最邻近规则分类(K-Nearest Neighbor)KNN算法
自写代码:
# Author Chenglong Qian from numpy import * #科学计算模块
import operator #运算符模块 def createDaraSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])#创建4行2列的数组
labels=['A',"A",'B','B']#标签列表
return group,labels group,labels=createDaraSet() '''k—近邻算法'''
def classify0(inX,dataSet,labels,k): #inX:需要分类的向量,dataSet:训练样本,labels:标签,k:临近数目
'''求距离'''
dataSetSize=dataSet.shape[0] #样本数据行数,即样本的数量
diffMat=tile(inX,(dataSetSize,1))-dataSet #(来自numpy)tile:重复数组;将inX重复dataSetSize行,1列次;获得每组数据的差值(Xi-X,Yi-Y)
sqDiffMat=diffMat**2 #求平方
sqDistances=sqDiffMat.sum(axis=1) #sum(axis=1)矩阵每一行相加,sum(axis=0)每一列相加
distances=sqDistances**0.5 #开根号
sortedDistIndicies=distances.argsort() #argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。
classCount={}
'''排序'''
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]] #sortedDistIndicies[i]第i+1小元素的索引
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1 #classCount.get(voteIlabel,0)返回字典classCount中voteIlabel元素对应的值,若无,则将其设为0
#这里表示记录某一标签的数量
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)#sorted(需要排序的list,key=自定义排序方式,是否反转排序结果)
#items 将字典以列表形式返回 (python3.5中无 :iteritems将字典以迭代器形式返回)
#itemgetter函数用于获取对象的第几维的数据 operator.itemgetter(1)使用第二个元素进行排序
return sortedClassCount[0][0] '''把文本记录转换成矩阵Numpy的解析程序'''
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines() #readlines():返回由文件中剩余的文本(行)组成的列表
numberOfLines=len(arrayOLines) #返回对象的长度
returnMat=zeros((numberOfLines,3))
classLabelVector=[]
index=0
for line in arrayOLines:
line=line.strip() #strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
listFromLine=line.split('\t') #split() 通过指定分隔符对字符串进行切片
returnMat[index,:]=listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector
库代码
from sklearn import neighbors
from sklearn import datasets knn = neighbors.KNeighborsClassifier() iris = datasets.load_iris() print iris knn.fit(iris.data, iris.target) predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]])
print "hello"
#print ("predictedLabel is :" + predictedLabel)
print predictedLabel
最邻近规则分类(K-Nearest Neighbor)KNN算法的更多相关文章
- K NEAREST NEIGHBOR 算法(knn)
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法和K-M ...
- K Nearest Neighbor 算法
文章出处:http://coolshell.cn/articles/8052.html K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KN ...
- kNN(K-Nearest Neighbor)最邻近规则分类
KNN最邻近规则,主要应用领域是对未知事物的识别,即推断未知事物属于哪一类,推断思想是,基于欧几里得定理,推断未知事物的特征和哪一类已知事物的的特征最接近: K近期邻(k-Nearest Neighb ...
- kNN(K-Nearest Neighbor)最邻近规则分类(转)
KNN最邻近规则,主要应用领域是对未知事物的识别,即判断未知事物属于哪一类,判断思想是,基于欧几里得定理,判断未知事物的特征和哪一类已知事物的的特征最接近: K最近邻(k-Nearest Neighb ...
- 机器学习--最邻近规则分类KNN算法
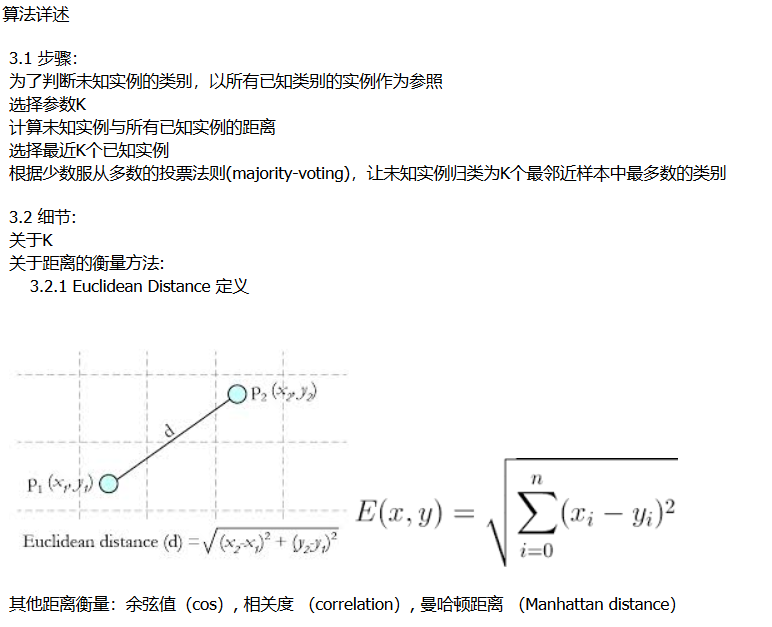
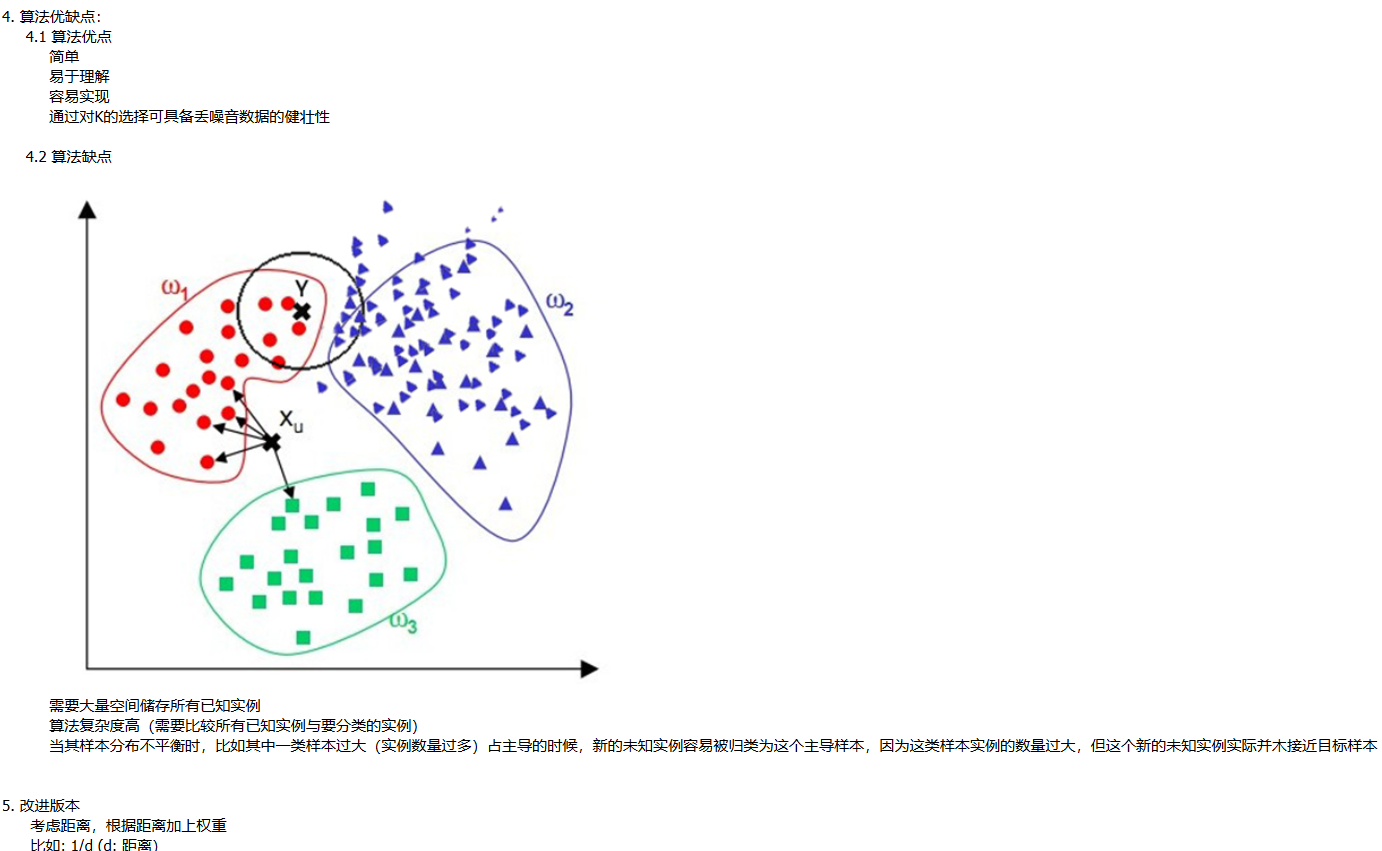
理论学习: 3. 算法详述 3.1 步骤: 为了判断未知实例的类别,以所有已知类别的实例作为参照 选择参数K 计算未知实例与所有已知实例的距离 选 ...
- python_机器学习_最临近规则分类(K-Nearest Neighbor)KNN算法
1. 概念: https://scikit-learn.org/stable/modules/neighbors.html 1. Cover和Hart在1968年提出了最初的临近算法 2. 分类算法( ...
- 4.2 最邻近规则分类(K-Nearest Neighbor)KNN算法应用
1 数据集介绍: 虹膜 150个实例 萼片长度,萼片宽度,花瓣长度,花瓣宽度 (sepal length, sepal width, petal length and petal wi ...
- 最邻近规则分类KNN算法
例子: 求未知电影属于什么类型: 算法介绍: 步骤: 为了判断未知实例的类别,以所有已知类别的实例作为参照 选择参数K 计算未知实例与所有已知实例的距离 选择最近K个已 ...
- K nearest neighbor cs229
vectorized code 带来的好处. import numpy as np from sklearn.datasets import fetch_mldata import time impo ...
随机推荐
- javascript中常见错误类型
js中控制台报错主分两大类: 第一类:语法错误,这一类错误在javascript预解析的过程中如果遇到,则会导致整个js文件都无法执行. 另一类:统称为异常,这一类的错误会导致在错误出现的那一行之后的 ...
- POJ1222(SummerTrainingDay01-E)
EXTENDED LIGHTS OUT Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 11078 Accepted: 7 ...
- js同时获取多个同name的input框的值
demo代码 <!doctype html> <html ng-app="a3_4"> <head> <title>表头排序< ...
- 安装nvm管理不同的node版本
在工作或者学习中,偶尔会遇到需要切换不同node版本的需求,幸好有神器nvm可以帮我们解决问题.下面我们就来讲解如何在window系统上安装nvm!
- 去除img默认的边框
//当img属性src没有值时,会有难看的边框和难看的一个小图 有什么办法去掉呢? <img src=" " /> //不要这样写 <img /> ...
- CSS布局之——对齐方式
一.水平居中: (1). 行内元素的水平居中? 如果被设置元素为文本.图片等行内元素时,在父元素中设置text-align:center实现行内元素水平居中,将子元素的display设置为inline ...
- Android--将实体类转化成Json和Map的基类
package com.newair.talk.base; import android.text.TextUtils; import com.google.gson.Gson; import jav ...
- JS前端创建CSV或Excel文件并浏览器导出下载
长期以来,在做文件下载功能的时候都是前端通过ajax把需要生成的文件的内容参数传递给后端,后端通过Java语言将文件生成在服务器,然后返回一个文件下载的连接地址url.前端通过location.hre ...
- Centos7 用yum命令安装LAMP环境(php+Apache+Mysql)以及php扩展
1.yum -y update // 更新系统 1.1)yum -y install gcc g++ gcc-c++ make kernel-devel kernel-headers 1.2)v ...
- 团队项目第二阶段个人进展——Day2
一.昨天工作总结 冲刺第二天,基本完成了自己对第二阶段信息发布功能完善的规划 二.遇到的问题 不知道后端数据该如何封装处理 三.今日工作规划 先重新布局发布页面,并添加重置按钮