大数据入门第十五天——HBase整合:云笔记项目
一、功能简述
1.笔记本管理(增删改)
2.笔记管理
3.共享笔记查询功能
4.回收站
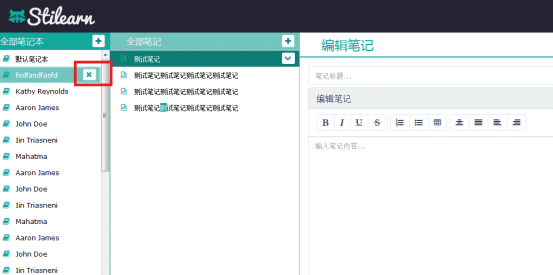
效果预览:
二、库表设计
1.设计理念
将云笔记信息分别存储在redis和hbase中。
redis(缓存):存储每个用户的笔记本信息
hbase(持久层):存储用户的笔记本信息、笔记本下的笔记列表、笔记具体信息。
2.设计概要
redis:

hbase:
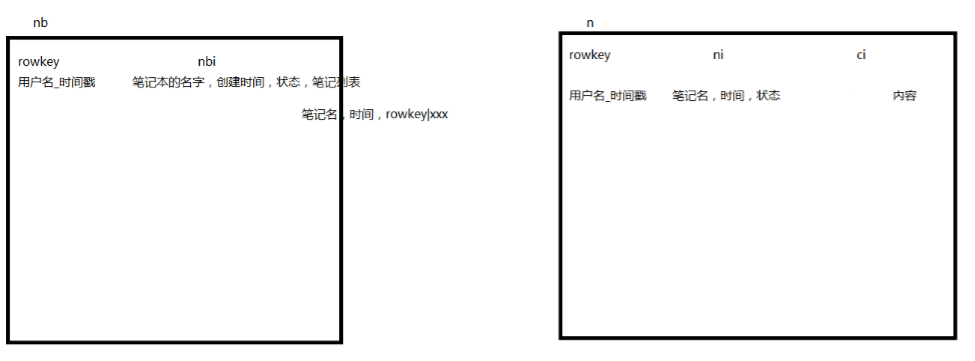
// 分别是笔记本和笔记
3.hbase建表语句
create ‘nb’,’nbi’
create ‘n’,’ni’,’ci’
// 回顾建表语句,hbase的列是可以动态增删的!
redis回顾,参考之前随笔:http://www.cnblogs.com/jiangbei/p/7255994.html
三、功能列表
1.登录
简单登录,不再赘述(其中的加载properties等可以使用spring自带的工具类/hutool工具类)
2.笔记本
查询所有笔记本
1、在js端,通过页面全局加载方法($(function(){})),调用ajax调用后台,查询用户所有笔记本列表
2、后台通过登录名loginName从redis中查询出笔记本列表信息,返回给前台。如果redis中查不到,在hbase中查询,如果hbase中查询到,恢复redis信息。
3、设置特殊笔记本的rowkey
回收站
rowkey:用户名_0000000000000
收藏夹
rowkey:用户名_0000000000001
活动笔记
rowkey:用户名_0000000000002
4、初始化判空
新增笔记本
1、前台输入笔记本名
2、前台向后台传入的参数
笔记本的名字
3、后台封装
a、从session中获取用户名
b、创建时间戳
c、封装rowkey
d、保存到redis
key:用户名
value:list<rowkey|笔记本的名字|创建时间|状态>
步骤:
1、获取jedis连接
2、jedis.rpush(用户名, rowkey|笔记本的名字|创建时间|状态)
3、close
e、保存到hbase
rowkey:封装的rowkey
列:笔记本名字,创建时间、状态
步骤:
1、创建表链接
2、创建put(rowkey)
3、put.add(列)
4、table.put(put)
5、close
f、事务:
当redis失败后,所有步骤停止
当redis成功,hbase成功,即成功
当redis成功,hbase失败,删除redis的内容(lrem)
删除笔记本
1、前台传过来的参数:笔记本的rowkey,笔记本的名字
2、后台:
a、action查询笔记本下是否有笔记,有笔记返回false
3、删除redis
a、拼串:rowkey|笔记本名|时间戳|状态
b、jedis.lrem(用户名,删除几次,rowkey|笔记本名|时间戳|状态)
4、删除hbase
a、获取rowkey
b、删除
5、事务:
删除都成功
redis不成功,都不成功
redis成功,hbase不成功,增加redis
修改笔记本
1、前台输入:新的笔记本的名字
2、前台向后抬传入的参数:新的笔记本的名字,旧的笔记本的名,rowkey
3、后台的action处理
a、分割rowkey,获取时间戳,用户名
4、redis
a、拼装旧的串:rowkey|旧的名字|时间戳|状态
b、拼新串:rowkey|新的名字|时间戳|状态
c、删除旧的串:jedis.lrem( 用户名,几次,旧串)
d、加新的串:jedis.rpush(用户名,新串)
5、hbase
通过rowkey设置新的名字
封装put(rowkey)
put.add(新的名字)
table.put(put);
6、事务:
redis成功,hbase成功
redis失败,都失败
redis成功,hbase失败,删除redis的新的名字,添加旧的名字
3.笔记
查询所有笔记
1、点击笔记本时,查询笔记本下的所有笔记
2、通过笔记本rowKey到redis中查询笔记列表,如果redis查询不到,从hbase中查询,恢复redis。
3、初始化判空
1、前台传过来的参数:笔记本的rowkey
2、后台处理hbase
a、创建nb表的表链接
b、创建get(笔记本的rowkey)
c、处理result结果集,json
d、将json转换为list
e、处理list中的值,用“|”分割每列,封装到n个note中
f、返回前台
新增笔记
1、前台输入的参数:笔记的名字
2、前台传到后台的参数:笔记本的rowkey,笔记的名字
3、action的处理
a、创建时间戳
b、用用户名和时间戳拼装笔记的rowkey
4、后台处理hbase的nb表
将笔记添加到笔记本的笔记列表中
a、获取表链接
b、取出笔记本的历史笔记列表
c、将历史笔记列表中添加新的笔记信息
d、创建put(笔记本的rowkey)
e、put.add(新的笔记列表)
f、close
5、hbase的n表
a、将笔记的信息存到n表中
笔记详情
1、前台传到后台的参数:笔记的rowkey
2、后台处理:
查询笔记表
修改笔记
1、前台输入的参数:笔记的名字,笔记的内容
2、前台向后台传的参数:笔记本的rowkey、笔记的rowkey、新笔记的名字、笔记的内容、旧的笔记的名字
3、修改nb表
a、获取nb表的表链接
b、查询历史的笔记信息
c、将笔记信息装成list
d、拼装旧的笔记信息的串
e、list.remove(旧的笔记信息的串)
f、拼装新的笔记信息的串
g、list.add(新的笔记信息的串)
h、添加操作htable.put().
4、修改n表
重新添加笔记名字和笔记内容
5、事务:
a、nb表失败,都失败
b、都成功
c、nb成功,n失败,还原nb表的笔记列表
迁移笔记
1、前台传过来的参数:旧的笔记本的rowkey,新的笔记本的rowkey,笔记的rowkey,笔记的名字
2、后台处理
拼装笔记信息的串
3、修改旧的笔记本
a、将笔记本下的笔记列表查出来
b、删除笔记信息
4、修改新的笔记本
a、将笔记本下的笔记列表查出来
b、添加笔记信息
5、事务:
a、都成功
b、都失败
c、第一个操作成功,第二个操作失败,还原第一个操作
大数据入门第十五天——HBase整合:云笔记项目的更多相关文章
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
一.hbase数据模型 完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html 1.rowkey 与nosql数据库们一样, ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- 大数据入门第十六天——流式计算之storm详解(二)常用命令与wc实例
一.常用命令 1.提交命令 提交任务命令格式:storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称] torm jar examples/storm-starter/storm-st ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
随机推荐
- Asp Url汉字乱码的问题
1.js <a target="_blank" href="/asp/download.asp?File=' + escape(item.FileName) + ' ...
- WiFi 统一管理以及设备自动化测试实践
ATX 安卓设备 WiFi 统一管理以及设备自动化测试实践 (零散知识梳理总结) 此文为转载,感谢作者 目录 众所周知,安卓单台设备的UI自动化测试已经比较完善了,有数不清的自动化框架或者工具.但 ...
- Vue.js入门系列(一)
Vue官网: https://cn.vuejs.org/v2/guide/forms.html#基础用法 [入门系列] (一) http://www.cnblogs.com/gdsblog/p/78 ...
- 安卓ADB命令
查看连接的设备 adb devices -l FastBoot常用命令: fastboot erase system #擦除system分区 fastboot erase boot #擦除 ...
- mysql面试题目
昨天晚上无意中翻译到baidu的 dba(mysql,redis) 面试题,阅读了一下,发现没有一个自己能完美解释的.这确实是温床导致的思维懒惰. 具体几个问题如下: 1:MySQL InnoDB存储 ...
- python基础知识回顾之列表
在python 中,主要的常用数据类型有列表,元组,字典,集合,字符串.对于这些基础知识,应该要能够足够熟练掌握. 如何创建列表: # 创建一个空列表:定义一个变量,然后在等号右边放一个中括号,就创建 ...
- python基础学习19----socket网络编程
网络通信三要素 ip地址:InetAddress 网络中设备的标识,不易记忆,可用主机名(计算机的标识号) 端口号:用于标识进程的逻辑地址,不同进程的标识(正在运行的软件的标识号) 传输协议:通讯的规 ...
- 【转】Java学习---集合框架那些事
[原文]https://www.toutiao.com/i6593220692525711885/ Arraylist 与 LinkedList 异同 1. 是否保证线程安全: ArrayList 和 ...
- tp查询顺序
tp竟然可以跟据商品的id来进行排序查询的数据 记一些php中排序: sort()方法一维索引数组进行值升序排序 rsort()方法一维索引数组进行值降序排序 unsort()方法负责编写自定义排序操 ...
- ConcurrentModificationException探究
modCount ? 在ArrayList,LinkedList,HashMap等等的内部实现增,删,改中我们总能看到modCount的身影,modCount字面意思就是修改次数 // HashMap ...