CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性
先区分一组概念,parallel和distributed的区别
总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不用考虑通信代价
distributed,要充分的考虑通信代价,failover的问题,更为复杂

Process Model
先解释一下概念,
process model,指数据库系统架构设计,用于支持多用户的并发请求
worker,用于执行客户端tasks的DBMS组件

通常的process model有3种,
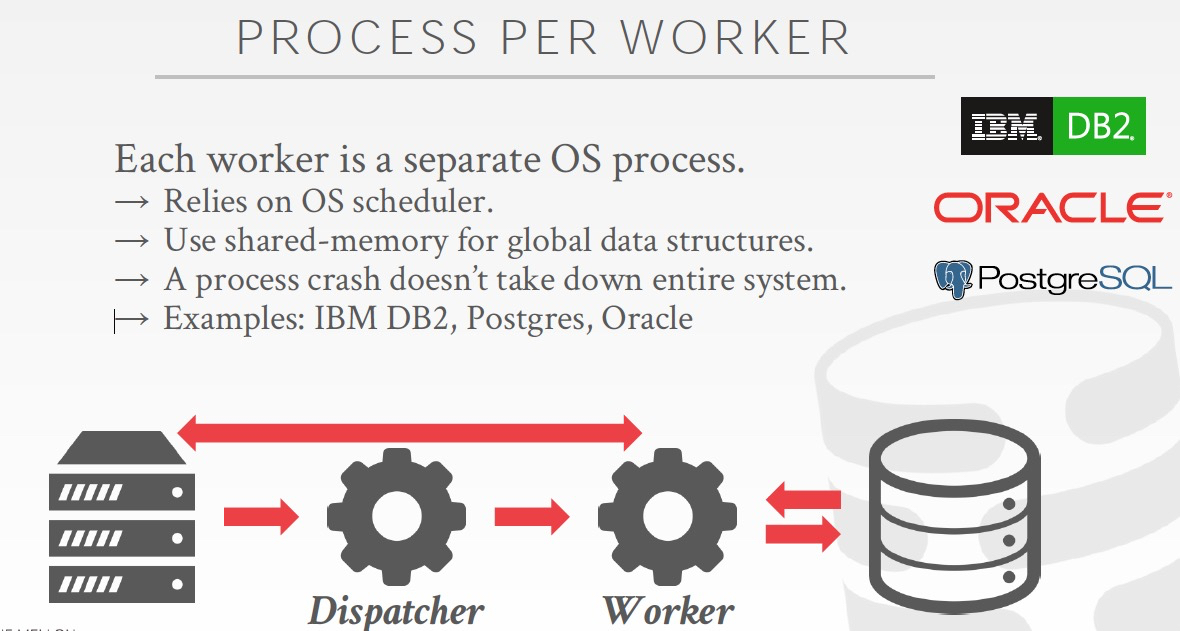
Process Per Worker,每个worker都是一个系统进程,
进程最大优点,隔离好,不会因为一个worker影响整个库,但问题肯定是太重,比较低效,支持不了高并发
早期的数据库往往采用这个方案,是因为那个时候线程的方案还不成熟
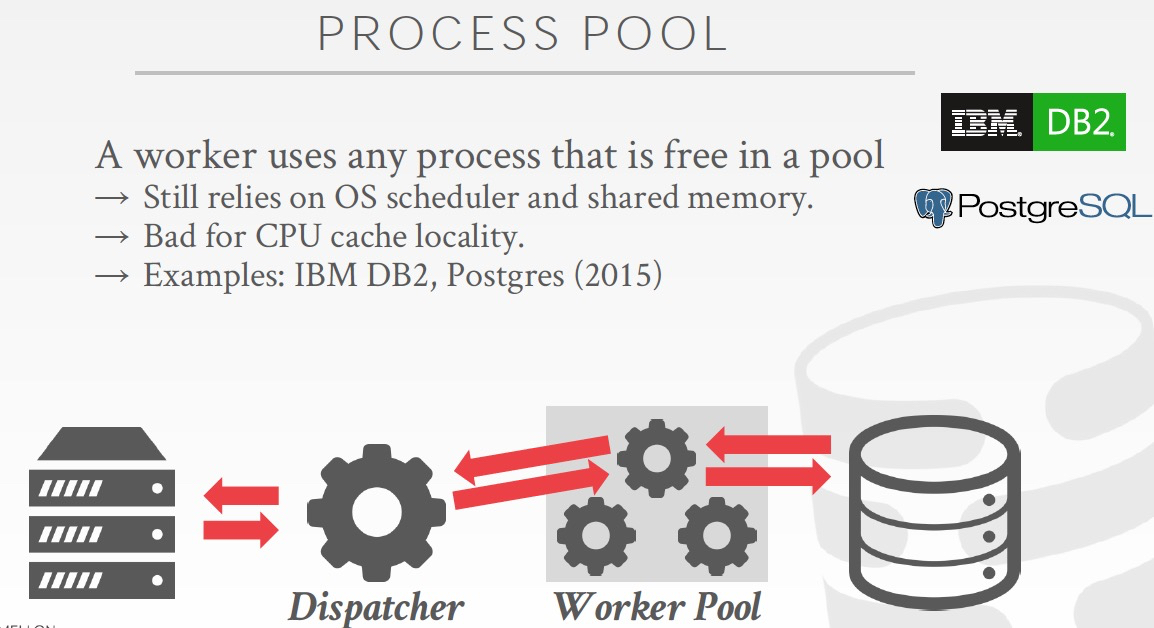
Process Pool,这个方案和上面的没有本质不同,只是worker从只用一个进程,到使用一个进程pool
Pool的好处,一个worker可以同时相应多个请求,而且一个进程hang住了,不会影响worker工作
坏处,一个client的连续的请求会分配到不同的进程,那么CPU cache locality上就不是很好
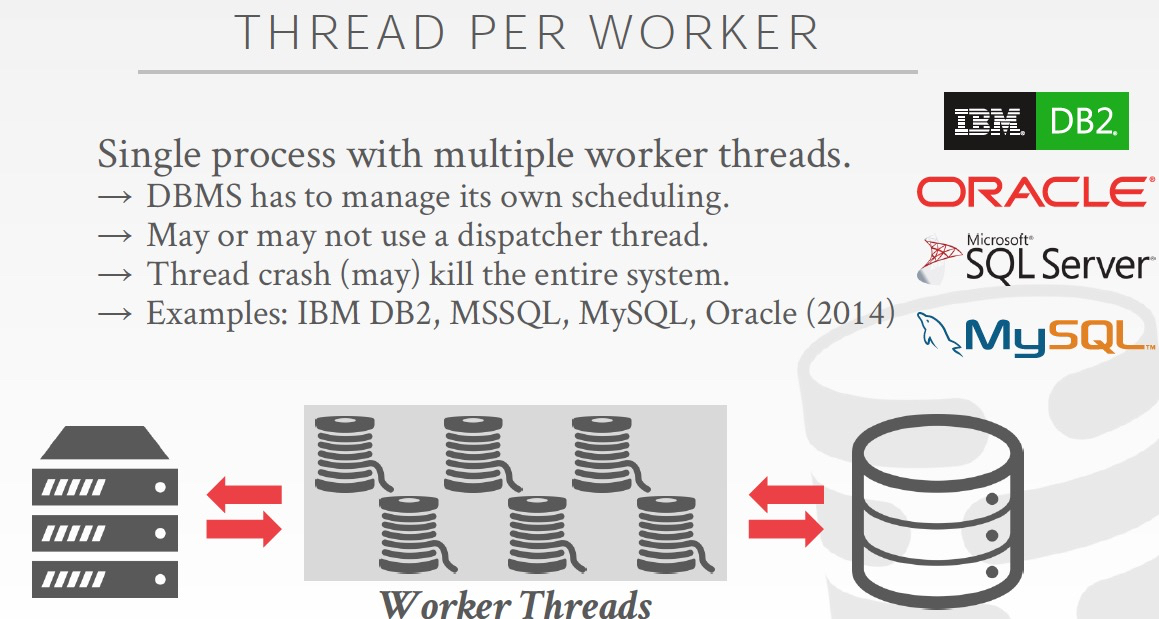
Thread Per Worker
这个是当前主流的process model,
一个数据库实例是一个进程,worker通过线程实现,这样由DBMS自己进行线程调度
线程模型明显更加轻量,更容易应对高并发的场景,而且线程间通信的成本很低
最大的问题是隔离性不好,一个线程可能把整个库搞挂

Parallel Execution
并行有两种,
不同的query,并行的执行
一条query中不同的operation并行的执行

Inter-query,很容易理解,要解决的也就是并发控制问题,这个后面会讲
这里重点说下Intra-query,它也是包含两种类型,Intra-operator和Inter-operator
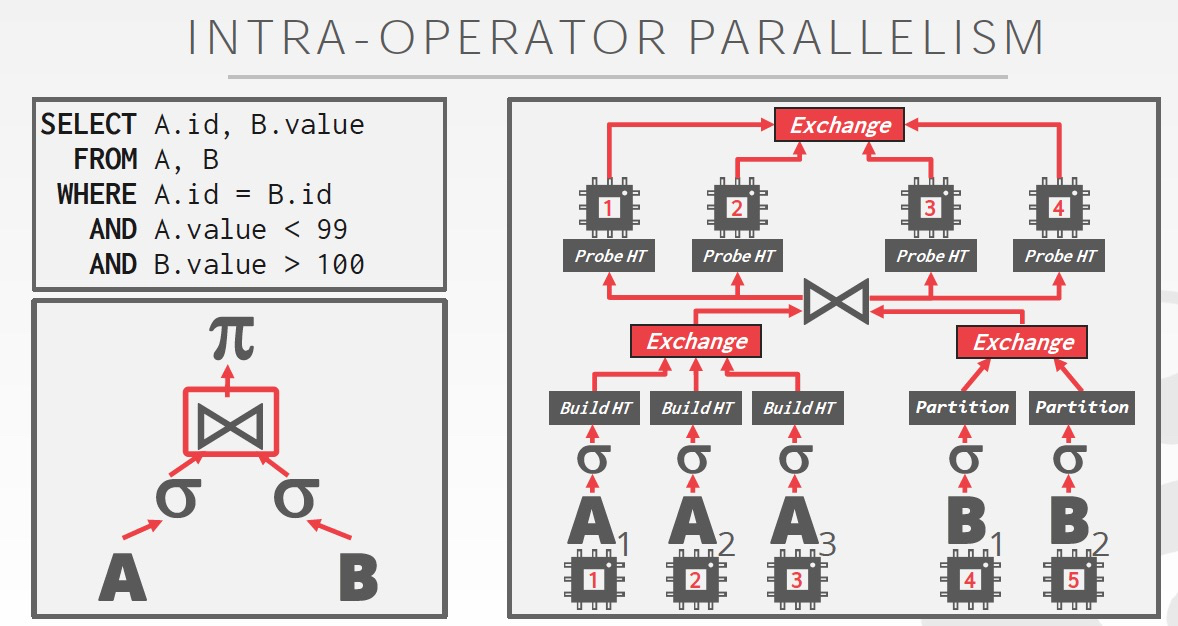
首先是Intra-operator,水平并行,MPP
把数据水平分成多份,分别执行,有个Exchange,类似latch,等待所有分片都执行完,做相应的merge然后再往上发送

然后是,Inter-operator,DAG方式,pipeline,streaming process

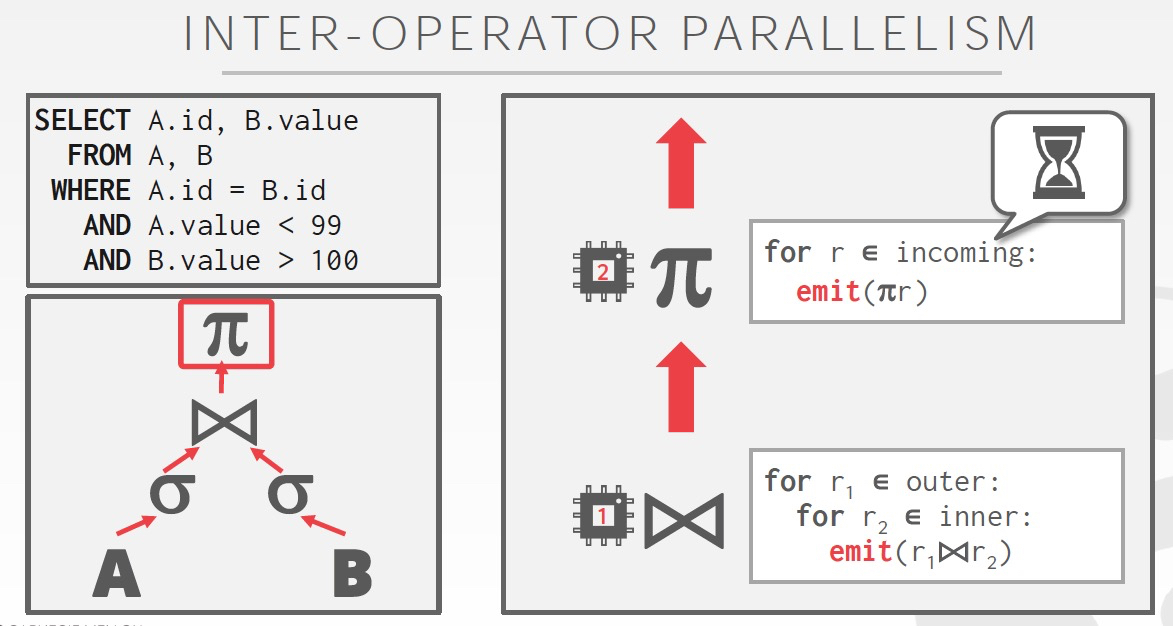
I/O PARALLELISM
前面光说了,平行处理,但是数据库的瓶颈大部分在磁盘IO
所以如果要并行计算,关键是数据要能划分开,并行的读取
一些比较简单的方法如下,
人为的分多块盘,或是用raid0,raid1

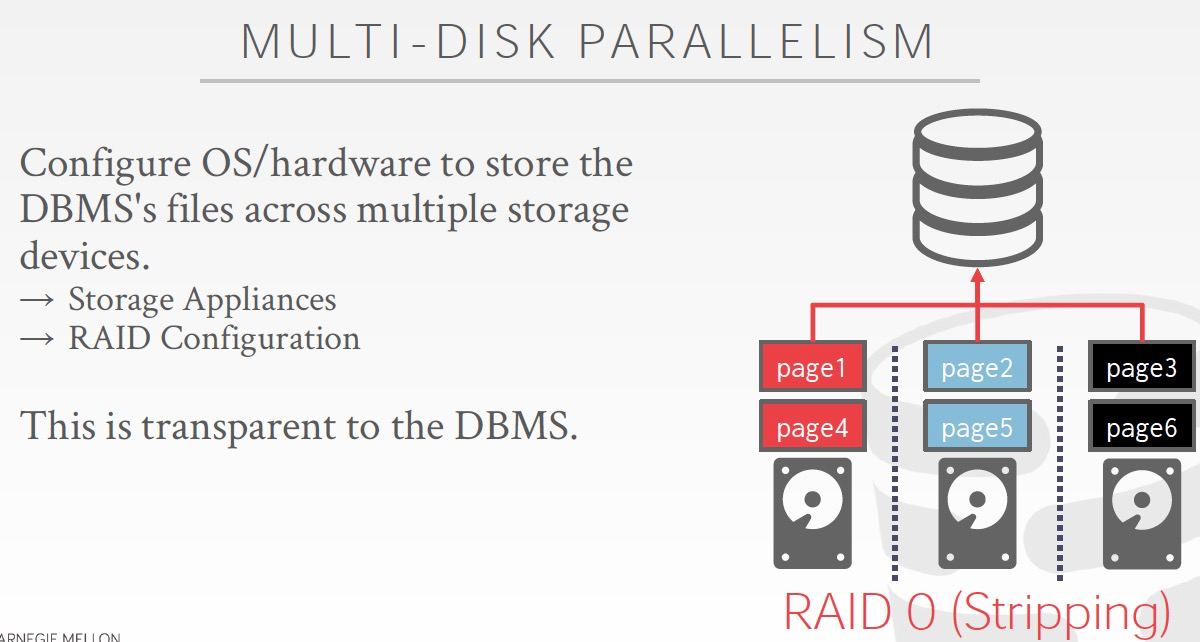
但是如果要在表级别做划分,就需要更为复杂的方法,对数据做partition

划分又分为两种,
垂直划分,列存
水平划分,sharding


CMU Database Systems - Parallel Execution的更多相关文章
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术 对同一个对象不去update,而且记录下每一次的不同版本的值 存在不会消失,新值并不能抹杀原先的存在 所以update操作并不是对世界的真实反映,这是一种 ...
- CMU Database Systems - Embedded Database Logic
正常应用和数据库交互的过程是这样的, 其实我们也可以把部分应用逻辑放到DB端去执行,来提升效率 User-defined Function Stored Procedures Triggers Cha ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
随机推荐
- mysql:[Err] 1068 - Multiple primary key defined
添加主键时,出现错误:[Err] 1068 - Multiple primary key defined #增加主键 ) not null; ; alter table my_test add pri ...
- Exchange 退信550 5.1.11 RESOLVER.ADR.ExRecipNotFound
问题描述: 在Exchange 2013环境下,某客户将一个用户的邮箱test@abc.com禁用,过了几天又想连接该邮箱,但是却没有找到禁用的邮箱,然后客户就Enable-MailBox重新创建了一 ...
- Apache实验-目录别名
一.作用介绍 在一些情况下,我们的资源文件都在非/var/www/html目录下,例如/var/www/html/sohu.这样的话我们在输入网址的时候就需要在网站根目录下再输入完整的目录.所以我们可 ...
- minhash pyspark 源码分析——hash join table是关键
从下面分析可以看出,是先做了hash计算,然后使用hash join table来讲hash值相等的数据合并在一起.然后再使用udf计算距离,最后再filter出满足阈值的数据: 参考:https:/ ...
- Java精通并发-wait与notify及线程同步系统总结
notifyAll(): 在上两次中对于Object的wait()和notify()方法的官方doc进行了通读,上一次https://www.cnblogs.com/webor2006/p/11407 ...
- P1392 取数[堆]
题目描述 在一个n行m列的数阵中,你须在每一行取一个数(共n个数),并将它们相加得到一个和.对于给定的数阵,请你输出和前k小的取数方法. 解析 写这题完全自闭. 根本没联想起远古时期做的 P1631 ...
- Failed to bind properties under 'logging.level' to java.util.Map<java.lang.String, java.lang.String>
org.springframework.boot.context.properties.bind.BindException: Failed to bind properties under 'log ...
- 再论strlen sizeof
今天,在使用字符串的时候,对sizeof和strlen的用法更加深入了,特此记录下. strlen是运行是计算的,不能放在函数外面计算的sizeof是预编译时运行的,可以放在函数外面计算. 对于cha ...
- UVA 1672不相交的正规表达式
题意 输入两个正规表达式,判断两者是否相交(即存在一个串同时满足两个正规表达式).本题的正规表达式包含如下几种情况: 单个小写字符 $c$ 或:($P | Q$). 如果字符串 $s$ 满足 $P$ ...
- go设置使用多少个cpu
package main import ( "fmt" "runtime" ) func main() { n := runtime.NumCPU() fmt. ...