 分页查询场景,当查询记录数超过 10000 条时,会报错. 使用 Kibana 的 Dev Tools 工具查询 从第 ...
- elasticsearch 嵌套对象之嵌套类型
nested类型是一种特殊的对象object数据类型(specialised version of the object datatype ),允许对象数组彼此独立地进行索引和查询. 1. 对象数组如 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- Elasticsearch DSL语句之连接查询
传统数据库支持的full join(全连接)查询方式. 这种方式在Elasticsearch中使用时非常昂贵的.因此,Elasticsearch提供两种操作可以支持水平扩展 更多内容请参考Elasti ...
- elasticsearch的5种分片查询优先级
elasticsearch可以使用preference参数来指定分片查询的优先级,使用时就是在请求url上加上preference参数,如:http://ip:host/index/_search?p ...
- Elasticsearch笔记五之java操作es
Java操作es集群步骤1:配置集群对象信息:2:创建客户端:3:查看集群信息 1:集群名称 默认集群名为elasticsearch,如果集群名称和指定的不一致则在使用节点资源时会报错. 2:嗅探功能 ...
随机推荐
- 长江存储32层3D NAND今年底准备好,预计2020年赶上世界前沿(有些ppt很精彩)
集微网消息(文/刘洋)2017年1月14日,首届IC咖啡国际智慧科技产业峰会暨ICTech Summit 2017在上海隆重举行.本次峰会以“匠心独运 卓越创‘芯’”为主题,集结了ICT产业领袖与行业 ...
- list 多行表头 表头合并
http://blog.csdn.net/safedebug/article/details/52971685
- UISearchController 的大坑
UISearchBar+UISearchDisplayController这个组合的稳定性经过几次iOS版本迭代肯定不言而喻,但苹果爸爸就是任性的在iOS8.0中宣布弃用UISearchDi ...
- Lamda一行代码实现"36选7"随机自动选号
南粤风采36选7是广东的一种彩票玩法.非常简单的从1-36个数字选7个. 今天在同事面前炫耀了一把,只用一行Lamda代码实现随机自动选号 Enumerable.Range(, ).Select(x ...
- 【Linux】Linux相关资料
linux相关技术资料: linux技术资料大全: http://t.cn/zYNBwFs
- ZooKeeper学习第五期--ZooKeeper管理分布式环境中的数据(转)
转载来源:https://www.cnblogs.com/sunddenly/p/4092654.html 引言 本节本来是要介绍ZooKeeper的实现原理,但是ZooKeeper的原理比较复杂,它 ...
- JVM检测&工具
前几篇篇文章介绍了介绍了JVM的参数设置并给出了一些生产环境的JVM参数配置参考方案.正如之前文章中提到的JVM参数的设置需要根据应用的特性来进行设置,每个参数的设置都需要对JVM进行长时间的监测,并 ...
- webpack打包(一)
1.安装webpack打包工具 webpack是使用npm安装 npm install webpack -g //全局安装 在命令行中就可以使用webpack这个命令了. 提示:由于npm安装会去找国 ...
- Codeforces Round #569 (Div. 2)A. Alex and a Rhombus
A. Alex and a Rhombus 题目链接:http://codeforces.com/contest/1180/problem/A 题目: While playing with geome ...
- 面试超火题 This的问题!!!
this问题 (1)this是js的一个关键字,指定一个对象,然后替代this: 函数中的this指向行为发生的主体,函数外的this都指向window,没有意义 (2)函数内的this跟函数在什么环 ...