Python图片爬虫
1.今天给大家介绍自己写的一个图片爬虫,说白了就是从网页自动上下载需要的图片
2.首先选取目标为:http://www.zhangzishi.cc/涨姿势这个网站如下图,我们的目标就是爬取该网站福利社的所有美图

3.福利社地址为http://www.zhangzishi.cc/category/welfare,获取图片就是获取所有网站图片的url地址,首先
A.打开URL,获取html代码
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read()
print('url_open')
return html
B.从html代码中摘取网页链接,返回的是一个列表
def page_htmls(url,count):
html = url_open(url).decode('utf-8')
pages = []
a = html.find('a target="_blank" href=')
i = 0
while a != -1:
i += 1
b = html.find('.html',a,a+200)
if b != -1:
pages.append(html[a+24:b+5])
else:
b = a + 24
a = html.find('a target="_blank" href=',b)
if i == count:
break
for each in pages:
print(each)
return pages
C.从每一个链接页中获取图片地址,我这用了两种方法
def find_imgs(url):
html = url_open(url).decode('utf-8')
imgs = [] a = html.find('img src=')
while a != -1:
b = html.find('.jpg',a,a+100)
if b != -1:
if html[a+9:b+4].find('http') == -1:
imgs.append('http:'+html[a+9:b+4])
else:
imgs.append(html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
'''
for each in imgs:
print(each)
'''
return imgs def imgurl_get(url):
html = url_open(url).decode('utf-8')
imgurls = []
a = html.find('color: #555555;" src=')
while a != -1:
b = html.find('.jpg',a,a+100)
if b != -1:
imgurls.append('http:'+html[a+22:b+4])
else:
b = a + 22
a = html.find('color: #555555;" src=',b) return imgurls
D.根据图片url下载图片到文件
def save_imgs(folder,imgs):
for ea in imgs:
filename = ea.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(ea)
f.write(img) def download_mm(folder='H:\\xxoo2',page_count = 100,count = 100):
main_url = 'http://www.zhangzishi.cc/category/welfare'
main_urls = []
for i in range(count):
main_urls.append(main_url+'/page/'+str(i+1))
os.mkdir(folder)
os.chdir(folder)
for url in main_urls:
htmls = page_htmls(url,page_count)
for page in htmls:
imgurls = imgurl_get(page) save_imgs(folder,imgurls)
E.开始下载
def download__img(folder='H:\\xxoo',page_count=100):
main_url = 'http://www.zhangzishi.cc/category/welfare'
os.mkdir(folder)
os.chdir(folder)
htmls = page_htmls(main_url,page_count)
for page in htmls:
imgs_url = find_imgs(page) save_imgs(folder,imgs_url) if __name__ == '__main__': download_mm()
#download__img()
F:下载结果
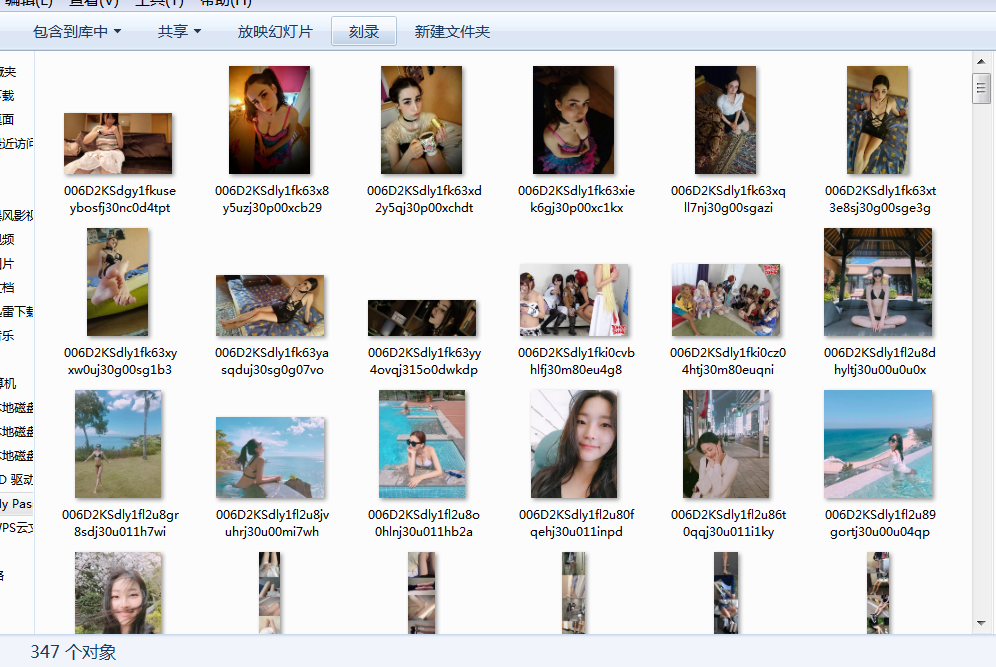
顺便附上全部代码:
import urllib.request
import os def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read()
print('url_open')
return html def page_htmls(url,count):
html = url_open(url).decode('utf-8')
pages = []
a = html.find('a target="_blank" href=')
i = 0
while a != -1:
i += 1
b = html.find('.html',a,a+200)
if b != -1:
pages.append(html[a+24:b+5])
else:
b = a + 24
a = html.find('a target="_blank" href=',b)
if i == count:
break
for each in pages:
print(each)
return pages
''' '''
def find_imgs(url):
html = url_open(url).decode('utf-8')
imgs = [] a = html.find('img src=')
while a != -1:
b = html.find('.jpg',a,a+100)
if b != -1:
if html[a+9:b+4].find('http') == -1:
imgs.append('http:'+html[a+9:b+4])
else:
imgs.append(html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
'''
for each in imgs:
print(each)
'''
return imgs def imgurl_get(url):
html = url_open(url).decode('utf-8')
imgurls = []
a = html.find('color: #555555;" src=')
while a != -1:
b = html.find('.jpg',a,a+100)
if b != -1:
imgurls.append('http:'+html[a+22:b+4])
else:
b = a + 22
a = html.find('color: #555555;" src=',b) return imgurls
'''
for each in imgurls:
print(each)
''' def save_imgs(folder,imgs):
for ea in imgs:
filename = ea.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(ea)
f.write(img) def download_mm(folder='H:\\xxoo2',page_count = 100,count = 100):
main_url = 'http://www.zhangzishi.cc/category/welfare'
main_urls = []
for i in range(count):
main_urls.append(main_url+'/page/'+str(i+1))
os.mkdir(folder)
os.chdir(folder)
for url in main_urls:
htmls = page_htmls(url,page_count)
for page in htmls:
imgurls = imgurl_get(page) save_imgs(folder,imgurls) def download__img(folder='H:\\xxoo',page_count=100):
main_url = 'http://www.zhangzishi.cc/category/welfare'
os.mkdir(folder)
os.chdir(folder)
htmls = page_htmls(main_url,page_count)
for page in htmls:
imgs_url = find_imgs(page) save_imgs(folder,imgs_url) if __name__ == '__main__': download_mm()
#download__img()
Python图片爬虫的更多相关文章
- python 图片爬虫
#!/usr/bin/env python #coding:utf-8 import urllib import re def GetHtml(url): """获取HT ...
- python图片爬虫 - 批量下载unsplash图片
前言 unslpash绝对是找图的绝佳场所, 但是进网站等待图片加载真的令人捉急, 仿佛是一场拼RP的战争 然后就开始思考用爬虫帮我批量下载, 等下载完再挑选, 操作了一下不算很麻烦, 顺便也给大家提 ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- Python爬虫02——贴吧图片爬虫V2.0
Python小爬虫——贴吧图片爬虫V2.0 贴吧图片爬虫进阶:在上次的第一个小爬虫过后,用了几次发现每爬一个帖子,都要自己手动输入帖子链接,WTF这程序简直反人类!不行了不行了得改进改进. 思路: 贴 ...
- python多线程爬虫+批量下载斗图啦图片项目(关注、持续更新)
python多线程爬虫项目() 爬取目标:斗图啦(起始url:http://www.doutula.com/photo/list/?page=1) 爬取内容:斗图啦全网图片 使用工具:requests ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片 其实没太大用,就是方便一些,因为现在各个平台之间的图片都不能共享,比如说在 CSDN 不能用简书的图片, ...
随机推荐
- 设置SO_RECVBUF和SO_SENDBUF套接字选项
控制套接字的行为(如修改缓冲区的大小). int getsockopt(int sockfd,int level,int optname,void *optval,socklen_t *optlen) ...
- python3中的编码与解码(超好理解)
编码和解码是针对数据而言的,数据能干什么呢?无非就是用来显示,储存和传输的: 储存和传输数据当然是希望数据越小越好,所以发明了utf-8这种数据编码显示:它智能将英文用一个字节表示,欧洲的字符用两个字 ...
- openstack pike 使用 openvswitch + vxlan
# openstack pike 使用 openvswitch + vxlan# openstack pike linuxbridge-agent 换为 openvswitch-agent #open ...
- 一步步搭建Retrofit+RxJava+MVP网络请求框架(一)
首先,展示一下封装好之后的项目的层级结构. 1.先创建一个RetrofitApiService.java package com.xdw.retrofitrxmvpdemo.http; import ...
- 《Linux命令行与shell脚本编程大全》第二十五章 创建与数据库、web及电子邮件相关的脚本
25.1 MySQL数据库 /* 但是我在虚拟机上安装的时候居然不提示输入密码. 这个可以参考http://blog.csdn.net/sinat_21302587/article/details/7 ...
- PHP根据传入参数合并多个JS和CSS文件的简单实现
HTML(使用方法): 复制代码代码如下: <link rel="stylesheet" type="text/css" href="cssmi ...
- maven项目pom.xml配置文件依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- 数据结构之【栈】+十进制转d进制(堆栈数组模拟)
其实这篇文章开出来主要是水文章%% %% 栈--后进先出的婊 特点:只能在某一端插入和删除的特殊的线性表 操作:进栈--PUSH->向栈顶插入元素 出栈--POP-->将栈顶元素删除 实现 ...
- IP协议和网络传输中的封装与分用。
关于七层模型和四层模型可以参考这个:http://www.cnblogs.com/xcywt/p/5027277.html 因为四层模型用的比较多,这里只拿四层模型来分析. 1.四层模型中的最下层是链 ...
- svn文件回滚到某个历史版本号
转载请注明出处:http://blog.csdn.net/dongdong9223/article/details/50819642 本文出自[我是干勾鱼的博客] 有时候想要将svn中的某个文件回滚到 ...