python的深浅拷贝-成为马老师的弟子
参考链接
前提
想要了解深浅拷贝之前必须要知道可变和不可变类型,和他们的特性
不可变类型
数字 字符串 元组 不可变集合
特性:改变值,会创建新的内存空间存储数据
可变类型
列表 字典 可变列表
特性:改变值,还是引用之前的内存空间
Python引用赋值
开篇
引用赋值其实就是=,多个变量指向同一个内存空间
不可变案例
#a指向1000的内存地址
a = 1000
#b也指向1000的内存地址
b = a
#a指向了2000的地址,b指向1000的内存地址
a = 2000
可变案例
L = [333,444,555]
L[1] = 4444
#L的地址是没有变化的,但是L[1]的地址发生的变化
列表的内存
列表的内存结构图,第一层的地址是不会随内容的改变而改变的
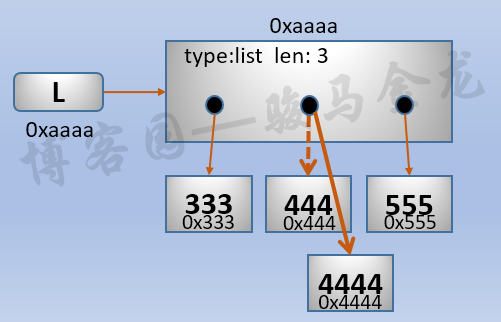
Python深浅拷贝
注意
深浅拷贝这个概念其实是针对可变数据类型的,不可变类型就没有这个概念
深浅拷贝概念
浅拷贝
shallow copy,只拷贝第一层的数据。copy模块的copy()就是浅拷贝
深拷贝
deep copy,递归拷贝所有层次的数据,python中copy模块的deepcopy()是深拷贝
浅拷贝
只拷贝了第一层的数据,存放在另一个空间
马老师亲手给我画的图
为下列代码的内存分布图

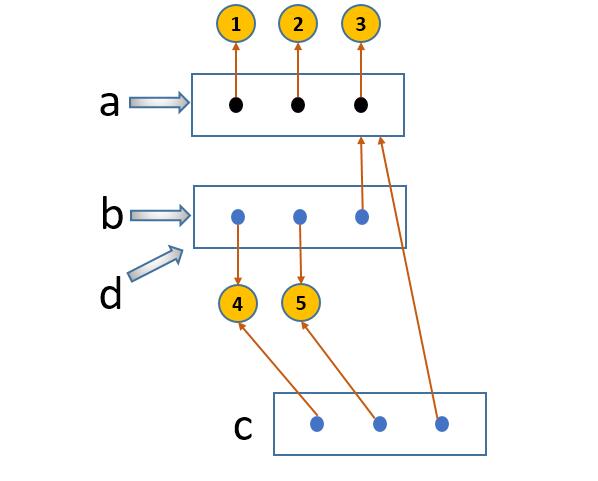
from copy import copy
a = [1,2,3]
b = [4,5,a]
c = copy(b)
#查看id
#id不同.第一层是完全独立的
print(id(b),id(c))
#第二层还是引用的同一个列表
b[2][0] = 200
print(id(b[2]),id(c[2]))
1800001515976 1799717541960
1800000907528 1800000907528
深拷贝
完全拷贝,两个空间是完全独立的,没有一点关系了
from copy import deepcopy
a = [1,2,3]
b = [4,5,a]
c = deepcopy(b)
#全部独立
print(id(b),id(c))
print(id(b[2]),id(c[2]))
2214201160136 2216093571144
2214200551688 2214201162312
python的深浅拷贝-成为马老师的弟子的更多相关文章
- Python原理 -- 深浅拷贝
python原理 -- 深浅拷贝 从数据类型说开去 str, num : 一次性创建, 不能被修改, 修改即是再创建. list,tuple,dict,set : 链表,当前元素记录, 下一个元素的位 ...
- Python的深浅拷贝
Python的深浅拷贝 深浅拷贝 1. 赋值,对于list, set, dict来说, 直接赋值. 其实是把内存地址交给变量并不是复制一份内容 list1 = [']] list2 = list1 p ...
- 24、简述Python的深浅拷贝以及应用场景
深浅拷贝的原理 深浅拷贝用法来自copy模块. 导入模块:import copy 浅拷贝:copy.copy 深拷贝:copy.deepcopy 字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝 ...
- Python入门-深浅拷贝
首先我们在这里先补充一下基础数据类型的一些知识: 一.循环删除 1.前面我们学了列表,字典和集合的一些操作方法:增删改查,现在我们来看一下这个问题: 有这样一个列表: lst = ['周杰伦','周润 ...
- day2学python 数据类型+深浅拷贝+循环
数据类型+深浅拷贝+循环 别的语言的数组 python不用定义 直接使用 color=['红','橙','黄','绿','青','蓝','紫'] print(color[1:3]) //打印[1,3) ...
- 简述Python的深浅拷贝以及应用场景
深浅拷贝的原理 深浅拷贝用法来自copy模块. 导入模块:import copy 浅拷贝:copy.copy 深拷贝:copy.deepcopy 字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝 ...
- python 赋值 深浅拷贝
深浅拷贝 一.数字和字符串 对于 数字 和 字符串 而言,赋值.浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 impor ...
- Python随笔---深浅拷贝
Python中为了避免某些方法的副作用(拷贝后有时更改原有数据),故存在有深浅拷贝的存在 浅拷贝导入copy方法集,使用copy_copy的方法进行 深拷贝一样导入copy方法集,使用copy_dee ...
- python 的深浅拷贝问题
深浅拷贝概念 基本类型和引用类型数据拷贝的问题.因为基本类型的数据大小是固定的,所以他保存在栈内存中:而引用类型的数据大小不固定,因而保存在堆内存中,单引用类型在栈内存中只保存一个指向堆内存的指针. ...
随机推荐
- 本机与虚拟机Ping不通
关闭防火墙,设置虚拟机和本机在同一网段,还是ping不同 解决方法:在VMware中点击 编辑---->虚拟网络编辑器----->更改设置 ------->还原默认设置 然后重新配置 ...
- 基于Proxy的小程序状态管理
摘要: 小程序状态管理. 作者:wwayne 原文:基于Proxy的小程序状态管理 Fundebug经授权转载,版权归原作者所有. 微信小程序的市场在进一步的扩大,而背后的技术社区仍在摸索着最好的实践 ...
- SAP 同一个序列号可以同时出现在2个不同的HU里?
SAP 同一个序列号可以同时出现在2个不同的HU里? 答案是可以的. 如下图示,HU 180141003288里的序列号11810010540121, 而序列号11810010540121已经出现在另 ...
- Android自定义圆角矩形进度条2
效果图: 或 方法讲解: (1)invalidate()方法 invalidate()是用来刷新View的,必须是在UI线程中进行工作.比如在修改某个view的显示时, 调用invalidate()才 ...
- Spring Cloud Eureka的自我保护模式与实例下线剔除
之前我说明了Eureka注册中心的保护模式,由于在该模式下不能剔除失效节点,故按原有配置在实际中不剔除总感觉不是太好,所以深入研究了一下.当然,这里重申一下,不管实例是否有效剔除,消费端实现Ribbo ...
- 3-8 pivot操作
数据透视表¶ In [1]: import pandas as pd excelample=pd.DataFrame({'Month':["January","Jan ...
- 今晚,玩一玩linux上的DNS
老哥遇到的问题, 我先按正规方式操作一波. 一,安装dns服务 yum install bind bind-utils -y 二,修改/etc/named.conf文件 options { liste ...
- xenserver 添加和卸载硬盘
最近在浪潮服务器上安了xenserver系统,创建虚拟机,没注意磁盘超负载就重启了服务导致各种坑,一言难尽,忧伤逆流成河啊,所以准备将各种操作整理总结记录下,持续更新ing~~ ...
- shell 字符菜单管理
1.创建一个脚本func.sh 脚本如下func2.sh #!/bin/bash function menu(){ title="My Menu" url="www.la ...
- 201871010101-陈来弟《面相对象程序设计(java)》第十周学习总结
201871010101-陈来弟<面相对象程序设计(java)>第十周学习总结 实验八异常.断言与日志 实验时间 2019-11-1 1.实验目的与要求 (1) 掌握java异常处理技术: ...