Xgboost理解
一、xgboost模型函数形式
xgboost也是GBDT的一种,只不过GBDT在函数空间进行搜索最优F的时候,采用的是梯度下降法也就是一阶泰勒展开;而xgboost采用的是二阶泰勒展开也就是牛顿法,去每次逼近最优的F,泰勒展开越多与原函数形状越接近,比如在x0处进行展开,其展开越多,x0附近与原函数值越接近,且这个附近的区域越大。另外一个xgboost加入了正则化项,有效防止过拟合。
xgboost与GBDT都是采用的cart树中的回归树来解决所有问题,回归树的预测输出是实数分数,可以用于回归、分类、排序等任务中。对于回归问题,可以直接作为目标值,对于分类问题,需要映射成概率,比如采用逻辑回归的sigmoid函数。

additive表示附加的,所谓additive training,就是每次add一颗树进行学习,直到损失最小。
误差函数尽量去拟合训练数据,正则化项则鼓励更加简单的模型。因为当模型简单之后,有限数据拟合出来结果的随机性比较小,不容易过拟合,使得最后模型的预测更加稳定。
二、目标函数
1)回顾传统参数空间的目标函数

误差函数可以是square loss,logloss等,正则项可以是L1正则,L2正则等。正则项如果从Bayes角度来看,相当于对模型参数引入先验分布:
L1正则,模型参数服从拉普拉斯分布,对参数加了分布约束,大部分取值为0。
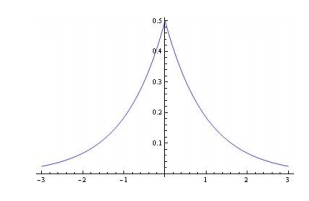
L2正则,模型参数服从高斯分布,对参数加了分布约束,大部分绝对值很小。
2)xgboost在函数空间搜索的目标函数
函数空间的目标函数是多棵树一起构建的目标损失函数,求解多棵树一起的整体最优解。
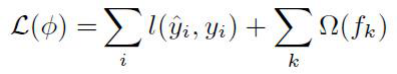
第一部分属于误差项,训练模型的精度;第二部分正则项对每一棵回归树的复杂度进行了惩罚,使得学习出来的模型不容易过拟合。
哪些指标可以衡量树的复杂度呢?
树的深度,内部节点个数,叶子节点个数,叶子节点分数等。
xgboost采用叶子节点个数T和叶子节点分数w(其实就是预测值)对树的复杂度进行约束:

对叶子节点个数进行惩罚,相当于进行了剪枝。
三、泰勒展开
基本形式:

一阶与二阶泰勒展开:
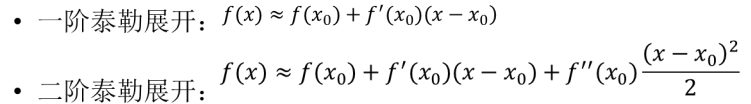
1)一阶泰勒展开(梯度下降法)
在机器学习任务中,需要最小化损失函数L(θ) ,其中θ 是要求解的模型参数。梯度下降法常用来求解这种无约束最优化问题,它是一种迭代方法:选取初值 θ0,不断迭代,更新θ的值,进行损失函数的极小化。

从上面可知,当△θ=-αL丶(θt-1)时候,θ的更新就跟我们之前理解的梯度下降方法是一摸一样。将△θ带入损失函数即可知,这个时候L(θt)是肯定比L(θt-1)变小的。
所以,从梯度下降法角度理解,就是函数值沿着梯度的负方向进行减少;从泰勒展开角度理解,就是函数在θt-1处进行一阶展开,并根据展开公式找到了比L(θt-1)更小的近似于L(θt)的值,因为泰勒展开本身就是用多项式形式近似表达函数的原形式。
2)二阶泰勒展开(牛顿法)

此时如何进行优化,寻找更小的L(θt)?

这时候利用泰勒二阶展开求解最优的△θ,使得L(θt)更小,泰勒二阶比一阶肯定更接近原函数的值,所求得的△θ也使得L(θt)下降的更快,这就是牛顿法的优势。
四、xgboost目标函数进行泰勒展开
xgboost在第t次迭代后,模型的预测等于前t-1次的模型预测加上第t棵树的预测:
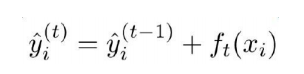
由于模型已经进行了t-1次迭代,也就是已经学习了t-1棵树,此时只要学习寻找最优的第t棵树函数ft即可,所以目标函数如下:
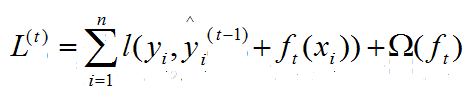
其中yi和yi(t-1)都属于已知的,可以理解为常数。
将目标函数在yi(t-1)处进行泰勒二次展开,因为我们一步步寻找的是最优的函数yi(t)使得L最小,就是上面所说的在函数空间进行的搜索,所以在yi(t-1)处进行泰勒二次展开寻找并学习下一颗树ft,这里的ft其实就相当于上文第三部门牛顿法中的△θ,不停的寻找ft,最后将这些树加起来就成了最优的yt,上文中也是不停的寻找△θ,最后θ*=θ0+Σ△θ,一样的道理。无非一个是在参数空间进行搜索,一个是在函数空间进行搜索。二次展开如下:
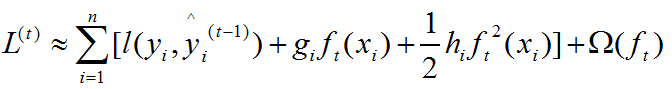
其中gi和hi分布如下:


将常数项去掉,并把树的结构形式带入得到如下:

其实这个时候已经简洁地变成对t棵树的学习优化问题了,以叶子节点形式表示上述目标函数如下,其中Ij={i|q(xi)=j}表示j叶子节点上的样本集合。
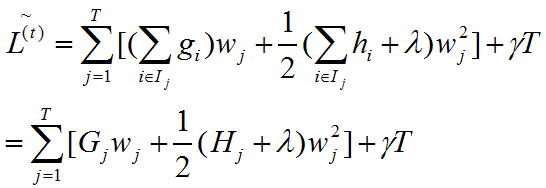
为了使目标函数最小,可以令其导数为0,解得每个叶节点的最优预测分数为:

带入目标函数,得到最小损失为:

五、如何进行分裂?
1)如何评测节点分裂的优劣?
ID3采用信息增益来评测,C4.5采用信息增益率、CART树采用基尼系数和平方损失来评测,xgboost采用如下的打分评测:
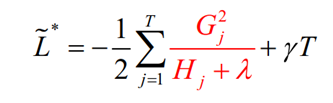
其实就是上面的最小损失值的公式,如果分裂后能让损失变得更小,就值得去分裂,所以分裂前后增益定义为:
这个Gain就是分裂前的损失-分裂后的损失,差值越大,代表分裂后的损失越小,所以当对一个节点进行分裂时,计算所有候选(feature,value)对应的gain,选区gain最大的进行分裂。
2)寻找分裂节点
1、精确算法-暴力穷举搜索法
遍历所有特征的所有可能的分割点,计算gain值,选取gain值最大的(feature,value)去分割。该方式优点是精度高,缺点是计算量太大。
2、近似算法-分位点分割
对于某一个特征,按照百分比确定候选分裂点,通过遍历所有特征的所有候选分裂点来找到最佳分裂点,减少了计算复杂度。
3.weighted quantile sketch(按权重的分位点算法)
该方法将样本对应的残差二阶导h作为划分依据,假设每一个分位点区间的h之和占总h的比率为rk(z),则两个相邻区间的rk之差小于一个固定值,如下所示:

从上图可知ε是一个小数,其实也就是将权重约分为了1/ε个分位点。


Xgboost理解的更多相关文章
- GB、GBDT、XGboost理解
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- 决策树(下)-Xgboost
参考资料(要是对于本文的理解不够透彻,必须将以下博客认知阅读,方可更加了解Xgboost): 1.对xgboost的理解(参考资料1和4是我认为对Xgboost理解总结最透彻的两篇文章,其根据作者pa ...
- 一步一步理解GB、GBDT、xgboost
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- gbdt xgboost 贼难理解!
https://www.zybuluo.com/yxd/note/611571 https://zhuanlan.zhihu.com/p/29765582 gbdt 在看统计学习方法的时候 理解很吃力 ...
- 大白话5分钟带你走进人工智能-第32节集成学习之最通俗理解XGBoost原理和过程
目录 1.回顾: 1.1 有监督学习中的相关概念 1.2 回归树概念 1.3 树的优点 2.怎么训练模型: 2.1 案例引入 2.2 XGBoost目标函数求解 3.XGBoost中正则项的显式表达 ...
- xgboost原理及应用
1.背景 关于xgboost的原理网络上的资源很少,大多数还停留在应用层面,本文通过学习陈天奇博士的PPT 地址和xgboost导读和实战 地址,希望对xgboost原理进行深入理解. 2.xgboo ...
- 【转】XGBoost参数调优完全指南(附Python代码)
xgboost入门非常经典的材料,虽然读起来比较吃力,但是会有很大的帮助: 英文原文链接:https://www.analyticsvidhya.com/blog/2016/03/complete-g ...
- XGBoost参数调优完全指南(附Python代码)
XGBoost参数调优完全指南(附Python代码):http://www.2cto.com/kf/201607/528771.html https://www.zhihu.com/question/ ...
- xgboost-python参数深入理解
由于在工作中应用到xgboost做特征训练预测,因此需要深入理解xgboost训练过程中的参数的意思和影响. 通过search,https://www.analyticsvidhya.com/blog ...
随机推荐
- 《Linux内核分析》 第二节 操作系统是如何工作的
Linux内核分析 第二周 操作系统是如何工作的 张嘉琪 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/UST ...
- 从零开始学Kotlin-基础语法(1)
从零开始学Kotlin基础篇系列文章 注释 //单行注释 /* 多行注释 */ /** * 多行注释 */ 定义变量/常量 变量定义:var 关键字 var <标识符> : <类型& ...
- Caffe搭建:Ubuntu14.04 + CUDA7.0 + opencv3.0 + Matlab2014A
从Hinton在science上发表深度学习训练开创新的文章以来,深度学习火了整整有3年多,而且随着新的硬件和算法的提出,深度学习正在应用于越来越多的领域,发挥其算法的优势. 实验室并没有赶上第一波深 ...
- Java之资源文件读取
ClassLoaderWrapper.java package org.utils.resource; import java.io.InputStream; import java.net.URL; ...
- 深入理解javascript选择器API系列第三篇——HTML5新增的3种selector方法
前面的话 尽管DOM作为API已经非常完善了,但是为了实现更多的功能,DOM仍然进行了扩展,其中一个重要的扩展就是对选择器API的扩展.人们对jQuery的称赞,很多是由于jQuery方便的元素选择器 ...
- pgm7
和 Koller 的 video 最大的不同莫过于书上讲 LBP 的角度不是 procedural 的,而是原理性的.我们先看个 procedural 的,在一般的 cluster graph 上的 ...
- BZOJ2547 CTSC2002玩具兵(最短路径+二分答案+最大流)
先不考虑只有一个显得有些特殊的天兵. 可以发现超能力的作用实质上是使兵更换职业.每一个兵到达某个位置最少需要更换职业的次数是彼此独立的,因为如果需要某两人互换职业可以使他们各自以当前职业到达需要到的地 ...
- HDU 4303 Hourai Jeweled 解题报告
HDU 4303 Hourai Jeweled 解题报告 评测地址: http://acm.hdu.edu.cn/showproblem.php?pid=4303 评测地址: https://xoj. ...
- 滥用基于资源约束委派来攻击Active Directory
0x00 前言 早在2018年3月前,我就开始了一场毫无意义的争论,以证明TrustedToAuthForDelegation属性是无意义的,并且可以在没有该属性的情况下实现“协议转换”.我相信,只要 ...
- 部署harbor1.2.0开启ldap验证
就harbor本身部署来说是非常简单的,之前写过详细步骤,这里不再重复. 这里主要是总结一下部署当中遇到的问题,以及如何开启ldap验证. harbor默认是通过http通信的,当然也支持https, ...