软件工程实践-WC项目之C实现
1、Github项目地址
https://github.com/ShadowEvan/homework
- 基本功能
- -c 统计文件字符数(实现)
- -w 统计文件词数(实现)
- -l 统计文件行数(实现)
- 扩展功能
- -s 递归处理目录下符合条件的文件(实现)
- -a 返回文件代码行/空行/注释行(实现)
- 简单处理一般通配符(*, ?)(实现)
- 高级功能
- -x 支持图形界面(未实现)
2、PSP表格
|
PSP2.1 |
Personal Software Process Stages |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
20 | 30 |
|
· Estimate |
· 估计这个任务需要多少时间 |
1900 | 2340 |
|
Development |
开发 |
600 | 1200 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
90 | 120 |
|
· Design Spec |
· 生成设计文档 |
30 | 45 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
30 | 45 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 | 20 |
|
· Design |
· 具体设计 |
40 | 60 |
|
· Coding |
· 具体编码 |
240 | 300 |
|
· Code Review |
· 代码复审 |
120 | 180 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
120 | 180 |
|
Reporting |
报告 |
60 | 100 |
|
· Test Report |
· 测试报告 |
30 | 30 |
|
· Size Measurement |
· 计算工作量 |
20 | 30 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 30 |
|
合计 |
1920 | 2370 |
3、解题思路
拿到题目后,觉得基本功能比较容易实现,扩展功能递归遍历文件有点困难,需要查阅相关资料。我的方法主要是,打开文件后每次获取一个字符并进行处理。
(1)返回文件的字符数
思路:每获取一个非空字符及非转义字符如\n、\t则进行统计。
(2)返回文件的词数
思路:每遇到一个字母或数字则标记为进入词内状态并进行统计,词内状态下遇到字母或数字不统计,遇到其他字符则标记为词外状态。
(3)返回文件的行数
思路:行数上仅记录有效行数,即不包括文本或代码的空行不计在内,方法类似于词数统计。
(4)递归处理目录下符合条件的文件
思路:先识别文件名是否含有通配符,要求输入的第一个参数为-s,满足条件则开始获取程序当前路径,并递归遍历查找与模式匹配的文件名,按其他参数处理符合条件的文件。
这个功能应该是耗时最长完成的,主要原因在于对于一些文件处理的库和函数不够熟悉,需要花大量时间在网上查找并筛选合适的资料。在这方面有个缺陷就是,所查找到的库是有系统依赖性的,这意味着无法做到跨平台,因此还有许多改进空间。
(5)返回更复杂的数据
思路:方法大体与(2)和(3)一致,利用状态来统计,主要的难点在于多行注释以及各种边界情况,为此我另外设置一个函数来处理多行注释的问题。以下是我在这个功能中对一些概念的界定:
若注释前本行有代码,本行算代码行。
若本行仅有 { 或 } ,本行算空行。
若多行注释中包括空行,该空行算注释行。
4、设计实现过程
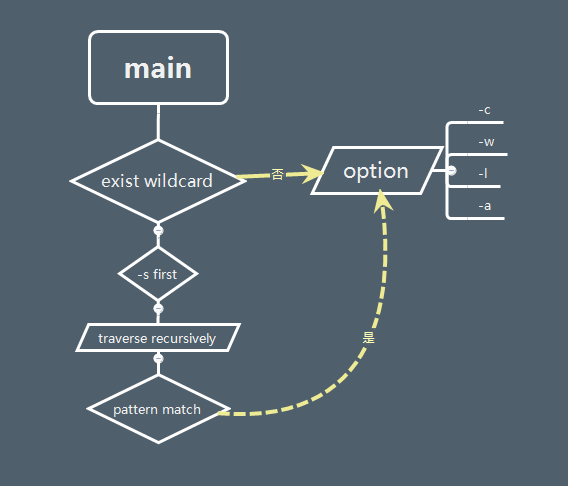
int option(int argc, char *argv[], char *file_name);
int recurrence(int argc, char *argv[], char *file_name);
int file_travesal(const char *dir, int argc, char *argv[], char *file_name);
int wildchar_match(char *file_name, char *pattern, int ignore_case);
unsigned int char_count(FILE *fp);
unsigned int word_count(FILE *fp);
unsigned int line_count(FILE *fp);
void code_count(FILE *fp);
5、代码说明
unsigned int char_count(FILE *fp)
{
unsigned int cc = ;
char ch; while ((ch = getc(fp)) != EOF) {
if (ch != ' ' && ch != '\n' && ch != '\t') {
cc++;
}
} return cc;
}
字符统计
unsigned int word_count(FILE *fp)
{
unsigned int wc = ;
char ch;
bool state = _OUT; while ((ch = getc(fp)) != EOF) {
if ((ch > 'z' || ch < 'a') && (ch > 'Z' || ch < 'A') && (ch > '' || ch < '')) {
if (state == _IN) {
state = _OUT;
}
} else if (state == _OUT) {
state = _IN;
wc++;
}
} return wc;
}
词数统计
unsigned int line_count(FILE *fp)
{
unsigned int lc = ;
char ch;
bool state = _OUT; while ((ch = getc(fp)) != EOF) {
if (ch != ' ' && ch != '\t' && ch != '\n' && state == _OUT) {
state = _IN;
lc++;
} else if ('\n' == ch) {
state = _OUT;
}
} return lc;
}
行数统计
void code_count(FILE *fp)
{
unsigned int n_code = ;
unsigned int n_blank = ;
unsigned int n_comment = ;
char ch1, ch2;
bool in_code = false;
bool in_comment = false; while ((ch1 = getc(fp)) != EOF) {
if (ch1 != ' ' && ch1 != '\t' && ch1 != '\n' && ch1 != '{' && ch1 != '}' && !in_comment && !in_code) {
if (ch1 == '/') {
// Multi-line comment
if ((ch2 = getc(fp)) == '*') {
n_comment = in_multicomment(fp, n_comment);
} else if (ch2 == '/') {
in_comment = true;
n_comment++;
} else {
in_code = true;
n_code++;
}
} else {
in_code = true;
n_code++;
}
// Reset the state and count blank lines for each line
} else if ('\n' == ch1) {
if (in_code) {
in_code = false;
} else if (in_comment) {
in_comment = false;
} else
n_blank++;
}
} printf("Blank lines: %d\n", n_blank);
printf("Code lines: %d\n", n_code);
printf("Comment lines: %d\n", n_comment);
}
根据遇到的字符设置状态,/*则为多行注释,//为单行注释,其余非空行为代码行
每处理完一行则重置状态并统计空行
/* Get current work directory and traverse recursively the directory */
int recurrence(int argc, char *argv[], char *file_name)
{
char *buffer; if ((buffer = _getcwd(NULL, )) == NULL) {
perror("_getcwd error");
free(buffer);
exit(-);
} file_travesal(buffer, argc, argv, file_name);
free(buffer); return ;
} int file_travesal(const char *dir, int argc, char *argv[], char *file_name)
{
struct _finddata_t fa;
long handle;
char new_dir[MAX_PATH];
strcpy(new_dir, dir);
strcat(new_dir, "\\*.*"); if ((handle = _findfirst(new_dir, &fa)) == -1L) {
printf("Failed to find first file!\n");
return -;
} do {
// Determine if it is a subdirectory
if (fa.attrib & _A_SUBDIR) {
if ((strcmp(fa.name, ".") != ) && (strcmp(fa.name, "..") != )) {
strcpy(new_dir, dir);
strcat(new_dir, "\\");
strcat(new_dir, fa.name);
file_travesal(new_dir, argc, argv, file_name);
}
} else {
// Skip it when not match
if (!wildchar_match(fa.name, file_name, )) {
continue;
}
strcpy(new_dir, dir);
strcat(new_dir, "\\");
strcat(new_dir, fa.name);
printf("%s:\n", fa.name);
option(argc, (argv + ), new_dir);
printf("\n");
}
} while (_findnext(handle, &fa) == );
return ;
}
获取程序当前工作目录,并递归遍历整个目录文件,若文件名与用户输入的模式匹配,则执行选项操作
int option(int argc, char *argv[], char *file_name)
{
int c = ;
FILE *fp; if ((fp = fopen(file_name, "r")) == NULL) {
printf("Error! There has been a problem opening or reading from the file.\n");
exit(-);
} if (argc == ) {
printf("The number of characters: %d\n", char_count(fp));
rewind(fp);
printf("The number of words: %d\n", word_count(fp));
rewind(fp);
printf("The number of lines: %d\n", line_count(fp));
} // Get the arguments and execute the relevant operation
while (--argc > && (*++argv)[] == '-') {
while (c = *++argv[]) {
switch (c) {
case 'c':
printf("The number of characters in the file is %d\n", char_count(fp));
rewind(fp);
break;
case 'w':
printf("The number of words in the file is %d\n", word_count(fp));
rewind(fp);
break;
case 'l':
printf("The number of lines in the file is %d\n", line_count(fp));
rewind(fp);
break;
case 'a':
code_count(fp);
rewind(fp);
break;
default:
printf("Illegal option -%c\n", c);
break;
}
} // recover argv for next use.
--argv[];
--argv[];
} fclose(fp);
return ;
}
遍历所有参数,若参数的第一个字符为‘-’,则把其第二个字符赋值给c,并用switch结构进行选项操作。
为实现多选项执行,每完成一个选项将文件指针指回头部。
46-47行恢复参数,防止指针指向的内容发生变化并对文件遍历造成影响。
6、测试运行
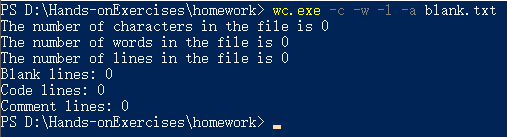
2、只有一个字符的文件
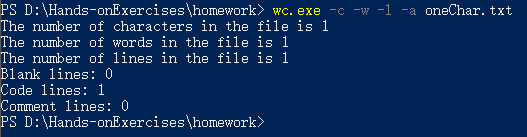
3、只有一个词的文件
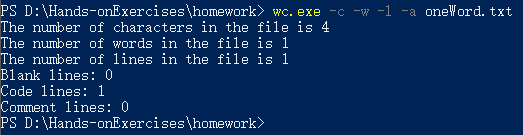
4、只有一行的文件
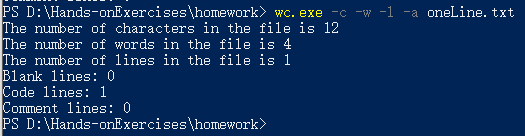
5、一个典型的源文件
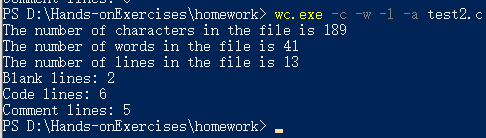
6、扩展功能

7、实际花费时间(见开头表格)
8、项目小结
- 在这个项目中,首先是对编程基本功的巩固,这次实践能使我更熟练地应用编程语言开发功能。
- 更深刻地体会到模块化设计开发的好处,虽然自己仍有待提高,但在开发过程中采用这种方式可以大大减少高耦合出现的情况。
- 了解并学习了目录文件的处理,查阅资料的过程中学习到了很多新的知识。
- PSP表格有助于开发者正确地认识自己,此次开发我耗时过长,藉此发现了自己的许多不足之处,比如对于不熟悉的领域一方面不敢大胆尝试,另一方面又颇有点闭门造车,耽误了大量时间和精力。
- 程序上,对于各种特殊情况的处理和测试仍不够完善,还需要多多努力。
软件工程实践-WC项目之C实现的更多相关文章
- 软件工程实践小项目之模拟wc.exe的小程序
github源码和工程文件地址:https://github.com/Jackchenyu/Word_counts/tree/smart 基本要求:要实现wc的基本功能即文件中字符数.单词数.行数的统 ...
- 软件工程wc项目,基于py
###WC项目文件链接:https://github.com/ILTHEW/wc.git 个人项目:WC 实践是理论的基础和验证标准,希望读者贯彻"做中学"的思想,动手实现下面的项 ...
- 软件工程第三个程序:“WC项目” —— 文件信息统计(Word Count ) 命令行程序
软件工程第三个程序:“WC项目” —— 文件信息统计(Word Count ) 命令行程序 格式:wc.exe [parameter][filename] 在[parameter]中,用户通过输入参数 ...
- 个人作业——软件工程实践总结&个人技术博客
一. 回望 (1)对比开篇博客你对课程目标和期待,"希望通过实践锻炼,增强软件工程专业的能力和就业竞争力",对比目前的所学所练所得,在哪些方面达到了你的期待和目标,哪些方面还存在哪 ...
- ASP.NET MVC5 网站开发实践(一) - 项目框架
前几天算是开题了,关于怎么做自己想了很多,但毕竟没做过项目既不知道这些想法有无必要,也不知道能不能实现,不过邓爷爷说过"摸着石头过河"吧.这段时间看了一些博主的文章收获很大,特别是 ...
- ASP.NET MVC5 网站开发实践(一) - 项目框架(转)
前几天算是开题了,关于怎么做自己想了很多,但毕竟没做过项目既不知道这些想法有无必要,也不知道能不能实现,不过邓爷爷说过“摸着石头过河”吧.这段时间看了一些博主的文章收获很大,特别是@kencery,依 ...
- 关于Axure RP软件的介绍——软件工程实践第二次个人作业
关于Axure RP软件的介绍——软件工程实践第二次个人作业 Axure RP是一个非常专业的快速原型设计的一个工具,客户提出需求,然后根据需求定义和规格.设计功能和界面的专家能够快速创建应用软件或W ...
- 福州大学软件工程1816 | W班 第10次作业[软件工程实践总结]
作业链接 个人作业--软件工程实践总结 评分细则 本次由五个问题(每个十分)+创意照片(五分)+附加题(十分)组成 评分统计图 千帆竞发图 汇总成绩排名链接 汇总链接
- 为实践javaweb项目,搭建了相应环境
为实践javaweb项目,搭建了相应环境,现总结一下. JDK与JRE的安装与配置 前提准备: 1.我们下载的JDK安装包里面既包含JDK又包含JRE: 2.要确认你的电脑里面没有JDK和JRE的残留 ...
随机推荐
- Java并发——CAS
什么是CAS? CAS是Compare And Swap的简称.在Java中有很多实现,比如compareAndSwapObject()方法,或者compareAndSwapInt()方法等.多用在包 ...
- 【MQ】消息队列及常见MQ比较
一.什么是消息队列 我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用.消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰. ...
- transition-timing-function 属性
以相同的速度从开始到结束的过渡效果: div { transition-timing-function: linear; -moz-transition-timing-function: linear ...
- .NET下的使用ActiveMQ
项目结构 ActiveMQRecive下Program.cs using Apache.NMS; using Apache.NMS.ActiveMQ; using Apache.NMS.Util; u ...
- 在Docker中体验数据库之Microsoft SQL Server
前面记录了一下在docker中体验mongodb和mysql.今天记录一下mssql……其实早就体验了,就是没有记录,前几天看了一下2019的一些新闻,很喜欢Polybase这个特性,想体验一把,可惜 ...
- Java枚举储存的一种索引实现方式
首先引入guava包(一个进行代码校验的工具类): <dependency> <groupId>com.google.guava</groupId> <art ...
- ASP.NET Core 共享第三方依赖库部署的Bug(*.deps.json on 2.2.0 or 4.6.0 版本)
背景: I try to put the Microsoft.*.dll and System.*.dll togather to a new folder.以便把(第三方或)系统的和应用的dll分开 ...
- Java使用Try with resources自动关闭资源
Try-with-resources Try-with-resources是Java7中一个新的异常处理机制,它能够很容易地关闭在try-catch语句块中使用的资源. 利用Try-Catch-Fin ...
- Linux常用命令速查-用户管理
◆ 用户组 ◆ 查看当前用户所属的用户组 1 groups 查看所有用户组 123456789 [root@node2 ~]# cat /etc/group root:x:0:bin:x:1:daem ...
- ASP.NET MVC默认配置如有跳转到指定的Area区域中的对应程序中
今天在搭建一个基于MVC的项目,因为项目涉及到了手机和pc端,为了方便和减少二者之间的耦合我在区域(Areas)中建立了两个 程序空间,那么问题来了我想让程序默认跳转到我所指定的areas中的对应项目 ...