Hive部分函数解析
Hive部分函数解析
Hive里的exists ,in ,not exists ,not in 相关函数
表数据准备:
1.选择指定数据库 eg: use bg_database1;
2. 创建表
drop table demo0919 ;
create table demo0919(
name string
,age int
,sex int
) row format delimited fields terminated by '\001';
3.插入表数据
insert overwrite table demo0919 values('zs',18,1);
insert into table demo0919 values('ls',18,1);
insert into table demo0919 values('nisa',19,0);
insert into table demo0919 values('rina',22,0);
insert into table demo0919 values('zhaoxi',25,1);
4. 根据原表 demo0919 再创建一张表 demo0919_1,用于比对数据。
create table demo0919_1 as select *from demo0919;
5.查看表数据
select *from demo0919;
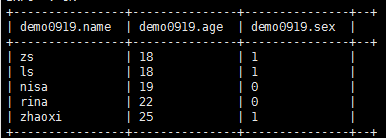
函数测试
in:
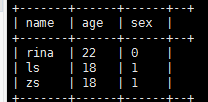
in的简单使用(ok,支持):
select name,age,sex from demo0919 where age in (18,22);
in 里面嵌套子查询 (error ,不支持)
select name,age,sex from demo0919 where age in (select a.age from demo0919_1 a );

not in :
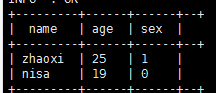
not in 的简单使用(ok, 支持)
select name,age,sex from demo0919 where age not in (18,22);
not in 里面嵌套子查询 (error ,不支持)
select name,age,sex from demo0919 where age not in (select a.age from demo0919_1 a);

exists:
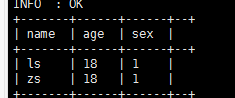
exists 基本使用(ok)
select name,age,sex from demo0919 where exists (select 1 from demo0919_1 a where a.age=18 and demo0919.name = a.name);
exists子查询里面使用了 外表demo0919中的字段 不等于(> , < , >= , <= , <>) 子查询表中的字段(error 不支持)
select name,age,sex from demo0919 where exists (select 1 from demo0919_1 a where a.age>demo0919.age and demo0919.name = a.name);

处理方案:
根据此段我们可以借助left outer join,left semi join 来实现类似功能 前者允许右表的字段在select或where子句中引用,而后者不允许。
(left semi join :需要注意 使用left semi join时 右侧的表不能被使用,只能在on后面作为条件筛选)
select d.name,d.age,d.sex from demo0919 d left outer join demo0919_1 a on d.name = a.name where a.age>d.age;
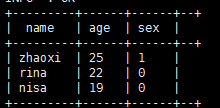
exists子查询里面未使用 外表demo0919中的字段 不等于(> , < , >= , <= , <>) 子查询表中的字段(ok 支持)
select name,age,sex from demo0919 where exists (select 1 from demo0919_1 a where a.age>18 and demo0919.name = a.name);
not exists 与 exist雷同。
Hive数据类型转换函数:
daycount string; daycount表示耗时数据信息,原来定义为string类型
cast(daycount AS FLOAT) 将string类型数据转换为FLOAT类型
Hive日期类型转换函数:
unix_timestamp(countdate) :将日期转换为时间戳, countdate为日期字段
from_unixtime(unix_timestamp(countdate),'yyyy-MM-dd HH:mm:ss') :格式化当前时间
Hive的group by :(这里是因为我们在使用group by时用到了带时分秒的日期字段,hive精确到了毫秒级别,mysql中精确到秒,带有日期字段的数据一起dsitinct 或 group by的时候 数据就会有差异)
因为hive保留了 毫秒位数据,故结果数据会比mysql多
例如: 2019-09-19 12:12:12.1 2019-09-19 12:12:12.2
在hive里面 distinct后这是两个不同的日期 2019-09-19 12:12:12.1 2019-09-19 12:12:12.2
在mysql里面 distinct后 这就是相同的日期了 2019-09-19 12:12:12
Hive部分函数解析的更多相关文章
- [Hive]HiveSQL解析原理
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- hive中解析json数组
-- hive中解析json数组 select t1.status ,substr(ss.col,,) as col ,t3.evcId ,t3.evcLicense ,t3.evcAddress , ...
- hive源代码解析之一hive主函数入口
hive其实做的就是解析一条sql然后形成到mapreduce任务,就是一个代码解释器.hive源代码本身就可以分为ql/metasotre/service/serde 这几块:其中 对于Hive来说 ...
- Hive基本命令解析
1. Hive的分区作用 命令:创建分区 create table t_sz_part(id int, name string) partitioned by (country string) row ...
- hive 元数据解析
在使用Hive进行开发时,我们往往需要获得一个已存在hive表的建表语句(DDL),然而hive本身并没有提供这样一个工具. 要想还原建表DDL就必须从元数据入手,我们知道,hive的元数据并不存放在 ...
- Hive Hadoop 解析 orc 文件
解析 orc 格式 为 json 格式: ./hive --orcfiledump -d <hdfs-location-of-orc-file> 把解析的 json 写入 到文件 ./hi ...
- 如何在 Apache Hive 中解析 Json 数组
我们都知道,Hive 内部提供了大量的内置函数用于处理各种类型的需求,参见官方文档:Hive Operators and User-Defined Functions (UDFs).我们从这些内置的 ...
- hive sql 解析json
在hive中会有很多数据是用json格式来存储的,而我们用数据的时候又必须要将json格式的数据解析成为正常的数据,今天我们就来聊聊hive中是如何解析json数据的. 下面这张表就是json格式的表 ...
- Saiku部分函数解析(八)
Saiku函数解析 1. now() : 获取当前日期 直接使用即可 2. IIF(logic_exp, string, string): IIF判断,logic_exp是逻辑表达式,结果为t ...
随机推荐
- 深入学习CSS3-flexbox布局
学习博客:https://css-tricks.com/snippets/css/a-guide-to-flexbox/ 学习博客:http://caibaojian.com/demo/flexbox ...
- 【Java Web开发学习】Spring MVC 使用HTTP信息转换器
[Java Web开发学习]Spring MVC 使用HTTP信息转换器 转载:https://www.cnblogs.com/yangchongxing/p/10186429.html @Respo ...
- jdk13-新特性预览
一新特性 350: Dynamic CDS Archives(动态CDS档案) 351: ZGC: Uncommit Unused Memory(ZGC:取消提交未使用的内存) 353: Reimpl ...
- Caffe源码-Layer类
Layer类简介 Layer是caffe中搭建网络的基本单元,caffe代码中包含大量Layer基类派生出来的各种各样的层,各自通过虚函数 Forward() 和 Backward() 实现自己的功能 ...
- Internet History,Technology,and Security - Technology: Internets and Packets (Week5)
Week5 Technology: Internets and Packets Welcome to Week 5! This week, we’ll be covering internets an ...
- VueCLi3 配置less变量
Step1. 文档介绍 // vue-cli css预处理文档: https://cli.vuejs.org/zh/guide/css.html#自动化导入 // less文档: https://ww ...
- 使用git将本地java项目上传到GitHub
使用git将项目上传到github(最简单方法) 声明:本人是根据上文给的链接的方式,上传到github上的,亲测有效. 首先你需要一个github账号,所有还没有的话先去注册吧! https://g ...
- IDEA开发、测试、生产环境pom配置及使用
pom文件 一般放在最下面,project里 <!--开发环境.测试环境.生产环境--> <!--生产环境--> <profiles> <profile> ...
- [20191218]降序索引疑问4.txt
[20191218]降序索引疑问4.txt --//前几天优化一个项目,我发现许多表里面有有隐含字段,一般开发很少建立函数索引.我自己检查发现里面存在大量的降序索引.--//我感觉有点奇怪,为什么开发 ...
- Navicat Keygen - 注册机是怎么工作的?
Navicat Keygen - 注册机是怎么工作的? 1. 关键词解释. Navicat激活公钥 这是一个2048位的RSA公钥,Navicat使用这个公钥来完成相关激活信息的加密和解密. 这个公钥 ...