大数据入门第十四天——Hbase详解(一)入门与安装配置
一、概述
1.什么是Hbase
根据官网:https://hbase.apache.org/
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统
中文简明介绍:
Hbase是分布式、面向列的开源数据库(其实准确的说是面向列族)。HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hbase提供高性能的计算能力,Zookeeper为Hbase提供稳定服务和Failover机制,因此我们说Hbase是一个通过大量廉价的机器解决海量数据的高速存储和读取的分布式数据库解决方案。
2.什么是列式存储
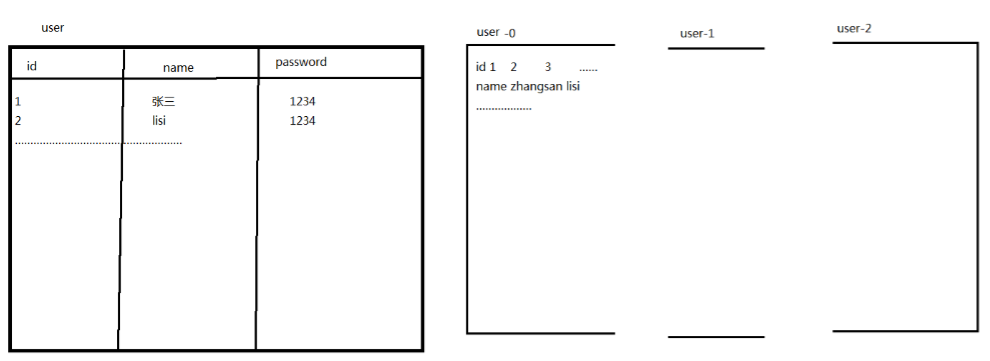
使用网友的图就是:


其中更加深入的内部原理讲解,参考:http://blog.csdn.net/lifuxiangcaohui/article/details/39891099
http://lib.csdn.net/article/datastructure/8951
3.为什么需要Hbase
以下介绍了一种Hbase出现的场景:

更多完整的原因介绍,参考:http://www.thebigdata.cn/HBase/30332.html
与传统数据库的对比如下:
1、传统数据库遇到的问题:
1)数据量很大的时候无法存储
2)没有很好的备份机制
3)数据达到一定数量开始缓慢,很大的话基本无法支撑
2、HBASE优势:
1)线性扩展,随着数据量增多可以通过节点扩展进行支撑
2)数据存储在hdfs上,备份机制健全
3)通过zookeeper协调查找数据,访问速度块。
4.hbase中的角色
1、一个或者多个主节点,Hmaster
2、多个从节点,HregionServer
二、安装与配置
1.上传
这里暂时使用hbase0.99,其他与Hadoop的兼容性问题,参考文档Basic Prerequisites处,另外,此文档有翻译版本:点击查看
这次我们使用sftp来上传(比古老的rz/sz要更快),操作参考之前随笔:http://www.cnblogs.com/jiangbei/p/8041713.html
2.解压
先在一台机器上操作,之后再复制发送到其他集群中的机器
[hadoop@mini1 ~]$ tar -zxvf hbase-0.99.-bin.tar.gz -C apps/
// 之后是可以删除这个压缩包的
3.重命名
[hadoop@mini1 apps]$ mv hbase-0.99./ hbase
//当然,这一步是可选的
4.修改环境变量
[hadoop@mini1 apps]$ sudo vim /etc/profile
增加以下两行
export HBASE_HOME=/home/hadoop/apps/hbase
export PATH=$PATH:$HBASE_HOME/bin
[hadoop@mini1 apps]$ source /etc/profile
5.修改配置文件
现在来看conf/下的文件,基本也能摸索出规律了:
[hadoop@mini1 hbase]$ cd conf/
[hadoop@mini1 conf]$ ls
hadoop-metrics2-hbase.properties hbase-policy.xml regionservers
hbase-env.cmd hbase-site.xml
hbase-env.sh log4j.properties
xxx-site:核心配置文件;xxx-env.sh:环境配置(以防PATH未配);没有后缀名的:配置从节点
修改hbase-env.sh:
# JDK
export JAVA_HOME=/opt/java/jdk1..0_151
# 通过hadoop配置文件,找到hadoop集群,请正确选择配置文件地址!
export HBASE_CLASSPATH=/home/hadoop/apps/hadoop-2.6./etc/hadoop
# 是否使用自带的zookeeper,false表示使用自己的
export HBASE_MANAGES_ZK=false
配置hbase-site.xml:
<configuration>
<!--指定hbase集群主控节点 -->
<property>
<name>hbase.master</name>
<value>mini1:60000</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!-- 设置hbase数据库存放数据的目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mini1:9000/hbase</value>
</property>
<!-- 打开hbase分布模式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper集群节点名,因为是由zookeeper表决算法决定的-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>mini1,mini2,mini3</value>
</property>
<!-- 指zookeeper集群data目录-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/apps/hbase/tmp/zookeeper</value>
</property>
</configuration>
配置regionservers
mini2
mini3
6.分发配置到从节点
如果没有配置免密登录,请先参考这里
scp -r hbase/ mini2:/home/hadoop/apps/
scp -r hbase/ mini3:/home/hadoop/apps/
7.启动
需要先启动hadoop:
[hadoop@mini1 apps]$ start-dfs.sh
一键启动hbase也是非常类似的:
start-hbase.sh
通过Jps可以查看!
悔不该当初通过root装的zookeeper集群,现在启动还得通过root和绝对路径启动!所以这里选择重装zk集群!
// 或者切换到root使用一键启动脚本 startZK.sh
//这里0.99.2版本无法访问mini1:60010端口,不知何解(也不是hadoop安全模式问题),也不是1.0以后版本的问题:点击查看
不过这里web页面也不是重点,具体解决待补充
单独启动与停止脚本与hadoop基本类似:
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
8.配置多master
在任意的安装了hbase的机器上启动hmaster.执行 命令:
local-master-backup.sh start
大数据入门第十四天——Hbase详解(一)入门与安装配置的更多相关文章
- 大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
一.hbase数据模型 完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html 1.rowkey 与nosql数据库们一样, ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据入门第十五天——HBase整合:云笔记项目
一.功能简述 1.笔记本管理(增删改) 2.笔记管理 3.共享笔记查询功能 4.回收站 效果预览: 二.库表设计 1.设计理念 将云笔记信息分别存储在redis和hbase中. redis(缓存):存 ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 大数据笔记(十四)——HBase的过滤器与Mapreduce
一. HBase过滤器 1.列值过滤器 2.列名前缀过滤器 3.多个列名前缀过滤器 4.行键过滤器5.组合过滤器 package demo; import javax.swing.RowFilter; ...
随机推荐
- Tracing 在PeopleSoft 程序中怎么开启
本文介绍一些常用的跟踪方法在Applications,Application Engine,PeopleSoft,Integration Broker,Cobol中. 1.Application En ...
- singleInstance和singleTask导致startActivityForResult回调失败
先来了解下这两种启动模式: 1.singleInstance,全局唯一,它的实例在全局(即在众多任务栈中)是唯一的,它单独地存在于属于自己的任务栈中,而且这个任务栈没有其他实例. 2.singleTa ...
- Python+Selenium笔记(十一):配置selenium Grid
(一) 前言 Selenium Grid可以将测试分布在若干个物理或虚拟机器上,从而实现分布方式或并行方式执行测试. 这个链接是官方的相关说明. https://github.com/Selenium ...
- Fusion 360教程合集27部
Fusion 360教程合集27部 教程格式:MP4和flv 等格式 使用版本:教程不是一年出的教程,各个版本都有 (教程软件为英文版) 教程格式:MP4.FLV等视频格式 清晰度:可以看清软件上的文 ...
- c#中(&&,||)与(&,|)的区别和应用
对于(&&,||),运算的对象是逻辑值,也就是True/False &&相当与中文的并且,||相当于中文的或者 .(叫做逻辑运算符又叫短路运算符) 运算结果只有下列四种 ...
- 如何使用 Azure PowerShell 在 Azure Marketplace 中查找 Windows VM 映像
本主题介绍如何使用 Azure PowerShell 在 Azure Marketplace 中查找 VM 映像. 创建 Windows VM 时使用此信息来指定 Marketplace 映像. 确保 ...
- redie config 详解
# redis 配置文件示例 # 当你需要为某个配置项指定内存大小的时候,必须要带上单位,# 通常的格式就是 1k 5gb 4m 等酱紫:## 1k => 1000 bytes# 1kb =&g ...
- PHP 定界符
双引号和单引号是常用的字符串定界符,在php4.0以后 还可以使用字符串定界符<<<,功能和双引号差不多,用法如下 <<<标识符 字符串 标识符 其中最后的标识符必 ...
- 【转】Java学习---线程间的通信
[原文]https://www.toutiao.com/i6572378564534993415/ 两个线程间的通信 这是我们之前的线程. 执行效果:谁抢到资源,谁运行~ 实现线程交替执行: 这里主要 ...
- 数据结构习题Pop Sequence的理解----小白笔记^_^
Pop Sequence(25 分) Given a stack which can keep M numbers at most. Push N numbers in the order of 1, ...