Python爬虫 ---scrapy框架初探及实战
Scrapy框架安装
操作环境介绍
操作系统: Ubuntu19.10
Python版本: Python3.7.4
编译器: pycharm社区版
安装scrapy框架(linux系统下)
安装scrapy框架最繁琐的地方在于要安装很多的依赖包,若缺少依赖包,则scrapy框架的安装就会报错。
不过anaconda环境中会自带lxml模块,可以免去一些步骤
在终端输入命令安装依赖包
sudo apt-get install python-dev
sudo apt-get install libevent-dev
根据提示输入y确认安装,耐心等待安装完成即可
安装完所需要的依赖包之后,就可以直接用pip安装scrapy框架了
pip install scrapy
在终端输入命令后,可能会出现网络响应超时等报错

经过几次的尝试之后,我认为这是软件源的问题导致下载过慢,建议更换清华的镜像源来安装
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
在命令的末尾加上-i来暂时使用指定的镜像源来安装scrapy框架
在排除其他问题的影响后,若安装速度依旧不理想,可多尝试几个源来安装
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
ok,我们可以看到更换源之后的下载速度有了显著的提升,只需要等待几秒钟就可以看到安装成功的标志
检测安装是否成功
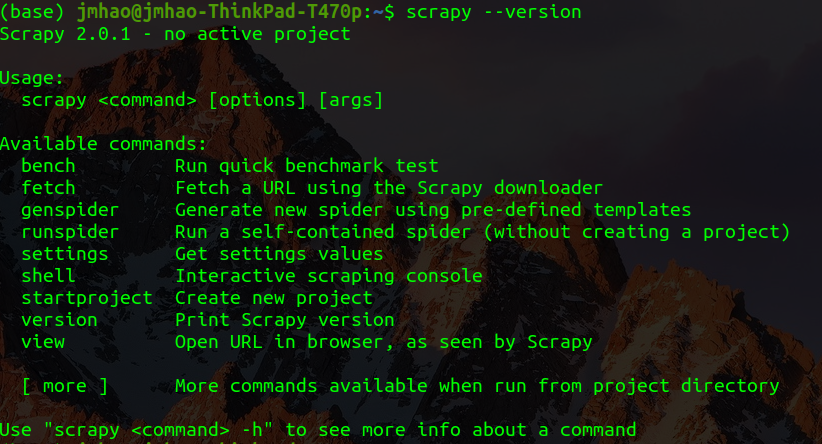
打开终端,输入命令查看scrapy版本
scrapy --version
看到类似下图所示的版本信息:
再输入命令
scrapy bench
这条命令是调用scrapy去爬取一个空网址的内容,再输入命令之后,看到scrapy正在运行去爬取空网址的内容即安装成功了这个框架

Scrapy框架爬取原理
Scrapy框架的主体结构分为五个部分:
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器): 负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫): 它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道): 它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
它还有两个可以自定义下载功能的中间件:
Downloader Middlewares(下载中间件): 一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件): 一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
Scrapy框架运行方式

由上图可以看出,引擎就相当于框架中的大脑,调配着其他部分的运作。
首先爬虫文件向引擎发送网址请求,在经由引擎将网址发送给调度器,调度器通过内部的函数将发来的网址进行队列操作,将排好队的网址重新发送回引擎。引擎接收到了发送回来的队列之后,便将请求交给下载器,由下载器从外部网页获取网页源码,将获取到的响应数据再发送回引擎。引擎接收到下载器发回的网页源码之后,再将数据传回爬虫文件,由爬虫文件负责对html数据的提取,等到数据提取完毕,再把数据发送给引擎。引擎对爬虫文件发送来的内容进行检测,若判断传过来的内容为数据,则引擎将数据发送给专门保存文件的管道数据,管道文件接收到发来的数据之后,就可以有选择的保存在数据库或文件中。
至此,一次完整的爬虫项目运行完成。
Scrapy框架实例
使用Scrapy爬取阿里文学
使用scrapy框架爬取的一般步骤
1.创建爬虫项目
2.创建爬虫文件
3.编写爬虫文件
4.编写items
5.编写pipelines
6.配置settings
7.运行scrapy框架
注:上面的步骤是使用scrapy的一般步骤,实际操作时可以根据爬取页面的难易度来调整这些步骤
1.创建爬虫项目
首先找到一个文件夹,用于保存项目的内容
打开终端,在该目录下输入:
scrapy startproject [项目名称]
成功创建
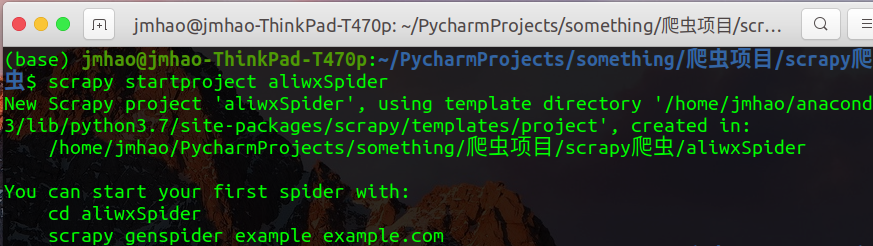
这时可以发现文件夹下多了一个以项目名称命名的文件夹
进入文件夹,发现里面已经有了框架的模板文件

init.py //初始文件
items.py //定义目标,想要爬什么信息
pipelines.py //爬后处理
middlewares.py //中间键
settings.py //文件的设置信息
2.创建爬虫文件
scrapy genspider [爬虫名] [想要爬取网址的域名]
注意:爬虫名一定不能与项目名一样,否则会创建失败

3.分析文件,编写爬虫文件
我们在上一步创建了爬虫文件之后会发现多出来一个py文件在项目名目录下

打开aliwx.py文件,开始分析网页,提取想要爬取的信息
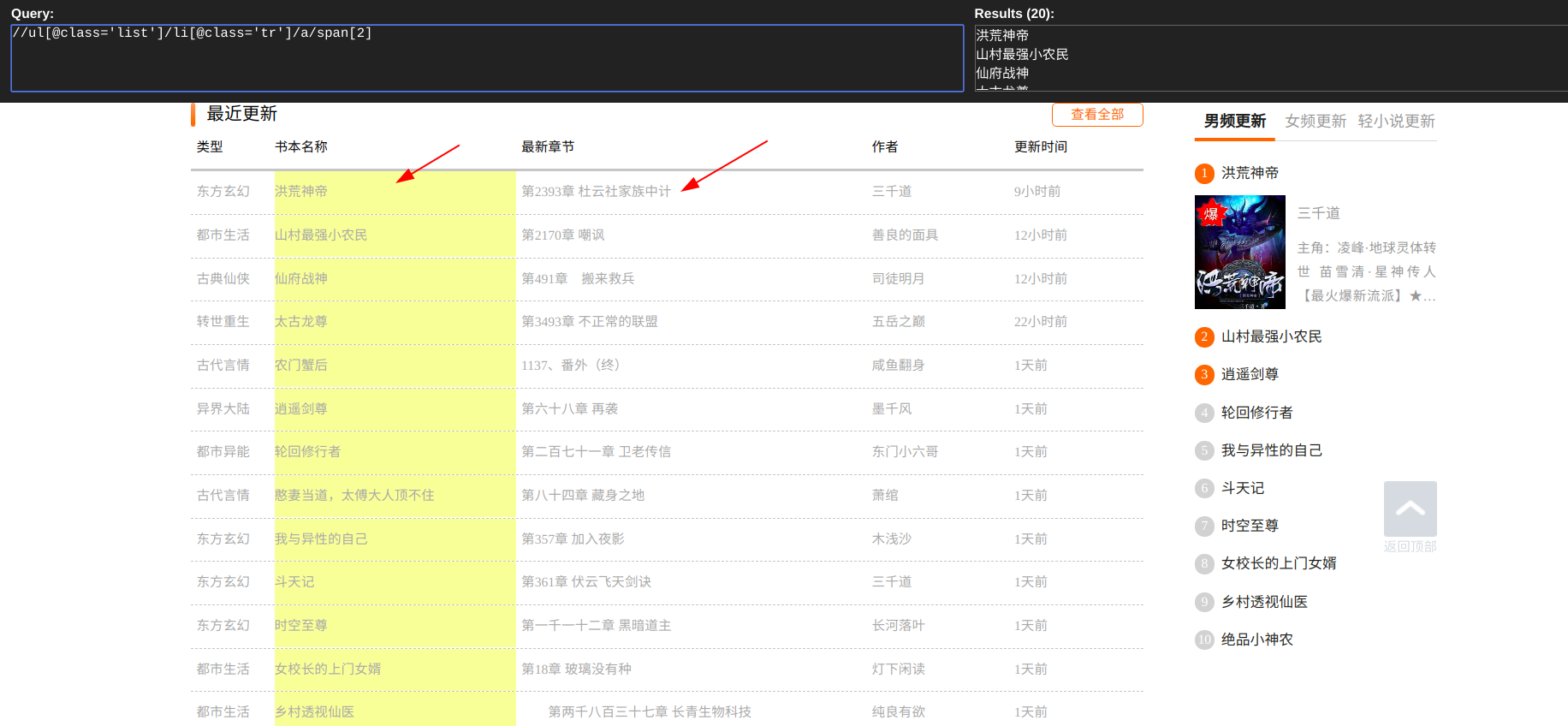
打开阿里文学的官网首页,先设定我们想要爬取的内容为最近更新的书名及章节,使用xpath语法进行提取
打开项目文件夹下的spider文件夹,再打开我们刚刚所创建的爬虫文件
打开后可以看到一个基础的爬虫框架,我们要根据实际的需要来修改这个框架的内容
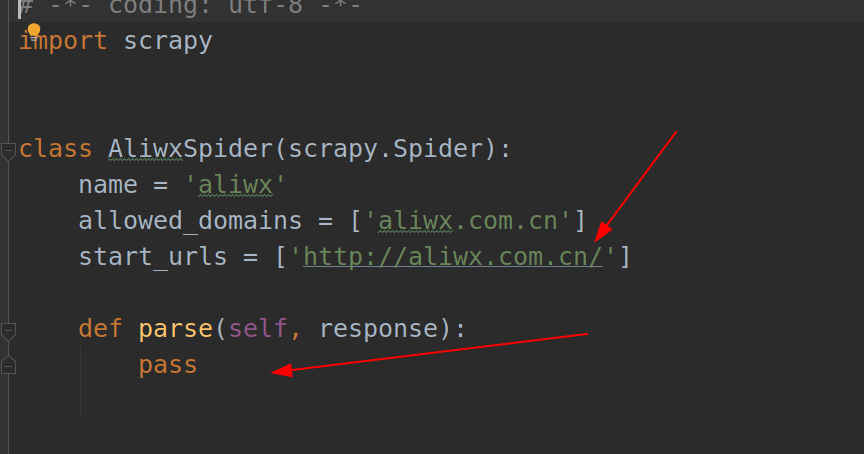
上面有红色箭头的地方就是我们主要修改的地方
首先将第一个指向的地址换成我们想要爬取的地址,即阿里文学的官网首页《https://www.aliwx.com.cn/》
第二个地方就是我们设置爬取内容的定制项
import scrapy
class AliwxSpider(scrapy.Spider):
name = 'aliwx'
allowed_domains = ['aliwx.com.cn']
start_urls = ['https://www.aliwx.com.cn/']
def parse(self, response):
#选择所有a标签下的内容
selectors = response.xpath("//ul[@class='list']/li[@class='tr']/a")
# 循环遍历每一个a标签,使书名和最新章节可以一对一匹配
for selector in selectors:
#提取a标签下的书名 . 表示在当前标签下继续选择
book_name = selector.xpath("./span[2]/text()").get()
#提取a标签下的最新章节名
book_new = selector.xpath("./span[3]/text()").get()
#打印书名和章节名
print(book_name,book_new)
4.设置settings
打开settings文件,在文件中找到代码

这一行的意思是询问是否遵循爬虫协议,大致来讲就是协议规范了我们只能提取网站允许我们提取的内容,所以此处应该将True提换成False,否则我们很有可能提取不到想要的内容
5.运行scrapy框架
打开终端,将目录切换至项目文件夹下,输入命令行来运行项目
scrapy crawl [爬虫名]
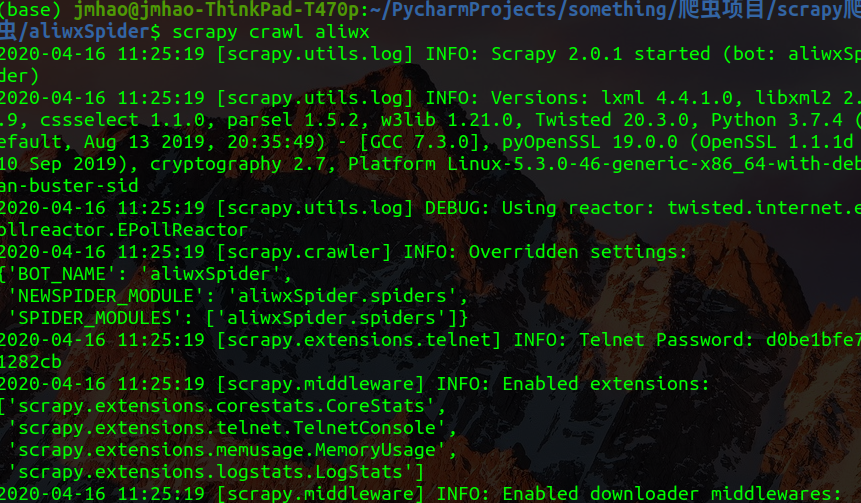
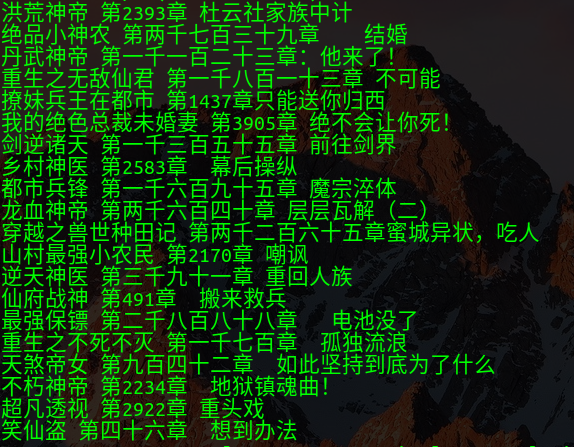
等待项目运行完毕,即可看到爬取到的内容:
6.将爬取下来的内容保存到文件
如果想要将内容保存到文件中,就需要设置一个返回值来储存
将print(book_name,book_new)语句替换
items = {
'name': book_name,
'new': book_new,
}
yield items
再打开终端,输入运行并保存命令:
scrapy crawl aliwx -o book.csv
等待程序运行完成,就可以看到出现了一个book.csv文件在项目目录下,打开就是我们所保存的内容

到此为止一个最基本的爬虫项目就制作完成了,如果有哪里写的不好请大佬多多批评指正!
Python爬虫 ---scrapy框架初探及实战的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- Python 爬虫-Scrapy框架基本使用
2017-08-01 22:39:50 一.Scrapy爬虫的基本命令 Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行. Scrapy命令行格式 Scrapy常用命令 采用 ...
随机推荐
- vscode在执行 npm任务的时候,会先执行package的name@version 然后命令名 加 当前路径,问题是我的引入路径e是小写的,会导致调试错误,解决方案:没找到,先手书吧
vscode在执行 npm任务的时候,会先执行package的name@version 然后命令名 加 当前路径,问题是我的引入路径e是小写的,会导致调试错误,解决方案:没找到 Executing t ...
- 迷你记事本 https://vladocar.github.io/Minimal-Notes/
迷你记事本 https://vladocar.github.io/Minimal-Notes/
- iconfont字体图标的使用方法(转)
我之前因为项目用bootstrap比较多,所以使用font awesome字体图标比较多,后来接触到了iconfont,发现想要的什么图标都有,还可以自定义图标,非常强大!之前看了一波教程,觉得繁琐, ...
- DVWA Brute Force 解析
LOW 源代码如下: <?php if( isset( $_GET['Login'] ) ) { $user = $_GET['username']; $pass = $_GET['passwo ...
- Natas11 Writeup(常见编码、异或逆推、修改cookie)
Natas11: 页面提示cookie被异或加密保护,查看源码,发现了一个预定义参数和三个函数. //预定义参数,猜测将showpassword设置为yes即可得到密码. $defaultdata = ...
- Caused by: java.lang.IllegalArgumentException
Caused by: java.lang.IllegalArgumentException 是因为jdk较高而项目需要的是低版本的问题 1.将idea或idea里的语言级别调到适合自己项目的版本比如安 ...
- 详解聚类算法Kmeans的两大优化——mini-batch和Kmeans++
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第13篇文章,我们来看下Kmeans算法的优化. 在上一篇文章当中我们一起学习了Kmeans这个聚类算法,在算法的最后我 ...
- 记一次有趣的thinkphp代码执行
0x00 前言 朋友之前给了个站,拿了很久终于拿下,简单记录一下. 0x01 基础信息 漏洞点:tp 5 method 代码执行,payload如下 POST /?s=captcha _method= ...
- dvwa学习之七:SQL Injection
1.Low级别 核心代码: <?php if( isset( $_REQUEST[ 'Submit' ] ) ) { // Get input $id = $_REQUEST[ 'id' ]; ...
- 浅析二分搜索树的数据结构的实现(Java 实现)
目录 树结构简介 二分搜索树的基础知识 二叉树的基本概念 二分搜索树的基本概念 二分搜索树的基本结构代码实现 二分搜索树的常见基本操作实现 添加操作 添加操作初步实现 添加操作改进 查询操作 遍历操作 ...