CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic
当前查询优化,主要有两种思路,
Rules-based,基于先验知识,用if-else把优化逻辑写死
Cost-based,试图去评估各个查询计划的cost,选取cost比较小的
一个sql query的处理流程,
先是Parser,生成抽象语法树ast,Binder会去做元数据对应,把parse出来的name对应到数据库中的结构,表,字段等
然后Rewriter就是Rules-based的改写,而Optimizer是cost-based的优化


Relational Algebra Equivalences
做查询优化的前提是,查询的结果是不能变的
无论你查询怎么优化,最终得到的结果是一样的,那么就称他们是,关系代数等价
对于不同的operator,有些通用的优化rules,
这里给些例子,
Selections
对于selection,尽量下推,谓词下推,尽量早做


Projections
projection也是应该尽早去做,不需要的字段就根本不用读出来

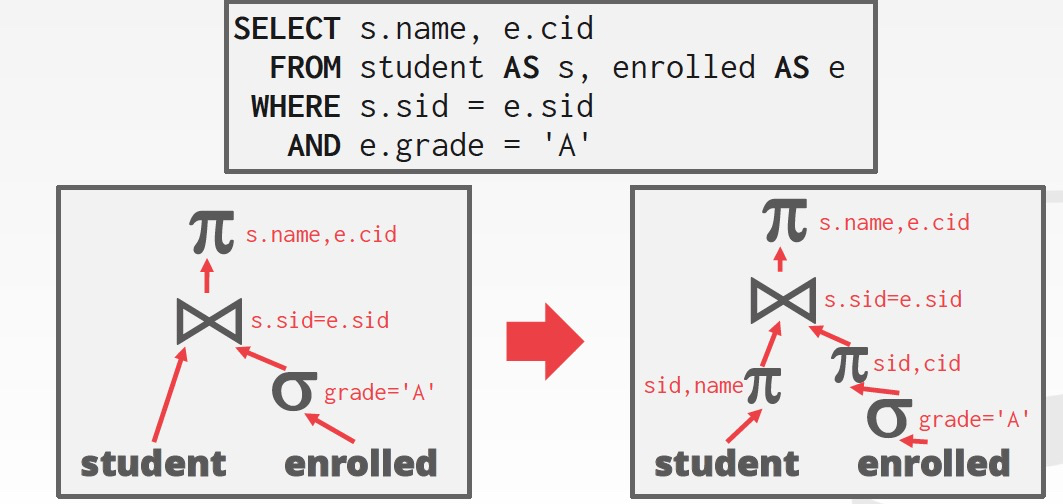
Joins
对于Join是符合交换律和结合律的,但是对于多表join,你需要尝试的可能性是非常多的

Cost Estimation
cost-based的查询优化,关键就是要能够知道cost
如何预估cost是很复杂的问题
当前的思路,就是我们会事先对数据表,列,索引做些统计,并存储到catalog里面,然后后面就根据这些统计数据来预估cost


主要的统计数据,包含两项,行数和每一列的distinct values的个数
然后有个概念,selection cardinality,两个相除,就是平均每个value多少行
这里的假设是数据是均匀分布,很naive


有了这些概念,我们就可以来定义复杂谓词,操作,的selectivity,筛选率

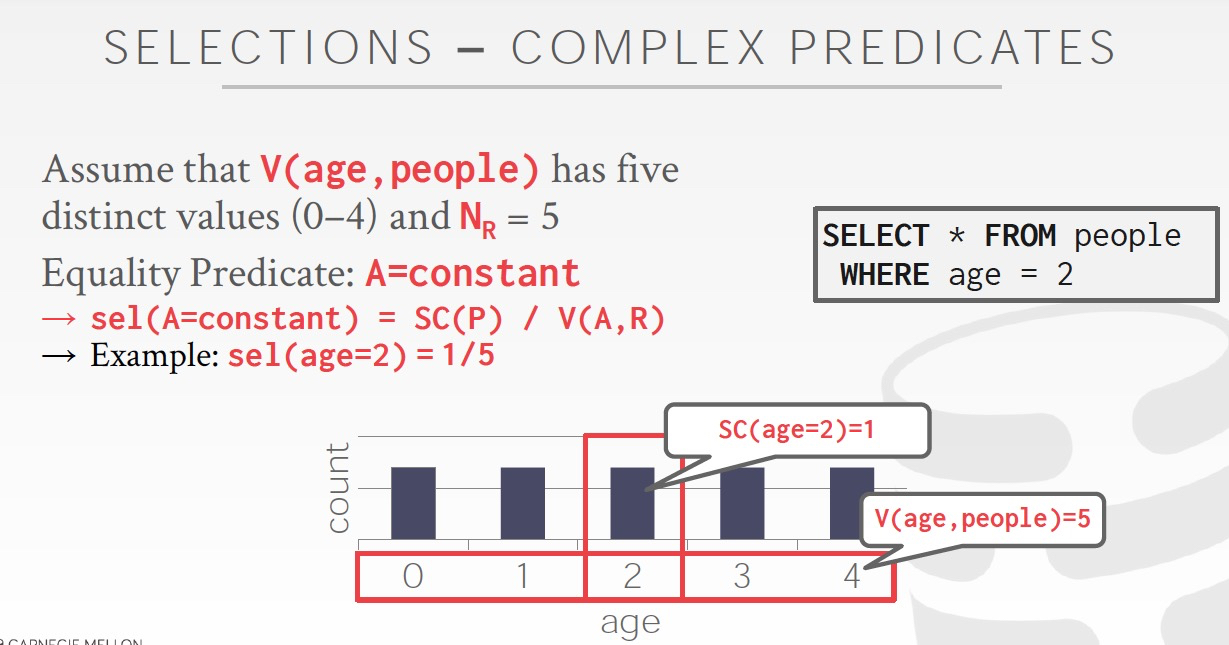
Equality,Range
Equality的定义有些confuse,SC(P),SC(age=2)啥意思?
其实以range的逻辑看,这里就应该是,A列一共有5个值,当前Equality只取其中一个,所以五分之一,就这么简单


Conjunction和Disjunction
右图中,应该是 - sel(P1 交 P2)


Join,对于join,这个cost算的很粗糙,比如R表中的行数 * 每行在S中的cardinality

平均分布问题
当前算cost,都是假设平均分布,这个明显是很不合理的
但是如果对于每个value都去记录一个统计,明显不可行,太多了
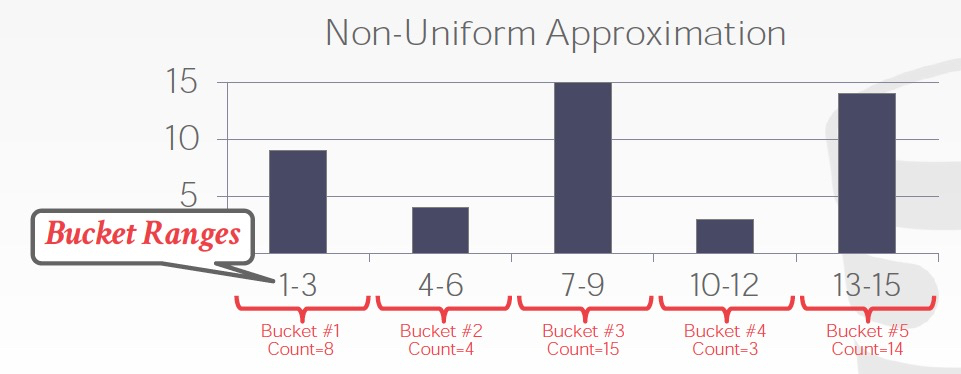
所以有如下几种近似方法,
一种,每个value bucket都去统计太多,那就分组,这样每个组记录一个统计,组内仍然假设平均分布
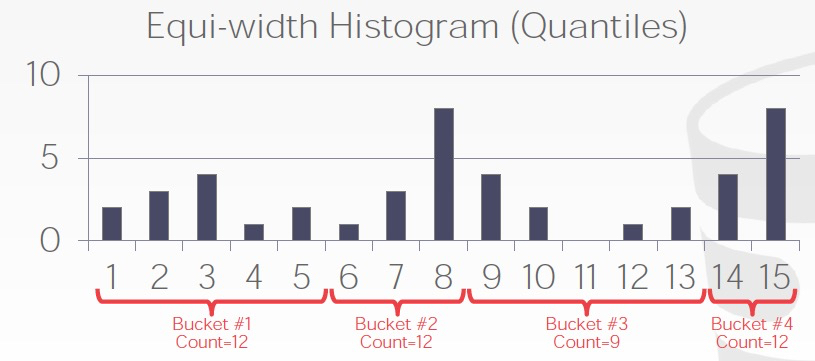
分组可以有两种方式,第一个是固定bucket数,或者固定组内bucket统计和差不多,叫等宽
还有种更直接的方式,sampling
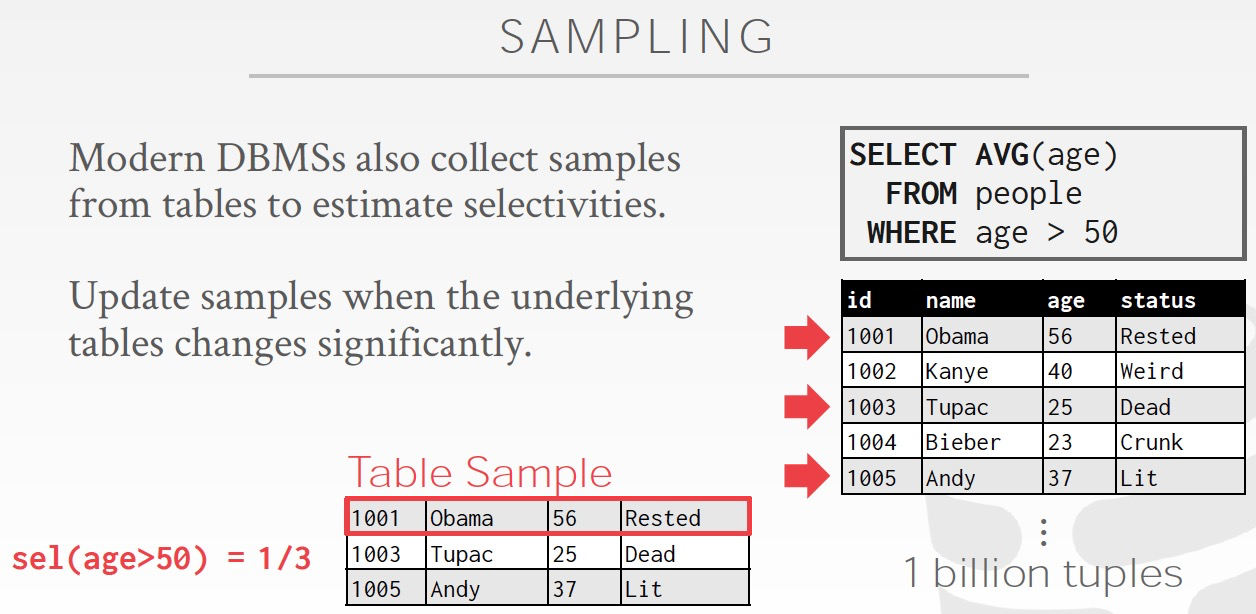
Query Optimization
上面说的cost estimation的方法都很naive,但是如果我们能准确的预估执行计划的cost,那么如何真正的做查询优化?
这里分为三种情况,
Single Relation,Multiple relations, Nested Sub-queries
Single Relation,比较简单,单关系表的查询
所以关键就是选择合理的access method,是顺序扫描,还是用各种索引
这里有个概念,sargable,数据库专有概念,意思是查询或执行计划可以用索引来优化的
OLTP的查询往往都是sargable的,所以通过简单的启发式的方式就可以找到优化方法


Multiple relations
多关系表join就比较复杂了
除了要选择各个表的access method
还需要选择各个表的join顺序和join算法
其中选择join顺序是个cost很高的事情,因为可能性和search space会比较的大
这里介绍IBM R的方法,它把join顺序简化成,只考虑Left-deep tree(右图最左边这个)
这样search space会大幅缩小,另外特意选择left-deep tree的原因是,这种join结构,比较容易pipeline执行,比如下图,a b的join结果直接可以用于和c join,当中间结果不是很大的时候,不需要不断地的把结果写到磁盘


对于Multiple relations,可以尝试用动态规划来选择best plan



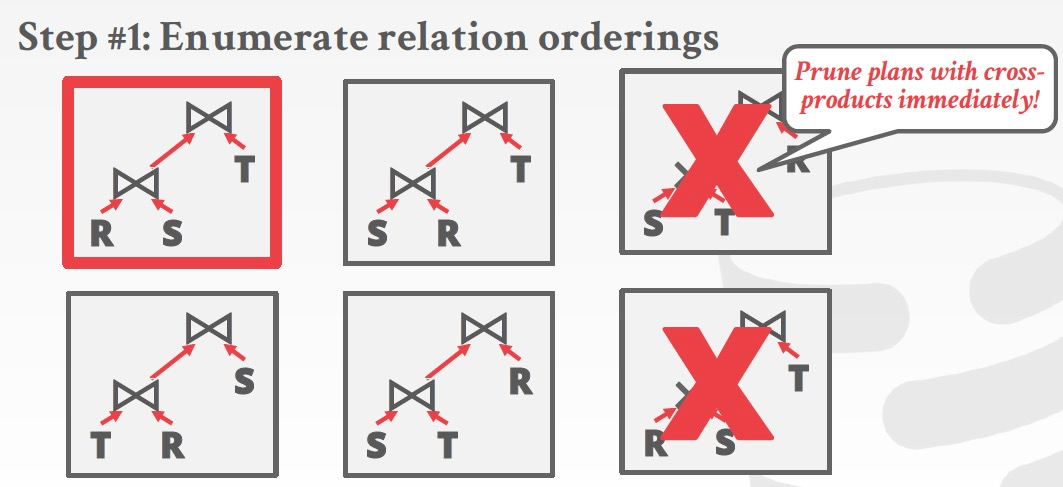
更为形象的例子来说明如何逐步筛选plan
第一步是选择join的顺序,可以首先把明显低效的,比如做cross-products的Prune掉
然后根据cost model找出best的plan
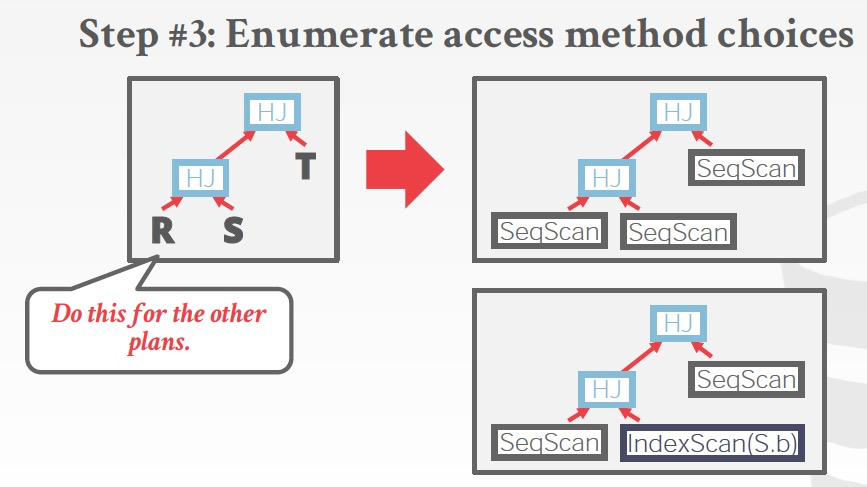
第二步是选择join算法,这里有Nested Loop和Hash Join

第三步是选择access method,
Nested Sub-queries
第三种更为复杂一些,在有子SQL的时候,如何优化?
有两种方式,一种是通过rewrite,把嵌套的子语句flatten掉,如右图的例子


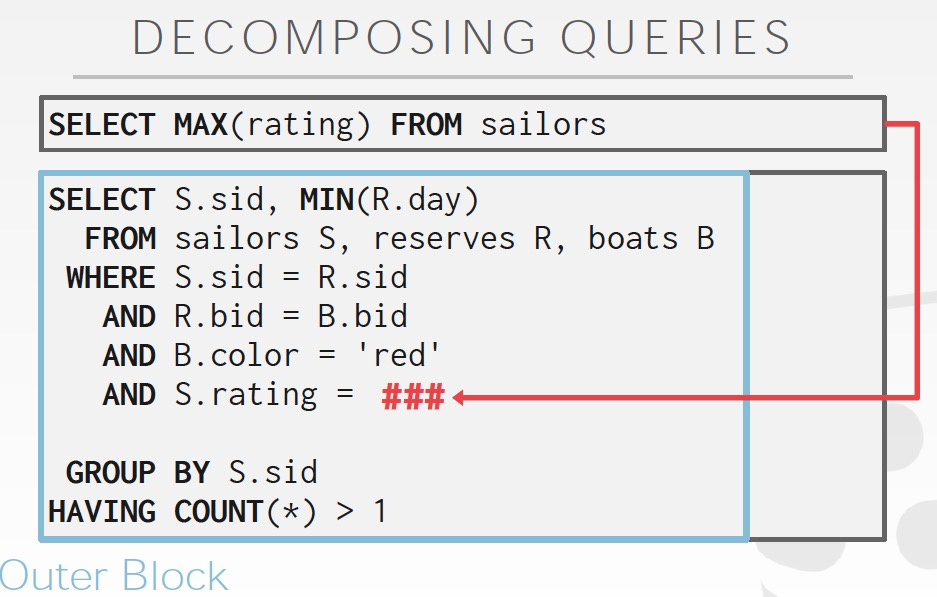
另一种方法,是decompose,如下面的例子
子句是要获取最大的rating,这个反复去执行一定是低效的,所以,干脆把这个语句拿出来单独执行,结果放在临时表,然后执行主语句的时候把值填回去

CMU Database Systems - Query Optimization的更多相关文章
- CMU Database Systems - Query Processing
Query Model Query处理有三种方式, 首先是Iterator model,这是最基本的model,又称为volcano,pipeline模式 他是top-down的模式,通过next函数 ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性 先区分一组概念,parallel和distributed的区别 总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不 ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术 对同一个对象不去update,而且记录下每一次的不同版本的值 存在不会消失,新值并不能抹杀原先的存在 所以update操作并不是对世界的真实反映,这是一种 ...
随机推荐
- Linux的环境配置文件----.bashrc文件(转)
Linux的环境配置文件----.bashrc文件 .bashrc文件主要保存个人的一些个性化设置,如命令别名.路径等.也即在同一个服务器上,只对某个用户的个性化设置相关.它是一个隐藏文件,需要使 ...
- 【转】VC和VS的区别
各个版本之间的对应关系 使用windows平台搞开发时,下载第三方库时经常会遇到文件名以VCxx版本号命令,VC版本如何转换成对应的VS的版本呢,这里总结一下vc和vs的关系. Microsoft V ...
- Linux磁盘管理——Ext2文件系统
前言 通常而言,对于一块新磁盘我们不是直接使用,而是先分区,分区完毕后格式化,格式化后OS才能使用这个文件系统.分区可能会涉及到MBR和GPT问题.至于格式化和文件系统又有什么关系? 这里的格式化指的 ...
- mysqldump 备份与恢复数据库
备份数据库 mysqldump -u root -plvtao test > /home/bak.sql 数据库还原,常用source 命令登陆 mysql -u root -p mysql&g ...
- SQL server分页的四种方法
SQL server分页的四种方法 1.三重循环: 2.利用max(主键); 3.利用row_number关键字: 4.offset/fetch next关键字 方法一:三重循环思路 先取前20页, ...
- typescript 接口
接口:用来建立某种代码约定,使得其他开发者在调用某个方法或创建新的类时必须遵循接口所定义的代码约定 在js里面没有接口这个概念,在ts里面通过两个关键字来支撑接口这个特性 interface ...
- 李航-统计学习方法-笔记-3:KNN
KNN算法 基本模型:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例.这k个实例的多数属于某个类,就把输入实例分为这个类. KNN没有显式的学习过程. KNN使用的模型 ...
- Alluxio : 开源分布式内存文件系统
Alluxio : 开源分布式内存文件系统 Alluxio is a memory speed virtual distributed storage system.Alluxio是一个开源的基于内存 ...
- linux系统编程之进程(三)
今天继续学习进程相关的东东,继上节最后简单介绍了用exec函数替换进程映像的用法,今天将来深入学习exec及它关联的函数,话不多说,正式进入正题: exec替换进程映象: 对于fork()函数,它 ...
- 行为型模式(七) 策略模式(Stragety)
一.动机(Motivate) 在软件构建过程中,某些对象使用的算法可能多种多样,经常改变,如果将这些算法都编码到对象中,将会使对象变得异常复杂:而且有时候支持不使用的算法也是一个性能负担.如何在运行时 ...