CUDA编程模型之内存管理
CUDA编程模型假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存。

主机:CPU及其内存(主机内存),主机内存中的变量名以h_为前缀,主机代码按照ANSI C标准进行编写
设备:GPU及其内存(设备内存),设备内存中的变量名以d_为前缀,设备代码使用CUDA C标准进行编写
一个典型的CUDA程序实现流程:
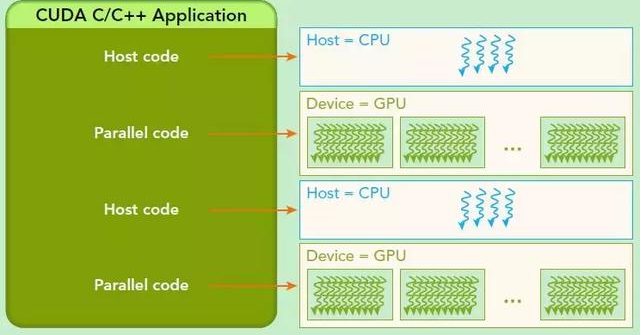
1.把数据从CPU内存拷贝到GPU内存
- 在CPU上申请内存:float *h_A;
h_A=(float*)malloc(nBytes);
- 在GPU上申请内存:float *d_A;
cudaMalloc((float**)&d_A,nBytes);
- 数据传输:cudaMemcpy(d_A,h_A,nBytes,cudaMemcpyHostToDevice);
2.调用核函数对存储在GPU内存中的数据进行操作
3.将数据从GPU内存传送回到CPU内存
- 数据传输:cudaMemcpy(h_C,d_C,nBytes,cudaMemcpyDeviceToHost);
- 释放GPU内存:cudaFree(d_A);
- 释放CPU内存:free(h_A);
说明:
1.GPU内存分配:cudaMalloc函数
函数原型:cudaError_t cudaMalloc(void** devPtr, size_t size)
该函数负责向设备分配一定字节的线性内存,并以devPtr的形式返回指向所分配内存的指针。
2.主机和设备之间的数据传输:cudaMemcpy函数
函数原型:cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)
该函数以同步方式执行,从src指向的源存储区复制一定数量的字节到dst指向的目标存储区。复制方向由kind指定。
kind有四种选择:cudaMemcpyHostToHost、cudaMemcpyHostToDevice、cudaMemcpyDeviceToHost、cudaMemcpyDeviceToDevice
如果GPU内存分配成功,函数返回cudaSuccess;否则返回cudaErrorMemoryAllocation
可以使用CUDA运行时函数将错误代码转化为可读的错误信息:char* cudaGetErrorString(cudaError_t error)
3.释放GPU内存:cudaFree函数
函数原型:cudaError_t cudaFree(void* devPtr)
CUDA编程模型之内存管理的更多相关文章
- CUDA编程模型
1. 典型的CUDA编程包括五个步骤: 分配GPU内存 从CPU内存中拷贝数据到GPU内存中 调用CUDA内核函数来完成指定的任务 将数据从GPU内存中拷贝回CPU内存中 释放GPU内存 *2. 数据 ...
- CUDA刷新器:CUDA编程模型
CUDA刷新器:CUDA编程模型 CUDA Refresher: The CUDA Programming Model CUDA,CUDA刷新器,并行编程 这是CUDA更新系列的第四篇文章,它的目标是 ...
- Tensoflw.js - 02 - 模型与内存管理(易懂)
Tensoflw.js - 02 - 模型与内存管理(易懂) 参考 W3Cschool 文档:https://www.w3cschool.cn/tensorflowjs/ 本文主要翻译一些英文注释,添 ...
- CUDA学习笔记(一)——CUDA编程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm56.html CUDA的代码分成两部分,一部分在host(CPU)上运行,是普通的C代码:另一部分在d ...
- CUDA编程模型——组织并行线程3 (2D grid 1D block)
当使用一个包含一维块的二维网格时,每个线程都只关注一个数据元素并且网格的第二个维数等于ny,如下图所示: 这可以看作是含有二维块的二维网格的特殊情况,其中块儿的第二个维数是1.因此,从块儿和线程索引到 ...
- JAVA高级篇(二、JVM内存模型、内存管理之第二篇)
本文转自https://zhuanlan.zhihu.com/p/25713880. JVM的基础概念 JVM的中文名称叫Java虚拟机,它是由软件技术模拟出计算机运行的一个虚拟的计算机. JVM也充 ...
- JAVA高级篇(二、JVM内存模型、内存管理之第一篇)
JVM内存结构如 Java堆(Heap),是Java虚拟机所管理的内存中最大的一块.Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建.此内存区域的唯一目的就是存放对象实例,几乎所有的对象实 ...
- CUDA编程模型——组织并行线程2 (1D grid 1D block)
在”组织并行编程1“中,通过组织并行线程为”2D grid 2D block“对矩阵求和,在本文中通过组织为 1D grid 1D block进行矩阵求和.一维网格和一维线程块的结构如下图: 其中,n ...
- CUDA-F-2-0-CUDA编程模型概述1
Abstract: 本文介绍CUDA编程模型的简要结构,包括写一个简单的可执行的CUDA程序,一个正确的CUDA核函数,以及相应的调整设置内存,线程来正确的运行程序. Keywords: CUDA编程 ...
随机推荐
- FFMPEG结构体分析:AVCodecContext
注:写了一系列的结构体的分析的文章,在这里列一个列表: FFMPEG结构体分析:AVFrame FFMPEG结构体分析:AVFormatContext FFMPEG结构体分析:AVCodecConte ...
- Java 条形码生成(一维条形码)
utl:http://mianhuaman.iteye.com/blog/1013945 在这里给大家介绍一个java 生成条形码 jbarcode.jar 生成条形码 支持EAN13, EAN8, ...
- 销售订单-修改量-高级定价关联sql
修改量消耗明细 --修改量消耗明细 SELECT t.name, t.comments, t.version_no, cux_rebate_pub.get_hou_name(p_organizatio ...
- Leetcode_198_House Robber
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/47680663 You are a professional ...
- hadoop 数据倾斜
数据倾斜是指,map /reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有 ...
- Android网络请求框架之Retrofit实践
网络访问框架经过了从使用最原始的AsyncTask构建简单的网络访问框架(甚至不能称为框架),后来使用开源的android-async-http库,再到使用google发布的volley库,一直不懈的 ...
- Linux内核中断和异常分析(中)
在linux内核中,每一个能够发出中断请求的硬件设备控制器都有一条名为IRQ的输出线.所有现在存在的IRQ线都与一个名为可编程中断控制器的硬件电路的输入引脚相连,上次讲到单片机的时候,我就讲到了单片机 ...
- LeetCode之旅(21)-Swap Nodes in Pairs
题目: Given a linked list, swap every two adjacent nodes and return its head. For example, Given 1-> ...
- LeetCode(35)-Path Sum
题目: Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up ...
- JS (全局作用域)
一.全局函数作用域(把变量的声明和函数的声明放在前面) 作用域(scope):一条数据可以在哪个范围中使用. 通常来说,一段程序代码中所用到的数据并不总是有效/可用的,而限定这个数据的可用性的代码范围 ...