python爬虫scrapy框架——人工识别知乎登录知乎倒立文字验证码和数字英文验证码
原创文章,转载请注明出处!
目前知乎使用了点击图中倒立文字的验证码:
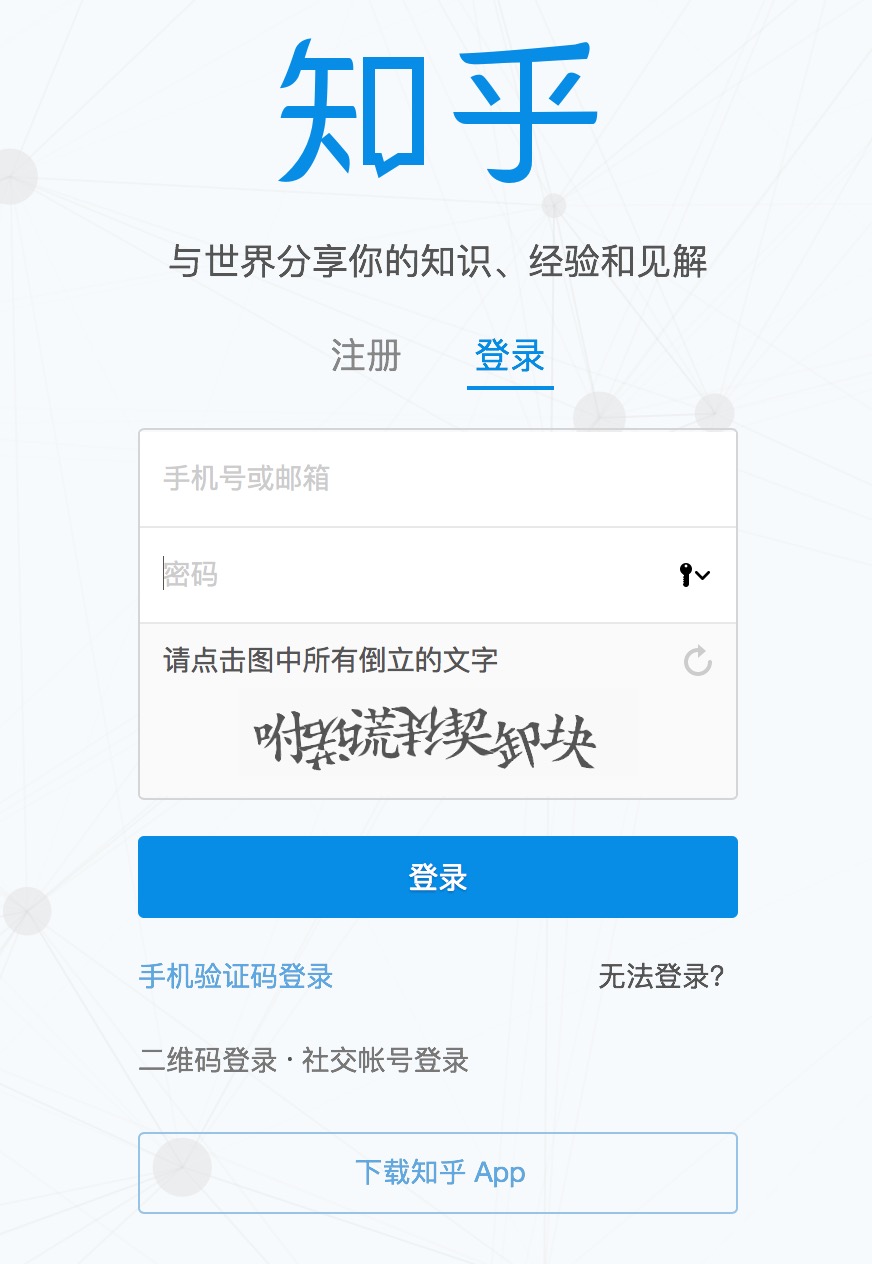
用户需要点击图中倒立的文字才能登录。
这个给爬虫带来了一定难度,但并非无法解决,经过一天的耐心查询,终于可以人工识别验证码并达到登录成功状态,下文将和大家一一道来。
我们学习爬虫首先就要知道浏览器给服务器传输有什么字段(我用的是Safari浏览器进行演示,当然Chrome、Firefox都可以)
我们点击了第一个和第二个文字:
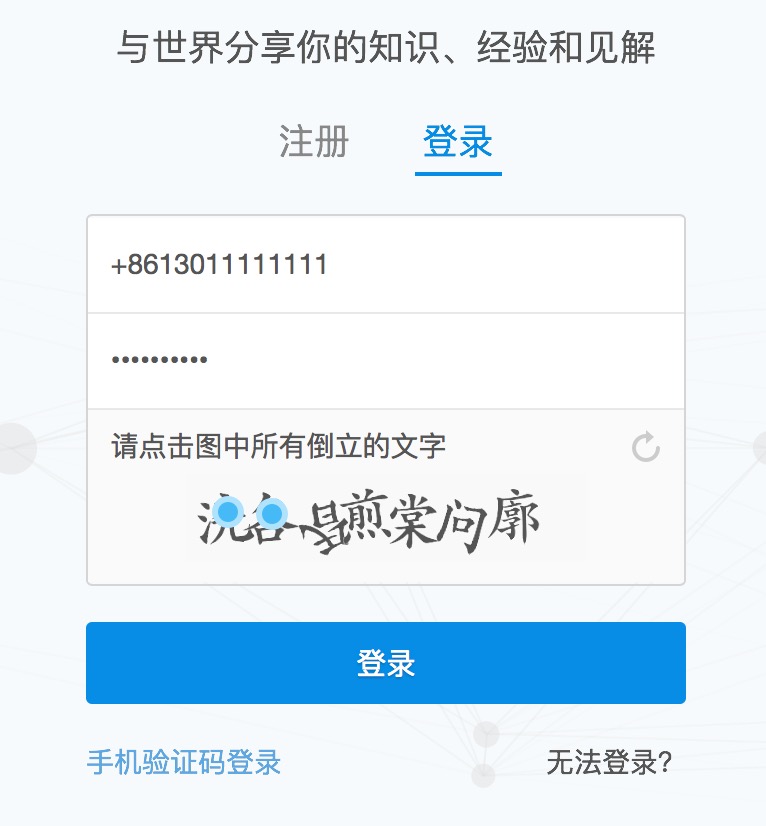
右键审查元素-->点击登录 后可以看到:

从右面可以得到:报文发送的URL是:https://www/zhihu/com/login/phone_num
这不难理解,知乎的登录是把手机和邮箱区分开来,我们用的是手机登录,经过测试邮箱的URL是:https://www/zhihu/com/login/email,这里就不截图了。
把右面的资源往下拉:
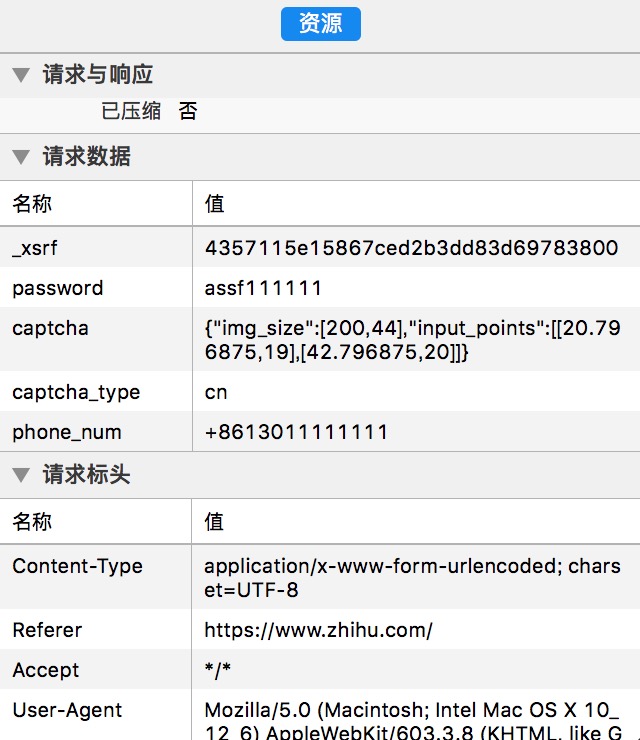
除了phone_num是用户名,password是密码,我们还看到了几个重要信息:_xsrf、captcha、captcha_type
那么重点来了,这都分别是什么意思呢?经过反复查询,直接把简介明了的解释给大家:
_xsrf:是“跨站请求伪造”(CSRF / XSRF)(Cross Site Request Forgery),这是知乎的一个安全协议,当你第一次访问知乎主页www.zhihu.com的时候,知乎会自动往你的浏览器发送一个_xsrf字段并且和你的主机绑定,之后的你每次访问知乎服务器时,你的浏览器都会带上这个字段,知乎发现你发送的_xsrf是我给你的_xsrf时才能有权访问,如果_xsrf错误或者不填都无法访问。顺便一提,这是一个安全机制,基本所有的网站都会设置一个 XSRF/CSRF 的字段,防止黑客攻击。
我们既然知道浏览器每次向知乎发送请求时都会带上_xsrf字段,那么我们的爬虫就必须要模拟浏览器访问知乎首页获取这个 _xsrf 字段并在登录时提交这个字段,才能登录成功。
captcha:里的"img_size"字段是固定的,每次都是[200,44],应该就是图片大小的意思。后面的"input_points"是你点击验证码中倒立文字的坐标,由于验证码中七个文字位置是固定的,我们只要每个字都点一下再进行登录,再审查元素来确定每个字的坐标就能模拟点击了(是不是豁然开朗),这个步骤自行点击来获取坐标,我把我测试好的七个文字坐标依次拿出来:[22.796875,22],[42.796875,22],[63.796875,21],[84.796875,20],[107.796875,20],[129.796875,22],[150.796875,22]。
captcha_type:这个字段就有意思了,其中有一个小技巧来切换成数字英文验证码。如果把它设置成 "cn" 就是倒立文字验证码,设置成 "en" 就是数字英文验证码,我没就这里设置成"cn",数字英文验证码网上很多,大家可自行寻找。(经测试不填这个字段也是数字英文验证码)
到这里思路就很清晰了,我们知道了这三个重要信息,就知道如何让爬虫登录知乎了,不多说直接上代码:
import requests try:
import cookielib
except:
import http.cookiejar as cookielib import re
import time
import json def get_xsrf():
# 获取xsrf code
response = session.get('https://www.zhihu.com', headers=header)
# print(response.text)
match_obj = re.match('[\s\S]*name="_xsrf" value="(.*?)"', response.text)
if match_obj:
return match_obj.group(1)
return '' def get_captcha():
# 验证码URL是按照时间戳的方式命名的
captcha_url = 'https://www.zhihu.com/captcha.gif?r=%d&type=login&lang=cn' % (int(time.time() * 1000))
response = session.get(captcha_url, headers=header)
# 保存验证码到当前目录
with open('captcha.gif', 'wb') as f:
f.write(response.content)
f.close() # 自动打开刚获取的验证码
from PIL import Image
try:
img = Image.open('captcha.gif')
img.show()
img.close()
except:
pass captcha = {
'img_size': [200, 44],
'input_points': [],
}
points = [[22.796875, 22], [42.796875, 22], [63.796875, 21], [84.796875, 20], [107.796875, 20], [129.796875, 22],
[150.796875, 22]]
seq = input('请输入倒立字的位置\n>')
for i in seq:
captcha['input_points'].append(points[int(i) - 1])
return json.dumps(captcha) def zhihu_login(account, password):
# 知乎登录
if re.match('1\d{10}', account):
print('手机号码登录')
post_url = 'https://www.zhihu.com/login/phone_num'
post_data = {
'captcha_type': 'cn',
'_xsrf': get_xsrf(),
'phone_num': account,
'password': password,
'captcha': get_captcha(),
} response_text = session.post(post_url, data=post_data, headers=header)
response_text = json.loads(response_text.text)
if 'msg' in response_text and response_text['msg'] == '登录成功':
print('登录成功!')
else:
print('登录失败') if __name__ == '__main__':
agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8'
header = {
'HOST': 'www.zhihu.com',
'Referer': 'https://www.zhihu.com',
'User-agent': agent,
}
session = requests.session()
zhihu_login('输入登录的手机号', '输入登录密码')
想必大家看代码都能看的懂了,我再简单说一嘴重要的
非常要注意的地方是:必须要用session来请求验证码再用session来提交报文,为什么不能用requests呢?一个session就是一个会话,如果用一个session访问了一个网站,后面再拿着这个session再请求这个网站,它会把网站带给我们的cookie或者说网站放到字段里面的session完全的给带回去,这里面的cookie就非常重要,在我们访问知乎的时候,不管我们有没有登录,服务器都可以往我们的header里面放一些值,我们用pycharm的debug来看一下session:
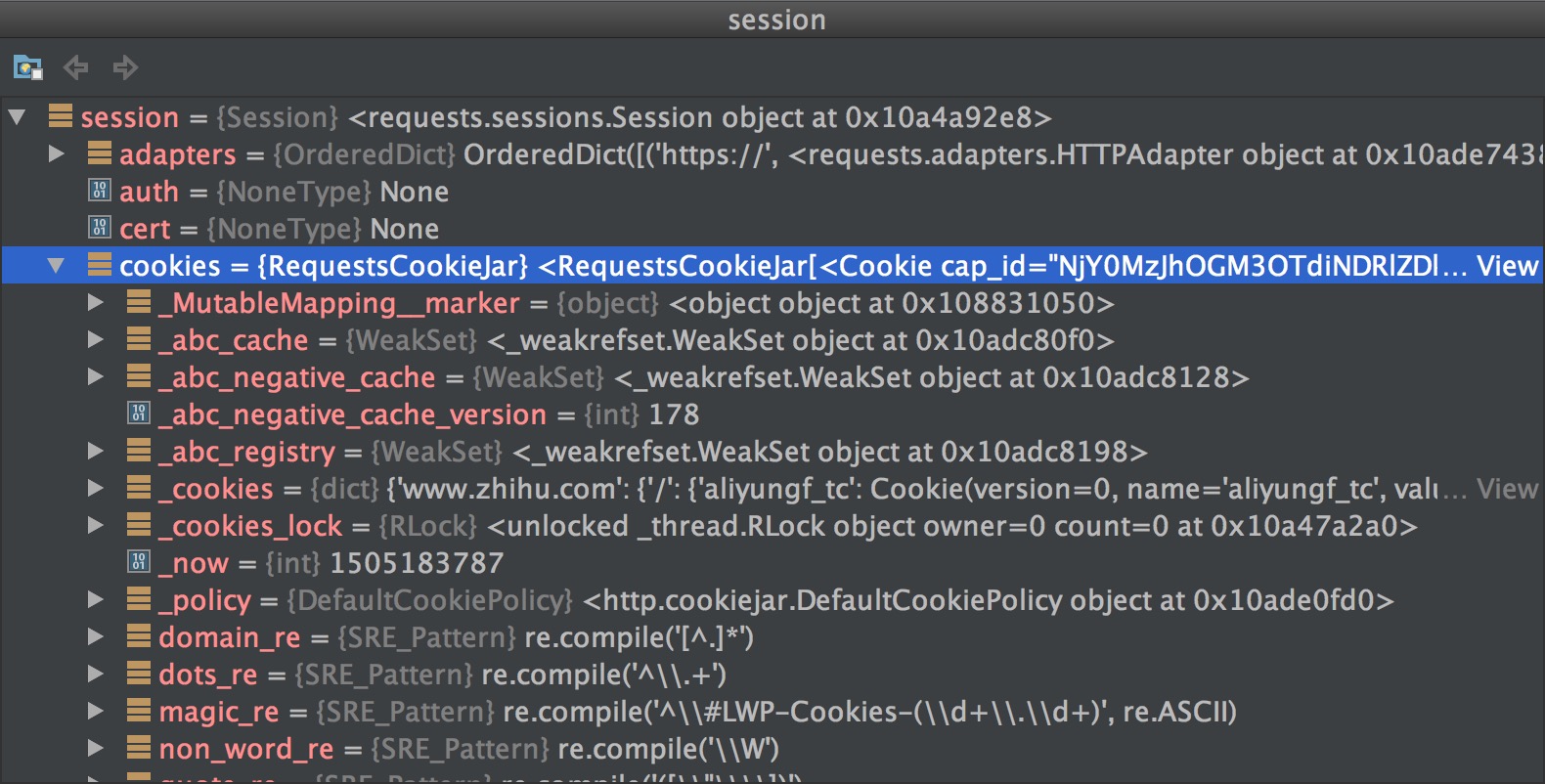
可以看到里面有很多cookie,获取验证码时服务器给我们发的这些cookie,必须在登录时再传给知乎服务器才算认证成功。如果在登录时用requests,它会再建立一次session,就无法把获取验证码带来的cookies传给服务器,这样固然认证失败。
好了,大功告成!只要输入第几个文字是倒立的就行了,比如第二个和第四个文字是倒立的,输入:24 按回车后就自动添加坐标,是不是很开心!
python爬虫scrapy框架——人工识别知乎登录知乎倒立文字验证码和数字英文验证码的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- Python爬虫初学(三)—— 模拟登录知乎
模拟登录知乎 这几天在研究模拟登录, 以知乎 - 与世界分享你的知识.经验和见解为例.实现过程遇到不少疑问,借鉴了知乎xchaoinfo的代码,万分感激! 知乎登录分为邮箱登录和手机登录两种方式,通过 ...
随机推荐
- vuex状态管理,state,getters,mutations,actons的简单使用(一)
之前的文章中讲过,组件之间的通讯我们可以用$children.$parent.$refs.props.data... 但问题来了,假如项目特别大,组件之间的通讯可能会变得十分复杂... 这个时候了我们 ...
- mybatis 详解(六)------通过mapper接口加载映射文件
通过 mapper 接口加载映射文件,这对于后面 ssm三大框架 的整合是非常重要的.那么什么是通过 mapper 接口加载映射文件呢? 我们首先看以前的做法,在全局配置文件 mybatis-conf ...
- Exception in thread "main" java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
这个问题当然是找不到mysql的驱动类,可能是环境CLASSPATH有问题或者就是那个人没有加载jdbc的驱动.我在网上下载mysql-connector-java-5.0.8-bin.jar一个这个 ...
- [填坑]树上差分 例题:[JLOI2014]松鼠的新家(LCA)
今天算是把LCA这个坑填上了一点点,又复习(其实是预习)了一下树上差分.其实普通的差分我还是会的,树上的嘛,也是懂原理的就是没怎么打过. 我们先来把树上差分能做到的看一下: 1.找所有路径公共覆盖的边 ...
- java多线程系列(六)---线程池原理及其使用
线程池 前言:如有不正确的地方,还望指正. 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 java多线程系列(三)之等待通知 ...
- 微信小程序添加、删除class’
终于等到公司开发小程序了,学习的时候不觉得有什么,实际开发就会出现各种问题. 今天第一天开发就遇到问题了. 项目需求,要一个平时的nav导航栏,这玩意用jQuery两行代码解决了,可是小程序不允许操作 ...
- python发布及调用基于SOAP的webservice
现如今面向服务(SOA)的架构设计已经成为主流,把公用的服务打包成一个个webservice供各方调用是一种非常常用的做法,而应用最广泛的则是基于SOAP协议和wsdl的webservice.本文讲解 ...
- JavaScript操作cookie基础分析
简要介绍 cookie是什么cookie是HTTP协议的一部分.HTTP Cookie(也叫Web cookie或者浏览器Cookie)是服务器发送到用户浏览器并保存在浏览器上的一块数据,它会在浏览器 ...
- 巧妙利用JS中的自定义函数——化繁为简,提高效率
利用自定义函数编写年月日时间表: (复杂写法)如下: <body> <select id="year" size="1&q ...
- Spark Streaming 调优指南
SparkStreaming是架构在SparkCore上的一个"应用",SparkStreaming主要由DStreamGraph.Job的生成.数据的接收和导入以及容错四大模块组 ...