rancher2 HA部署注意事项
参考:
https://rancher.com/docs/rancher/v2.x/en/installation/ha-server-install/
https://www.cnblogs.com/rancher-maomao/p/8445111.html
部署要点:
域名解析准备:
域名解析至三个IP作轮询解析,类似下方:
rancher.qq.com 192.168.1.1
racher.qq.com 192.168.1.2
racher.qq.com 192.168.1.3
系统版本:
建议使用Ubuntu 16.04版本,CentOS7没有配置成功,需要修改的地方太多了;
Docker版本:
RKE在Github上的readme中已有说明,Kubernetes1.10.1需要Docker 1.13.1;
主机名:
如果是克隆的系统一定要修改主机名,hostname主机名必须不同!
主机文件:
/etc/hosts要配置正确,一定要有127.0.0.1 localhost 这一项。Hosts文件中包含所有主机节点的IP和名称列表。使用vi进行编辑,不能使用中文全角的空格;
SELinux:
必须关闭!Ubuntu 16.04默认未安装,无需设置。CentOS7下可修改配置文件/etc/sysconfig/selinux,设置SELINUX=disabled ,重启后永久关闭。
IPV4转发:
必须开启!Ubuntu 16.04下默认已启用,无需设置。
防火墙:
Ubuntu默认未启用UFW防火墙,无需设置。也可手工关闭:sudo ufw disable
禁用SWAP:
一定要禁用swap,否则kubelet组件无法运行,永久禁用swap可以直接修改/etc/fstab文件,注释掉swap项。swapoff -a 只是临时禁用,下次关机重启又恢复原样;
启用Cgroup:
修改配置文件/etc/default/grub,启用cgroup内存限额功能,配置两个参数:
GRUB_CMDLINE_LINUX_DEFAULT="cgroup_enable=memory swapaccount=1"
GRUB_CMDLINE_LINUX="cgroup_enable=memory swapaccount=1"
注意:要执行sudo update-grub 更新grub,然后重启系统后生效。
SSH免密登录:
ssh-keygen 全部回车
ssh-copy-id 用户名@IP
用户名为非root用户,执行命令时不要加sudo,本机也要。
RKE部署用户:
1、RKE部署用户是cluster.yml配置文件中的用户,也就是上述能ssh免密登录到其他机器的用户;
2、如果使用普通用户进行RKE安装,要将普通用户(如user01)加入到docker组,命令:sudo usermod -aG docker user01 注意:重启系统以后才能生效,只重启Docker服务是不行的!重启后,user01用户也可以直接使用docker run命令。
4、在Ubuntu上使用apt安装完docker后,会自动创建docker用户组,无需手工创建docker组,只需要将部署RKE的用户(如user01)加入到docker组即可,查看是否存在docker组、以及user01用户是否在docker组中,可以直接查看/etc/group文件;
5、修改配置文件/etc/ssh/sshd_config,将PermitRootLogin prohibit-password 改为PermitRootLogin yes ,允许root远程ssh登录;
取消注释#AuthorizedKeysFile %h/.ssh/authorized_keys ,允许记录授权秘钥文件;
RKE下载
https://github.com/rancher/rke/releases
rke_linux-amd64这个版本
yml文件下载
我下载的是公用证书,自签名类似,关键是下面几步
https://raw.githubusercontent.com/rancher/rancher/e9d29b3f3b9673421961c68adf0516807d1317eb/rke-templates/3-node-certificate-recognizedca.yml
下载之后,改名成自己喜欢的名称
注意需要配置的地方:
节点配置
nodes:
- address: 1.1.1.1
user: root
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
- address: 2.2.2.2
user: root
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
- address: 3.3.3.3
user: root
role: [controlplane,etcd,worker]
ssh_key_path: ~/.ssh/id_rsa
address 为自己的IP
用户名为可以免密登录的用户名。
以下为关键的证书配置
一般证书名为两个:
fullchain.pem与privkey.pem
自签名是三个,类似,具体位置见官方文档 cat FILENAME | base64 -w0
这个文件名是刚才证书的文件名,使用证书的文件生成base64 字符串,输入yml文档中
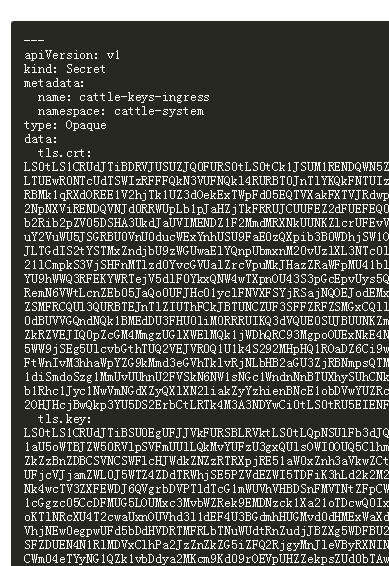
apiVersion: v1
kind: Secret
metadata:
name: cattle-keys-ingress
namespace: cattle-system
type: Opaque
data:
tls.crt:
tls.key:
注意这里的格式,在输入之前先备份,base64字条串为新起来行,顶行或crt:后面有空格
FQDN配置
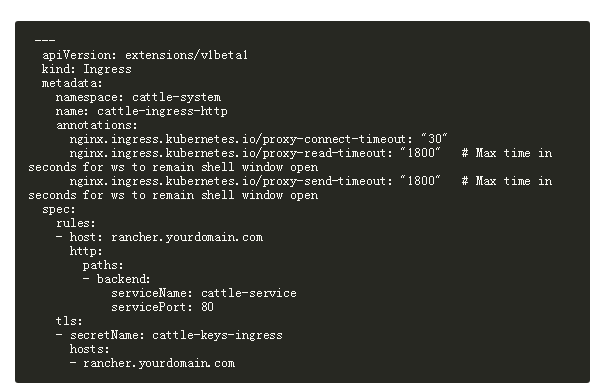
需要修改两处:
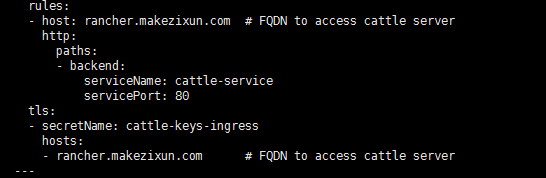
到些处,所有准备工作已经完成
./rke_linux-amd64 up --config rancher-cluster.yml 正式配置
不报错就成功
全部成功后,使用配置的域名访问,其它与单机安装一样。配置的域名就是FQDN。
rancher2 HA部署注意事项的更多相关文章
- Hadoop 学习笔记 (九) hadoop2.2.0 生产环境部署 HDFS HA部署方法
step1:将安装包hadoop-2.2.0.tar.gz存放到某一个目录下,并解压 step2:修改解压后的目录中的文件夹/etc/hadoop下的xml配置文件(如果文件不存在,则自己创建) 包括 ...
- ASP.NET生成WORD文档,服务器部署注意事项
网上转的,留查备用,我服务器装的office2007所以修改的是Microsoft Office word97 - 2003 文档这一个. ASP.NET生成WORD文档服务器部署注意事项 1.Asp ...
- wildfly8.1部署注意事项
wildfly8.1部署注意事项 jboss 最近新项目上线,本人部署过程中总结了以下几点比较关键的地方,看是否对大家有用处 服务器改成支持外网访问 在standalone.xml文件中找到 ...
- Harbor HA部署-使用Ceph RADOS后端
1. 前言 Harbor 1.4.0版本开始提供了HA部署方式,和非HA的主要区别就是把有状态的服务分离出来,使用外部集群,而不是运行在本地的容器上.而无状态的服务则可以部署在多个节点上,通过配置上层 ...
- [大数据] hadoop高可用(HA)部署(未完)
一.HA部署架构 如上图所示,我们可以将其分为三个部分: 1.NN和DN组成Hadoop业务组件.浅绿色部分. 2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存 ...
- k8s学习笔记(2)- Rancher2.x部署springboot应用及高可用、扩容
前言:上一篇介绍基于k3s环境,使用kubectl部署springboot简单项目应用,本篇介绍基于rancher2.x部署应用程序 1.上篇已部署一个springboot应用,我们可以通过ranch ...
- spark standalone zookeeper HA部署方式
虽然spark master挂掉的几率很低,不过还是被我遇到了一次.以前在spark standalone的文章中也介绍过standalone的ha,现在详细说下部署流程,其实也比较简单. 一.机器 ...
- Mesos编译步骤及部署注意事项(Ubuntu)
注意事项: 编译过程如果有错误提示少什么库,则相应的安装库即可在编译中出现 g++: internal compiler error: Killed (program cc1plus)的错误是因为内存 ...
- Hadoop HA部署
因为公司旧系统的Hadoop版本是2.2,所以在部署新系统时使用了旧系统. 但是在部署ResourceManager auto failover时发现其他nodemanager总是向0.0.0.0请求 ...
随机推荐
- 9. 一个list拆分成多个list返回
/** * @Title: splitList * @Description: 1个list分割成多个list * @param targe 原list * @para ...
- HTML学习-2标记标签-1
大致可以分为以下6类学习: 1.通用标签. 2.常用标签. 3.表格标签. 4.表单元素. 5.框架. 6.其他. 一.通用标签.及属性 1.<body></body>标签,主 ...
- day03-数据类型
数据类型 一.介绍 存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己的宽度,但宽度是可选的 mysql常用数据类型概括:#1. 数字: 整型:tinyint.int.bi ...
- class 方法
实例对象调用class方法时返回这个实例对象的isa指针,也就是对应的类对象: 类对象调用class方法时返回这个类对象本身. (注:如果想一直获得一个类的类对象,也就是isa指针,可以调用runti ...
- centos磁盘空间重新分配
将/home目录压缩一部分空间到/ ref: https://serverfault.com/a/811124/434124 https://stackoverflow.com/a/19969471/ ...
- oracle中去掉回车换行空格的方法详解
函数: 1.translate语法:TRANSLATE(char, from, to)用法:返回将出现在from中的每个字符替换为to中的相应字符以后的字符串. 若from比to ...
- Nginx反向代理时tomcat日志获取真实IP
对于nginx+tomcat这种架构,如果后端tomcat配置保持默认,那么tomcat的访问日志里,记录的就是前端nginx的IP地址,而不是真实的访问IP.因此,需要对nginx.tomcat做如 ...
- linux 排查page的状态问题
最近遇到一个page的释放异常的问题,堆栈如下: [ 1000.691858] BUG: Bad page state in process server.o pfn:309d22 [ mapcoun ...
- ORACLE表空间操作实例
本文主要介绍oracle表空间常见的操作实例,包括创建.查询.增加.删除.修改.表空间和数据文件常用的数据字典和动态性能视图包括v$dbfile.v$datafile.v$tempfile.dba_s ...
- 16.0 Auth0注册与设置
首先呢?注册https://manage.auth0.com 填写回调网页,意思是当我们点sign in 那个按钮的时候 会访问这个官网 这个官网又回调下面的网页,不然会报错.这个网站因为我们是开发所 ...