CUDA编程模型——组织并行线程2 (1D grid 1D block)
在”组织并行编程1“中,通过组织并行线程为”2D grid 2D block“对矩阵求和,在本文中通过组织为 1D grid 1D block进行矩阵求和。一维网格和一维线程块的结构如下图:
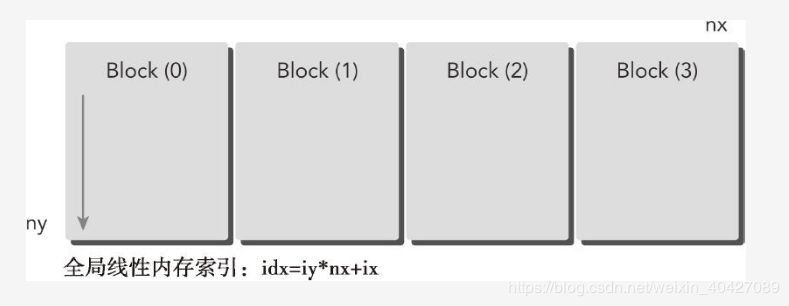
其中,nx是x方向上的最大线程数,ny是一个线程需要处理的数据元素的个数(因为块是一维的,照理应该没有ny)。所以这里这里只有ix是对线程的真正索引,iy是线程内部数据的索引(这个时候要把线程看成一个主线程,里面有ny个子线程组成的,每个子线程依次处理一个数据。但一定要记住,这个子线程实际上并不存在,是并行里面的串行)。这样每个数据的索引 idx 依然满足idx=iy*nx+ix;其中iy是从0迭代到ny的。
相应的核函数如下:(如果核函数和2Dgrid2Dblock一样,会怎样?)
__global__ void sumMatrixOnGPU1D(float *MatA,float *MatB,float *MatC,int nx,int ny)
{
unsigned int ix=threadIdx.x+blockIdx.x*blockDim.x;//获得x方向上的网格坐标
if(ix<nx)//防止越界
{
//从这里开始,就已经是线程里面的串行了
for(int iy=;iy<ny;i++)
{
int idx=iy*nx+ix;//得到计算矩阵的坐标idx
C[idx]=A[idx]+B[idx];
}
}
}
一维网格和块的线程配置:
dim3 block(,);
dim3 grid((block.x-)/block.x+,);
使用以下配置调用核函数:
sumMatrixOnGPU1D <<< grid, block >>>(d_MatA, d_MatB, dMatC, nx, ny);
设置矩阵数据量的大小为:
// set up data size of matrix
int nx = << ;
int ny = << ;
运行结果如下所示:(可以到一维网格一维线程块实际分配的线程数是:32*512=16384)

接着按照如下增加线程块的大小:
dim3 block(,);
dim3 grid((block.x-)/block.x+,);
运行结果如下:

可以看出核函数运行的更快了。
主要参考文献:
- 《 CUDA C编程权威指南 》
- https://blog.csdn.net/weixin_40427089/article/details/86696707
CUDA编程模型——组织并行线程2 (1D grid 1D block)的更多相关文章
- CUDA编程模型——组织并行线程3 (2D grid 1D block)
当使用一个包含一维块的二维网格时,每个线程都只关注一个数据元素并且网格的第二个维数等于ny,如下图所示: 这可以看作是含有二维块的二维网格的特殊情况,其中块儿的第二个维数是1.因此,从块儿和线程索引到 ...
- 【CUDA 基础】2.3 组织并行线程
title: [CUDA 基础]2.3 组织并行线程 categories: CUDA Freshman tags: Thread Block Grid toc: true date: 2018-03 ...
- CUDA编程模型
1. 典型的CUDA编程包括五个步骤: 分配GPU内存 从CPU内存中拷贝数据到GPU内存中 调用CUDA内核函数来完成指定的任务 将数据从GPU内存中拷贝回CPU内存中 释放GPU内存 *2. 数据 ...
- CUDA刷新器:CUDA编程模型
CUDA刷新器:CUDA编程模型 CUDA Refresher: The CUDA Programming Model CUDA,CUDA刷新器,并行编程 这是CUDA更新系列的第四篇文章,它的目标是 ...
- CUDA编程模型之内存管理
CUDA编程模型假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存. 主机:CPU及其内存(主机内存),主机内存中的变量名以h_为前缀,主机代码按照ANSI C标准进行编写 设备:GPU及其 ...
- CUDA学习笔记(一)——CUDA编程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm56.html CUDA的代码分成两部分,一部分在host(CPU)上运行,是普通的C代码:另一部分在d ...
- CUDA编程之快速入门
CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架构.做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要 ...
- CUDA编程之快速入门【转】
https://www.cnblogs.com/skyfsm/p/9673960.html CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架 ...
- cuda编程基础
转自: http://blog.csdn.net/augusdi/article/details/12529247 CUDA编程模型 CUDA编程模型将CPU作为主机,GPU作为协处理器(co-pro ...
随机推荐
- PHP之魔术方法
PHP中的魔术方法: PHP的魔术方法主要是在特定的条件下执行相应的魔术方法.这和很多框架中的钩子函数有些类似,不同的是,钩子函数是在生命周期的某个周期内自动执行,而魔术方法是在触发某种条件下自动 ...
- [Java Web学习]JDBC事务处理
1. Spring中加入数据库的bean <bean id="dataSource" class="org.apache.commons.dbcp.BasicDat ...
- SQL学习 存储过程&DUAL表
CREATE OR REPLACE PROCEDURE 存储过程 转自 https://www.cnblogs.com/lideng/p/3427822.html oracle中dual表的用途介绍 ...
- Unity RigidBodyFPSController 鼠标不显示
做第一人称浏览和顶视图浏览时遇到一个坑,就是当切换到第一人称时,操作UI界面的时候就gg,鼠标光标都看不见了. 如下图:LockCursor LockCursor 做了两个操作,第一个就是锁定光标位置 ...
- javascript window对象常用方法
方法名称 prompt():显示可提示用户输入的对话框 alert():显示带有一个提示信息和 一个确定按钮的警示框 confirm():显示一个 带有提示信息.确定和取消按钮的对话框 open(): ...
- 汇编实验2(又是作业emm)
实验任务:学会使用debug 1.使用Debug,将程序段写入内存: 首先对0021:0000~0021:000F的内存赋值 这里我赋的值是 11 12 13 14 15 16 17 18 输入mov ...
- CS萌新的汇编学习之路02 Learning of Assembly Language
第二节课 寄存器 1. 寄存器的定义: 进行信息储存的器件,是CPU中程序员可以读写的部件,通过改变各种寄存器中的内容来实现对CPU的控制 2. 寄存器的种类: 本节课学习通用寄存器和段寄存器 2. ...
- 两个队列实现栈&两个栈实现队列(JAVA)
1,两个栈实现队列 题目描述 用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. 思路:栈的特点时先进后出,队列的特点是先进先出. 若此时有两个队列stack1,st ...
- Evosuite使用方法入门
Evosuite使用方法入门 1.简要介绍 EvoSuite开源工具可以基于Eclipse进行测试用例的自动生成,生成的测试用例符合Junit标准(直接生成可进行Junit的java文件),满 ...
- MySQL Execution Plan--IN子查询包含超多值引发的查询异常1
======================================================================= SQL语句: SELECT wave_no, SUM(I ...