ByteBuf使用实例
之前我们有个netty5的拆包解决方案(参加netty5拆包问题解决实例),现在我们采用另一种思路,不需要新增LengthFieldBasedFrameDecoder,直接修改NettyMessageDecoder:
package com.wlf.netty.nettyapi.msgpack; import com.wlf.netty.nettyapi.constant.Delimiter;
import com.wlf.netty.nettyapi.javabean.Header;
import com.wlf.netty.nettyapi.javabean.NettyMessage;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.ByteToMessageDecoder; import java.util.List; public class NettyMessageDecoder extends ByteToMessageDecoder { /**
* 消息体字节大小:分割符字段4字节+长度字段4字节+请求类型字典1字节+预留字段1字节=10字节
*/
private static final int HEAD_LENGTH = 10; @Override
protected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf, List<Object> list) throws Exception { while (true) { // 标记字节流开始位置
byteBuf.markReaderIndex(); // 若读取到分割标识,说明读取当前字节流开始位置了
if (byteBuf.readInt() == Delimiter.DELIMITER) {
break;
} // 重置读索引为0
byteBuf.resetReaderIndex(); // 长度校验,字节流长度至少10字节,小于10字节则等待下一次字节流过来
if (byteBuf.readableBytes() < HEAD_LENGTH) {
byteBuf.resetReaderIndex();
return;
}
} // 2、获取data的字节流长度
int dataLength = byteBuf.readInt(); // 校验数据包是否全部发送过来,总字节流长度(此处读取的是除去delimiter和length之后的总长度)-
// type和reserved两个字节=data的字节流长度
int totalLength = byteBuf.readableBytes();
if ((totalLength - 2) < dataLength) { // 长度校验,字节流长度少于数据包长度,说明数据包拆包了,等待下一次字节流过来
byteBuf.resetReaderIndex();
return;
} // 3、请求类型
byte type = byteBuf.readByte(); // 4、预留字段
byte reserved = byteBuf.readByte(); // 5、数据包内容
byte[] data = null;
if (dataLength > 0) {
data = new byte[dataLength];
byteBuf.readBytes(data);
} NettyMessage nettyMessage = new NettyMessage();
Header header = new Header();
header.setDelimiter(Delimiter.DELIMITER);
header.setLength(dataLength);
header.setType(type);
header.setReserved(reserved);
nettyMessage.setHeader(header);
nettyMessage.setData(data); list.add(nettyMessage); // 回收已读字节
byteBuf.discardReadBytes();
}
}
我们的改动很小,只不过将原来的读索引改为标记索引,然后在拆包时退出方法前重置读索引,这样下次数据包过来,我们的读索引依然从0开始,delimiter的标记就可以读出来,而不会陷入死循环了。
ByteBuf是ByteBuffer的进化版,ByteBuffer(参见ByteBuffer使用实例)才一个索引,读写模式需要通过flip来转换,而ByteBuf有两个索引,readerIndex读索引和writerIndex写索引,读写转换无缝连接,青出于蓝而胜于蓝:
+-------------------+------------------+------------------+
| discardable bytes | readable bytes | writable bytes |
| | (CONTENT) | |
+-------------------+------------------+------------------+
| | | |
0 <= readerIndex <= writerIndex <= capacity
既然有两个索引,那么标记mask、重置reset必然也是两两对应,上面的代码中我们只需要用到读标记和读重置。
我们把客户端handler也修改下,先把LengthFieldBasedFrameDecoder去掉:
// channel.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024 * 1024 * 1024, 4, 4, 2, 0));
再让数据包更大一些:
/**
* 构造PCM请求消息体
*
* @return
*/
private byte[] buildPcmData() throws Exception {
byte[] resultByte = longToBytes(System.currentTimeMillis()); // 读取一个本地文件
String AUDIO_PATH = "D:\\input\\test_1.pcm";
try (RandomAccessFile raf = new RandomAccessFile(AUDIO_PATH, "r")) { int len = -1;
byte[] content = new byte[1024];
while((len = raf.read(content)) != -1)
{
resultByte = addAll(resultByte, content);
}
} return resultByte;
}
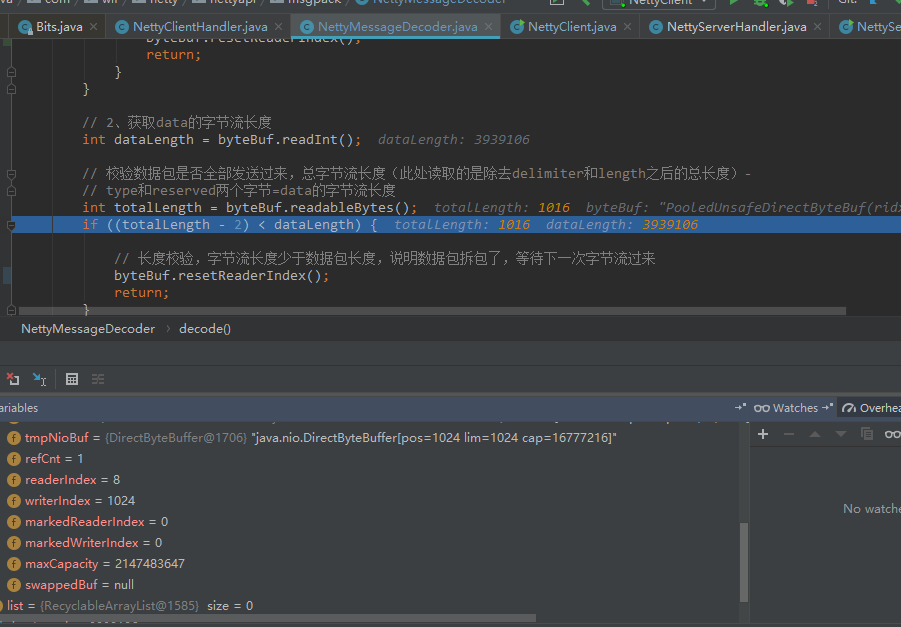
再debug下看看,第一次解析客户端发送的数据,读取1024字节,我们可以看到读索引是8(delimiter+length=8),写索引就是1024,我们的大包里有3939116个字节,去掉10个字节的header,剩下小包是3939106::
第二次再读1024,代码已经执行reset重置读索引了,所以读索引由8改为0,写索引累增到2048:

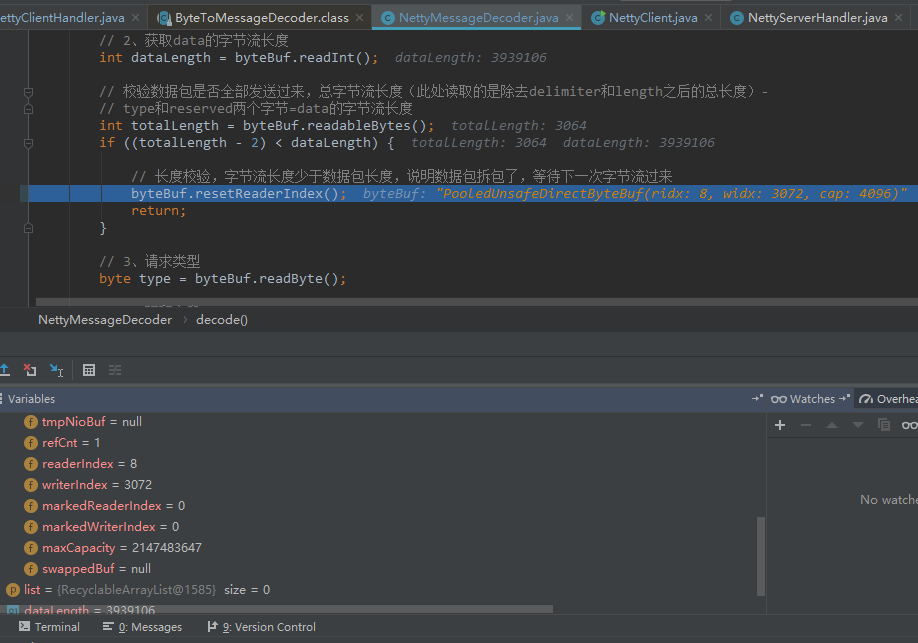
第三次再读1024,写索引继续累增到3072:
最后一次发1024,写索引已经到达3939116,大包传输结束了:
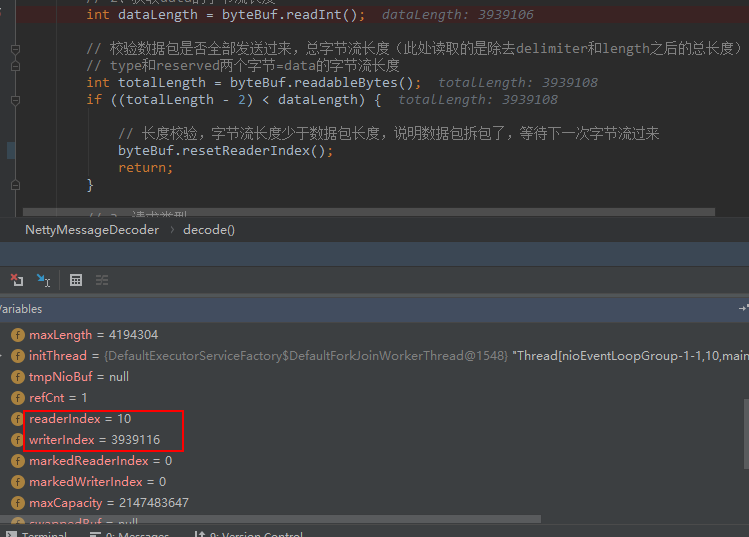
从上面看出,我们对ByteBuf的capacity一直在翻倍,读指针一直标记在大包的起始位置0,这样做的目的是每次都能读取小包的长度length(3939106),拿来跟整个ByteBuf的长度作比较,只要它取到的小包没到达到length,我们就继续接受新包,写索引不停的累加,直到整个大包长度>=3939116(也就是小包>=3939106),这时我们开始移动读索引,将字节流写入对象,最后回收已读取的字节(调用discardReaderBytes方法):
BEFORE discardReadBytes()
+-------------------+------------------+------------------+
| discardable bytes | readable bytes | writable bytes |
+-------------------+------------------+------------------+
| | | |
0 <= readerIndex <= writerIndex <= capacity
AFTER discardReadBytes()
+------------------+--------------------------------------+
| readable bytes | writable bytes (got more space) |
+------------------+--------------------------------------+
| | |
readerIndex (0) <= writerIndex (decreased) <= capacity
其他方法参见测试类:
package com.wlf.netty.nettyserver; import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import org.junit.Assert;
import org.junit.Test; public class ByteBufTest {
@Test
public void byteBufTest() {
ByteBuf byteBuf = Unpooled.buffer(10);
byteBuf.writeInt(0xabef0101);
byteBuf.writeInt(1024);
byteBuf.writeByte((byte) 1);
byteBuf.writeByte((byte) 0); // 开始读取
printDelimiter(byteBuf);
printLength(byteBuf); // 派生一个ByteBuf,取剩下2个字节,但读索引不动
ByteBuf duplicatBuf = byteBuf.duplicate();
printByteBuf(byteBuf); // 派生一个ByteBuf,取剩下2个字节,读索引动了
ByteBuf sliceBuf = byteBuf.readSlice(2);
printByteBuf(byteBuf); // 两个派生的对象其实是一样的
Assert.assertEquals(duplicatBuf, sliceBuf);
} private void printDelimiter(ByteBuf buf) {
int newDelimiter = buf.readInt();
System.out.printf("delimeter: %s\n", Integer.toHexString(newDelimiter));
printByteBuf(buf);
} private void printLength(ByteBuf buf) {
int length = buf.readInt();
System.out.printf("length: %d\n", length);
printByteBuf(buf);
} private void printByteBuf(ByteBuf buf) {
System.out.printf("reader Index: %d, writer Index: %d, capacity: %d\n", buf.readerIndex(), buf.writerIndex(), buf.capacity());
}
}
输出:
delimeter: abef0101
reader Index: 4, writer Index: 10, capacity: 10
length: 1024
reader Index: 8, writer Index: 10, capacity: 10
reader Index: 8, writer Index: 10, capacity: 10
reader Index: 10, writer Index: 10, capacity: 10
ByteBuf使用实例的更多相关文章
- ByteBuf和相关辅助类
当我们进行数据传输的时候,往往需要使用到缓冲区,常用的缓冲区就是JDK NIO类库提供的java.nio.Buffer. 实际上,7种基础类型(Boolean除外)都有自己的缓冲区实现,对于NIO编程 ...
- Netty(7)源码-ByteBuf
一.ByteBuf工作原理 1. ByteBuf是ByteBuffer的升级版: jdk中常用的是ByteBuffer,从功能角度上,ByteBuffer可以完全满足需要,但是有以下缺点: ByteB ...
- 【netty这点事儿】ByteBuf 的使用模式
堆缓冲区 最常用的 ByteBuf 模式是将数据存储在 JVM 的堆空间中. 这种模式被称为支撑数组(backing array), 它能在没有使用池化的情况下提供快速的分配和释放. 直接缓冲区 直接 ...
- Netty实战五之ByteBuf
网络数据的基本单位总是字节,Java NIO 提供了ByteBuffer作为它的字节容器,但是其过于复杂且繁琐. Netty的ByteBuffer替代品是ByteBuf,一个强大的实现,即解决了JDK ...
- Netty 系列三(ByteBuf).
一.概述和原理 网络数据传输的基本单位总是字节,Netty 提供了 ByteBuf 作为它的字节容器,既解决了 JDK API 的局限性,又为网络应用程序提供了更好的 API,ByteBuf 的优点: ...
- ByteBuf源码
ByteBuf是顶层的抽象类,定义了用于传输数据的ByteBuf需要的方法和属性. AbstractByteBuf 直接继承ByteBuf,一些公共属性和方法的公共逻辑会在这里定义.例如虽然不同性质的 ...
- Netty之ByteBuf
本文内容主要参考<<Netty In Action>>,偏笔记向. 网络编程中,字节缓冲区是一个比较基本的组件.Java NIO提供了ByteBuffer,但是使用过的都知道B ...
- Netty学习摘记 —— ByteBuf详解
本文参考 本篇文章是对<Netty In Action>一书第五章"ByteBuf"的学习摘记,主要内容为JDK 的ByteBuffer替代品ByteBuf的优越性 你 ...
- 《Netty in action》 读书笔记
声明:这篇文章是记录读书过程中的知识点,并加以归纳总结,成文.文中图片.代码出自<Netty in action>. 1. 为什么用Netty? 每个框架的流行,都一定有它出众的地方.Ne ...
随机推荐
- LG2662 牛场围栏 和 test20181107 数学题
P2662 牛场围栏 题目背景 小L通过泥萌的帮助,成功解决了二叉树的修改问题,并因此写了一篇论文, 成功报送了叉院(羡慕不?).勤奋又勤思的他在研究生时期成功转系,考入了北京大学光华管理学院!毕业后 ...
- Kafka、ActiveMQ、RabbitMQ、RocketMQ区别
1.区别: Kafka和RocketMQ的区别: 1.两者对于消息的单机吞吐量.时效性.可用性.消息可靠性都差不多,其中时效性就是消息延迟都在ms级,kafka吞吐量会更大. 2.功能支持方面:Kaf ...
- python中的一切皆对象
python中一切皆对象是这个语言灵活的根本.函数和类也是对象,属于python的一等公民.包括代码包和模块也都是对象.python的面向对象更加彻底. 可以赋值给一个变量可以添加到集合对象中可以作为 ...
- javaweb学习笔记(二)
一.javaweb学习是所需要的细节 1.Cookie的注意点 ① Cookie一旦创建,它的名称就不能更改,Cookie的值可以为任意值,创建后允许被修改. ② 关于Cookie中的setMaxAg ...
- NIO原理详解
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/CharJay_Lin/article/d ...
- Kafka ISR and AR HW 、 LEO
相信大家已经对 kafka 的基本概念已经有一定的了解了,下面直接来分析一下 ISR 和 AR 的概念. 0|1ISR and AR 简单来说,分区中的所有副本统称为 AR (Assigned Rep ...
- asp.net MVC 使用wifidog 协议实现wifi认证
在网上看到的很多实现的wifidog 协议一般都是PHP 的,了解一下PHP 但是比较喜欢.net ,所以实现了简单的一个进行登录认证的功能 (好多协议中的功能目前没有实现) 1. 开发环境(vs20 ...
- while循环实现十进制转二进制
#include <stdio.h> int main(void){ int a,n; printf("pls input number:\n"); scanf(&qu ...
- Python中多层List展平为一层
小书匠python 使用Python脚本的过程中,偶尔需要使用list多层转一层,又总是忘记怎么写搜索关键词,所以总是找了很久,现在把各种方法记录下来,方便自己也方便大家. 方法很多,现在就简单写8种 ...
- 从海量文本中统计出前k个频率最高的词语
现有如下题目:有一个海量文本,存储的是汉语词语,要求从中找出前K个出现频率最高的词语,写出最优算法,兼顾时间和空间复杂度. 思路分析:熟悉搜索引擎的程序员,应该不是难题.用传统的HashMap是无法解 ...