Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
其实没太大用,就是方便一些,因为现在各个平台之间的图片都不能共享,比如说在 CSDN 不能用简书的图片,在博客园不能用 CSDN 的图片。
当前想到的方案就是:先把 CSDN 上的图片都下载下来,再手动更新吧。
所以简单写了一个爬虫用来下载 CSDN 平台上的图片,用于在其他平台上更新图片时用
更多内容,请看代码注释
效果演示
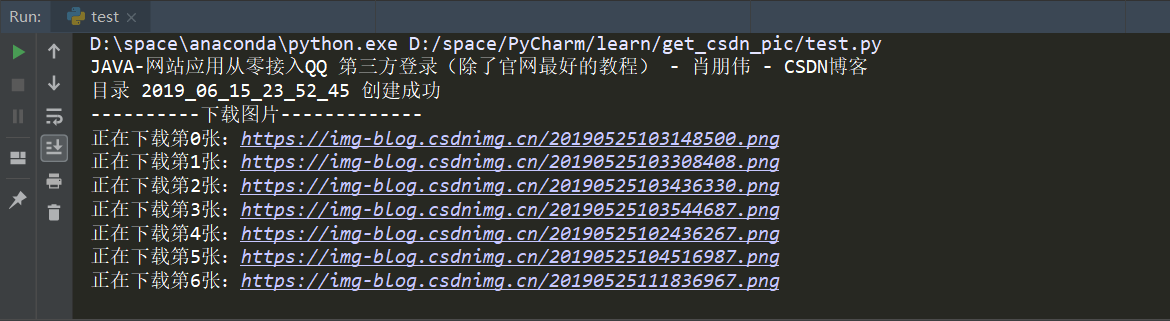

Python 源代码
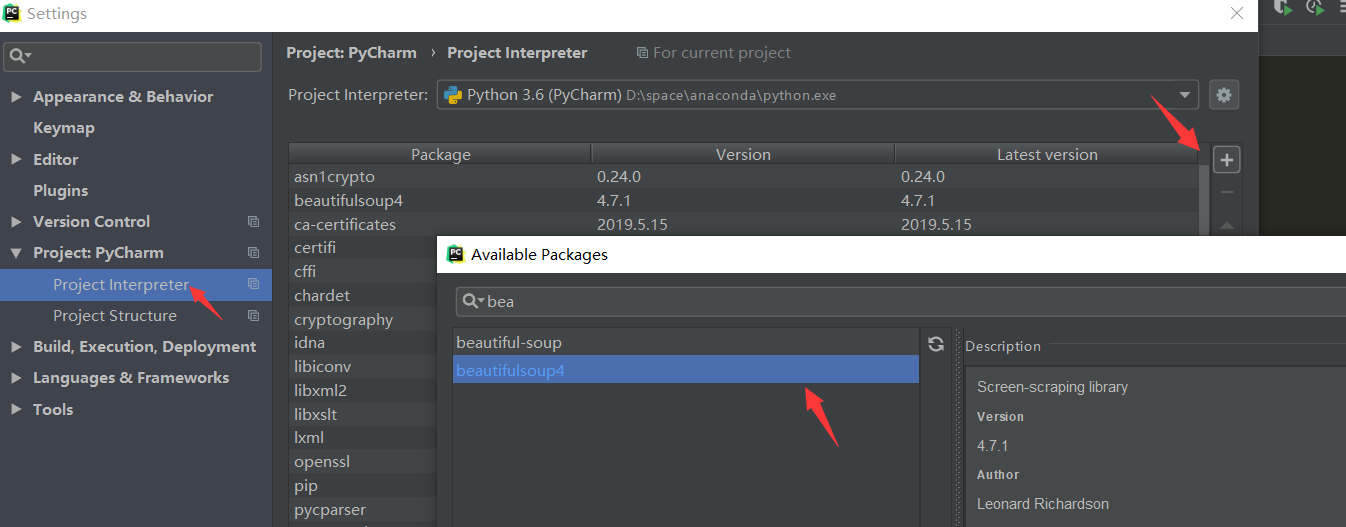
提示: 需要先下载 BeautifulSoup 哦,可以用 pip,也可以直接在 PyCharm 中安装
简单的方法:
# coding:utf-8
'''
使用爬虫下载图片:
1.使用 CSDN 博客
2.获取图片连接,并下载图片
3.可去除水印
作者:java997.com
'''
import re
from urllib import request
from bs4 import BeautifulSoup
import datetime
# 构造无水印纯链接数组
def get_url_array(all_img_href):
img_urls = []
for h in all_img_href:
# 去掉水印
if re.findall("(.*?)\?", h[1]):
h = re.findall("(.*?)\?", h[1])
# 因为这里匹配就只有 src 了, 所以直接用 0
img_urls.append(h[0])
else:
# 因为这里还没有处理有 alt 的情况, 所以直接用 1
img_urls.append(h[1])
return img_urls
# 构建新目录的方法
def mkdir(path):
# 引入模块
import os
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print('目录 ' + path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print('目录 ' + path + ' 已存在')
return False
if __name__ == '__main__':
# url = input("请粘贴博客链接")
url = "https://blog.csdn.net/qq_40147863/article/details/90484190"
# 获取页面 html
rsp = request.urlopen(url)
all_html = rsp.read()
# 一锅清汤
soup = BeautifulSoup(all_html, 'lxml')
# bs 自动解码
content = soup.prettify()
# 获取标题
tags = soup.find_all(name='title')
for i in tags:
# .string 是去掉标签, 只打印内容
print(i.string)
# 获取正文部分
article = soup.find_all(name='article')
# print(article[0])
# 获取图片的链接
all_img_href = re.findall('<img(.*?)src="(.*?)"', str(article))
# 调用函数, 获取去掉水印后的链接数组
img_urls = get_url_array(all_img_href);
# 用当前之间为目录名, 创建新目录
now_time = datetime.datetime.now()
now_time_str = datetime.datetime.strftime(now_time, '%Y_%m_%d_%H_%M_%S')
mkdir(now_time_str)
print("----------下载图片-------------")
i = 0
for m in img_urls:
# 由于没有精确匹配,并不是所有连接都是我们要的课程的连接,排出第一张图片
print('正在下载第' + str(i) + '张:' + m)
# 爬取每个网页图片的连接
img_url = request.urlopen(m).read()
# img 目录【必须手动创建好】
fp = open(now_time_str+'\\' + str(i) + '.jpg', 'wb')
# 写入本地文件
fp.write(img_url)
# 目前没有想到更好的方式,暂时只能写一次,关闭一次,如果有更好的欢迎讨论
fp.close()
i += 1
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片的更多相关文章
- 利用爬虫爬取指定用户的CSDN博客文章转为md格式,目的是完成博客迁移博文到Hexo等静态博客
文章目录 功能 爬取的方式: 设置生成的md文件命名规则: 设置md文件的头部信息 是否显示csdn中的锚点"文章目录"字样,以及下面具体的锚点 默认false(因为csdn中是集 ...
- python网络爬虫进入(一)——简单的博客爬行动物
最近.对于图形微信公众号.互联网收集和阅读一些疯狂的-depth新闻和有趣,发人深思文本注释,并选择最佳的发表论文数篇了.但看着它的感觉是一个麻烦的一人死亡.寻找一个简单的解决方案的方法,看看你是否可 ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- python实战--csdn博客专栏下载器
打算利用业余时间好好研究Python的web框架--web.py,深入剖析其实现原理,体会web.py精巧之美.但在研究源码的基础上至少得会用web.py.思前想后,没有好的Idea,于是打算开发一个 ...
- 从CSDN博客下载的图片如何无损去水印
如果你想下载别人CSDN博客文章中很好看的图片,但却有水印 想要下载去水印的图片,可以先鼠标右击该图片,选择复制图片地址 https://img-blog.csdnimg.cn/20200916140 ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- Python爬虫学习之正则表达式爬取个人博客
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url.标题以及摘要. 实例环境:pytho ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- Python 爬取CSDN博客频道
初次接触python,写的很简单,开发工具PyCharm,python 3.4很方便 python 部分模块安装时需要其他的附属模块之类的,可以先 pip install wheel 然后可以直接下载 ...
随机推荐
- Delphi组件编辑器
看到Dev中的cxGrid组件的编辑器很强大,于是很想探究一下,跟踪cxGrid的代码比较麻烦,但原理大概知道一二.首先来研究一下设计器双击cxGrid弹出一个编辑窗体,选择窗体中的一个内容后,属性编 ...
- Python爬虫学习==>第二章:MongoDB环境配置
学习目的: MongoDB的安装 正式步骤 (VMWare 虚拟机上无法安装这个MongoDB的自启动服务,如果你能办到,请多赐教) Step1:MongoDB的简介 MongoDB是一个基于分布式文 ...
- Java的Comparable接口
Comparable接口提供比较对象大小功能,实现了此接口的类的对象比较大小将通过接口提供的compareTo方法. 此方法的返回int类型,分三种情况. 返回正数,当前对象大于目标对象 返回负数,当 ...
- 【Python开发】Python之re模块 —— 正则表达式操作
Python之re模块 -- 正则表达式操作 这个模块提供了与 Perl 相似l的正则表达式匹配操作.Unicode字符串也同样适用. 正则表达式使用反斜杠" \ "来代表特殊形式 ...
- 时间转换:DateTimeExtensions
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- 【Linux-驱动】RTC设备驱动架构
在Linux操作系统中,RTC设备驱动的架构如下图所示: RTC设备驱动涉及的文件:class.c.rtc-dev.c : 建立/dev/rtc0设备,同时注册相应的操作函数.interface.c ...
- orzdba工具配置
./orzdba -lazy -rt -S /u01/svr/working/my3306/run/mysql.sock mysql -s --skip-column-names -h127.0.0. ...
- Ubuntu19.04系统SSH连接CentOS7虚拟机
一.为CentOS7配置静态IP 注意查看宿主机(Ubuntu19.04)所在局域网段,当前为172.18.25.108 修改当前系统下virtual box的网络设置 [控制]-->[设置]- ...
- Django发送邮件和itsdangerous模块的配合使用
项目需求:用户注册页面注册之后,系统会发送一封邮件到用户邮箱,用户点击链接以激活账户,其中链接中的用户信息需要加密处理一下 其中激活自己邮箱的smtp服务的操作就不在加以说明,菜鸟教程上有非常清晰的讲 ...
- # 深圳杯D题爬取电视收视率排行榜
目录 深圳杯D题爬取电视收视率排行榜 站点分析 代码实现 深圳杯D题爬取电视收视率排行榜 站点分析 http://www.tvtv.hk/archives/category/tv 每天的排行版通过静态 ...