大数据入门第十五天——HBase整合:云笔记项目
一、功能简述
1.笔记本管理(增删改)
2.笔记管理
3.共享笔记查询功能
4.回收站
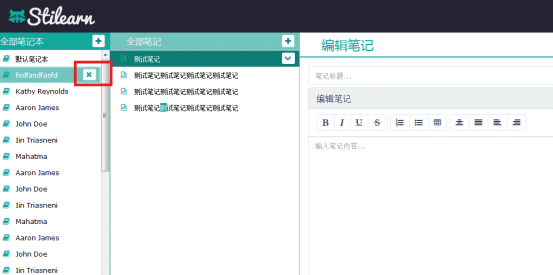
效果预览:
二、库表设计
1.设计理念
将云笔记信息分别存储在redis和hbase中。
redis(缓存):存储每个用户的笔记本信息
hbase(持久层):存储用户的笔记本信息、笔记本下的笔记列表、笔记具体信息。
2.设计概要
redis:

hbase:
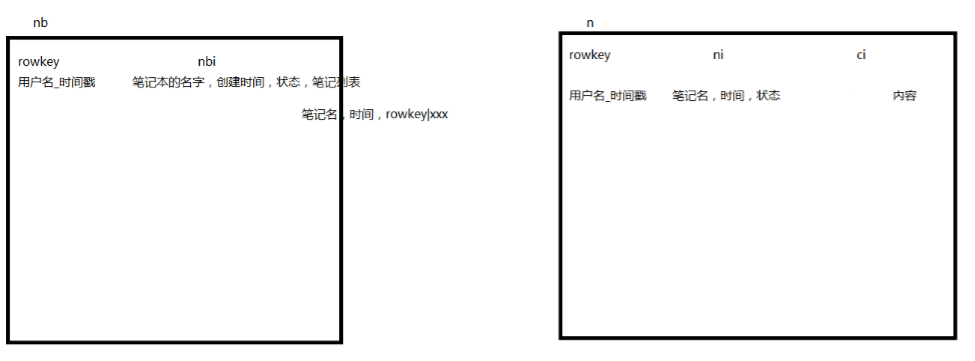
// 分别是笔记本和笔记
3.hbase建表语句
create ‘nb’,’nbi’
create ‘n’,’ni’,’ci’
// 回顾建表语句,hbase的列是可以动态增删的!
redis回顾,参考之前随笔:http://www.cnblogs.com/jiangbei/p/7255994.html
三、功能列表
1.登录
简单登录,不再赘述(其中的加载properties等可以使用spring自带的工具类/hutool工具类)
2.笔记本
查询所有笔记本
1、在js端,通过页面全局加载方法($(function(){})),调用ajax调用后台,查询用户所有笔记本列表
2、后台通过登录名loginName从redis中查询出笔记本列表信息,返回给前台。如果redis中查不到,在hbase中查询,如果hbase中查询到,恢复redis信息。
3、设置特殊笔记本的rowkey
回收站
rowkey:用户名_0000000000000
收藏夹
rowkey:用户名_0000000000001
活动笔记
rowkey:用户名_0000000000002
4、初始化判空
新增笔记本
1、前台输入笔记本名
2、前台向后台传入的参数
笔记本的名字
3、后台封装
a、从session中获取用户名
b、创建时间戳
c、封装rowkey
d、保存到redis
key:用户名
value:list<rowkey|笔记本的名字|创建时间|状态>
步骤:
1、获取jedis连接
2、jedis.rpush(用户名, rowkey|笔记本的名字|创建时间|状态)
3、close
e、保存到hbase
rowkey:封装的rowkey
列:笔记本名字,创建时间、状态
步骤:
1、创建表链接
2、创建put(rowkey)
3、put.add(列)
4、table.put(put)
5、close
f、事务:
当redis失败后,所有步骤停止
当redis成功,hbase成功,即成功
当redis成功,hbase失败,删除redis的内容(lrem)
删除笔记本
1、前台传过来的参数:笔记本的rowkey,笔记本的名字
2、后台:
a、action查询笔记本下是否有笔记,有笔记返回false
3、删除redis
a、拼串:rowkey|笔记本名|时间戳|状态
b、jedis.lrem(用户名,删除几次,rowkey|笔记本名|时间戳|状态)
4、删除hbase
a、获取rowkey
b、删除
5、事务:
删除都成功
redis不成功,都不成功
redis成功,hbase不成功,增加redis
修改笔记本
1、前台输入:新的笔记本的名字
2、前台向后抬传入的参数:新的笔记本的名字,旧的笔记本的名,rowkey
3、后台的action处理
a、分割rowkey,获取时间戳,用户名
4、redis
a、拼装旧的串:rowkey|旧的名字|时间戳|状态
b、拼新串:rowkey|新的名字|时间戳|状态
c、删除旧的串:jedis.lrem( 用户名,几次,旧串)
d、加新的串:jedis.rpush(用户名,新串)
5、hbase
通过rowkey设置新的名字
封装put(rowkey)
put.add(新的名字)
table.put(put);
6、事务:
redis成功,hbase成功
redis失败,都失败
redis成功,hbase失败,删除redis的新的名字,添加旧的名字
3.笔记
查询所有笔记
1、点击笔记本时,查询笔记本下的所有笔记
2、通过笔记本rowKey到redis中查询笔记列表,如果redis查询不到,从hbase中查询,恢复redis。
3、初始化判空
1、前台传过来的参数:笔记本的rowkey
2、后台处理hbase
a、创建nb表的表链接
b、创建get(笔记本的rowkey)
c、处理result结果集,json
d、将json转换为list
e、处理list中的值,用“|”分割每列,封装到n个note中
f、返回前台
新增笔记
1、前台输入的参数:笔记的名字
2、前台传到后台的参数:笔记本的rowkey,笔记的名字
3、action的处理
a、创建时间戳
b、用用户名和时间戳拼装笔记的rowkey
4、后台处理hbase的nb表
将笔记添加到笔记本的笔记列表中
a、获取表链接
b、取出笔记本的历史笔记列表
c、将历史笔记列表中添加新的笔记信息
d、创建put(笔记本的rowkey)
e、put.add(新的笔记列表)
f、close
5、hbase的n表
a、将笔记的信息存到n表中
笔记详情
1、前台传到后台的参数:笔记的rowkey
2、后台处理:
查询笔记表
修改笔记
1、前台输入的参数:笔记的名字,笔记的内容
2、前台向后台传的参数:笔记本的rowkey、笔记的rowkey、新笔记的名字、笔记的内容、旧的笔记的名字
3、修改nb表
a、获取nb表的表链接
b、查询历史的笔记信息
c、将笔记信息装成list
d、拼装旧的笔记信息的串
e、list.remove(旧的笔记信息的串)
f、拼装新的笔记信息的串
g、list.add(新的笔记信息的串)
h、添加操作htable.put().
4、修改n表
重新添加笔记名字和笔记内容
5、事务:
a、nb表失败,都失败
b、都成功
c、nb成功,n失败,还原nb表的笔记列表
迁移笔记
1、前台传过来的参数:旧的笔记本的rowkey,新的笔记本的rowkey,笔记的rowkey,笔记的名字
2、后台处理
拼装笔记信息的串
3、修改旧的笔记本
a、将笔记本下的笔记列表查出来
b、删除笔记信息
4、修改新的笔记本
a、将笔记本下的笔记列表查出来
b、添加笔记信息
5、事务:
a、都成功
b、都失败
c、第一个操作成功,第二个操作失败,还原第一个操作
大数据入门第十五天——HBase整合:云笔记项目的更多相关文章
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
一.hbase数据模型 完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html 1.rowkey 与nosql数据库们一样, ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- 大数据入门第十六天——流式计算之storm详解(二)常用命令与wc实例
一.常用命令 1.提交命令 提交任务命令格式:storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称] torm jar examples/storm-starter/storm-st ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
随机推荐
- PHP学习目标
课程阶段学习目标 阶段一: 目标:能够使用DIV+CSS布局出任意的网页页面 说明:根据PSD图设计,使用DIV+CSS布局符合WEB标准.多浏览器兼容的网页,能建立网站制作所需要的模板 阶段二: 目 ...
- react单页面应用的Nginx配置问题
项目中多数使用react单页面开发,路由使用react-router的browser-router,这样页面访问路径看起来像是真实的,如http://xx.xxx.xxx/a/b.但当项目访问路径为多 ...
- 【转】boost库之geometry
#include <boost/assign.hpp> #include <boost/geometry/geometry.hpp> #include <boost/ge ...
- Git创建本地仓库并推送至远程仓库
作为一名测试同学,日常工作经常需要checkout研发代码进行code review.自己极少有机会创建仓库,一度以为这是一个非常复杂过程.操作一遍后,发现也不过六个步骤,so,让我们一起揭开这神秘面 ...
- 使用MonkeyTest对Android客户端进行压力测试
目录 monkey命令简介 monkey命令参数说明 自动化实例 如何通过日志定位问题 1.monkey命令简介 Monkey是Android中的一个命令行工具,可以运行在模拟器里或实际设备中.它 ...
- 树莓派上启动nfs server
1. nfs 是什么 (略)http://vbird.dic.ksu.edu.tw/linux_server/linux_redhat9/0330nfs.php 2. 安装 nfs-kernel-se ...
- 使用SQL Server Management Studio操作replication时,要用机器名登录,不要用IP地址
如果你在使用SSMS(SQL Server Management Studio)登录SQL Server时,使用的是IP地址,如下图所示: 当你操作replication时,会报错: 从上面的错误提示 ...
- 从零开始学习VoltDB
1.什么是VoltDB? 是一个优化吞吐率的高性能集群开源SQLRDBMS(Database Management System),它是一个内存关系型数据库,既获得了nosql的良好可扩展性,高吞吐量 ...
- 转:sql语句优化
性能不理想的系统中除了一部分是因为应用程序的负载确实超过了服务器的实际处理能力外,更多的是因为系统存在大量的SQL语句需要优化. 为了获得稳定的执行性能,SQL语句越简单越好.对复杂的SQL语句,要设 ...
- 华为MSTP负载均衡配置示例
以下内容摘自由华为公司授权并审核通过,今年元月刚刚出版上市的<华为交换机学习指南>一书:http://item.jd.com/11355972.html,http://product.da ...