python基础-------模块与包(二)
sys模块、logging模块、序列化
一、sys模块
二、logging模块
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='/tmp/test.log',
filemode='w')
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
三、序列化模块
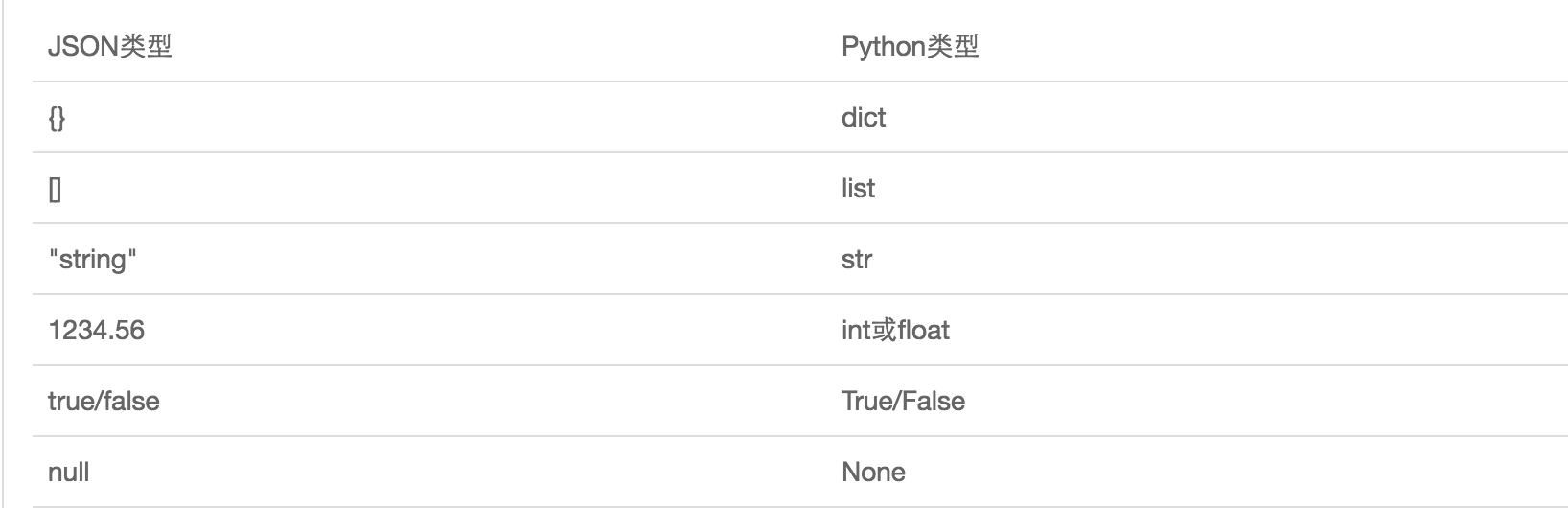
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
data=json.dumps(dic)
print("type",type(data))#<class 'str'>print("data",data)
f=open('序列化对象','w')
f.write(data) #-------------------等价于json.dump(dic,f)f.close()
#-----------------------------反序列化<br>import json
f=open('序列化对象')
new_data=json.loads(f.read())# 等价于data=json.load(f)
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化import pickle
f=open('序列化对象_pickle','rb')
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data['age'])
python基础-------模块与包(二)的更多相关文章
- python基础-------模块与包(一)
模块与包 Python中的py文件我们拿来调用的为之模块:主要有内置模块(Python解释器自带),第三方模块(别的开发者开发的),自定义模块. 目前我们学习的是内置模块与第三方模块. 通过impor ...
- python基础----模块、包
一 模块 ...
- Python基础-模块与包
一.如何使用模块 上篇文章已经简单介绍了模块及模块的优点,这里着重整理一下模块的使用细节. 1. import 示例文件:spam.py,文件名spam.py,模块名spam #spam.py pri ...
- Python基础——模块与包
在Python中,可以用import导入需要的模块.包.库.文件等. 把工作路径导入系统路径 import os#os是工作台 import sys#sys是系统 sys.path.append(os ...
- python基础-------模块与包(四)
configparser模块与 subprcess 利用configparser模块配置一个类似于 windows.ini格式的文件可以包含一个或多个节(section),每个节可以有多个参数(键=值 ...
- python基础-------模块与包(三)正则表达式
re模块正则表达式 正则表达式常用符号: [ re模块使用方法]: match(string[, pos[, endpos]]) | re.match(pattern, string[, flags] ...
- 自学Python之路-Python基础+模块+面向对象+函数
自学Python之路-Python基础+模块+面向对象+函数 自学Python之路[第一回]:初识Python 1.1 自学Python1.1-简介 1.2 自学Python1.2-环境的 ...
- python基础——模块
python基础——模块 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文 ...
- Python 基础教程之包和类的用法
Python 基础教程之包和类的用法 建立一个文件夹filePackage 在filePackage 文件夹内创建 __init__.py 有了 __init__.py ,filePackage才算是 ...
随机推荐
- Pycharm安装、设置、优化
一.版本选择 建议安装5.0版本,因为好注册,这个你懂得. 下载地址: https://confluence.jetbrains.com/display/PYH/Previous+PyCharm+Re ...
- PE格式第四讲,数据目录表之导入表,以及IAT表
PE格式第四讲,数据目录表之导入表,以及IAT表 一丶IAT(地址表) 首先我们思考一个问题,程序加载的时候会调用API,比如我们以前写的标准PE 那么他到底是怎么去调用的? 他会Call 下边的Jm ...
- 关于Websockets问题:
Websockets是一种与服务器进行全双工,双向通信的信道,它不使用http协议,他有自己的协议即自定义协议,ws协议:它的安全协议为wss协议.这种协议专门为快速传输小数据而设计的.对服务其有一 ...
- Access-Control-Allow-Origin与Ajax跨域
问题 在某域名下使用Ajax向另一个域名下的页面请求数据,会遇到跨域问题.另一个域名必须在response中添加 Access-Control-Allow-Origin 的header,才能让前者成功 ...
- ActivityManager与Proxy模式的运用
Android学习——ActivityManager与Proxy模式的运用 一 Proxy模式 意图: 为其他对象提供一种代理以控制这个对象的访问. 适用性: l 远程代理( Remote Prox ...
- 转载:C#特性-表达式树
原文地址:http://www.cnblogs.com/tianfan/ 表达式树基础 刚接触LINQ的人往往觉得表达式树很不容易理解.通过这篇文章我希望大家看到它其实并不像想象中那么难.您只要有普通 ...
- leetcode 697. Degree of an Array
题目: Given a non-empty array of non-negative integers nums, the degree of this array is defined as th ...
- 小星星的php
大家好,我是小星星,最近新学的php,我迫不及待要跟大家分享了!!come on!一起来看小星星的世界 先为大家介绍php基础 首先我们来看看什么叫php: PHP(外文名:PHP: Hypertex ...
- visual studio no editoroptiondefinition export found for the given option nam
今天用VS 2012打开项目,打开项目时,出现以下的bug.解决方法:清理了在C盘用户文件目录下的缓存. 具体的路径是:C:\Users\{当前用户}\AppData\Local\Microsoft\ ...
- SpringMVC + Spring + Mybatis+ Redis +shiro以及MyBatis学习
SpringMVC + Spring + Mybatis+ Redis +shiro http://www.sojson.com/shiro MyBatis简介与配置MyBatis+Spring+My ...