hbase概述和安装
前言
前几天刚学了Hadoop的安装,几乎把Hadoop的雷都踩了一个遍,虽然Hadoop的相关的配置文件以及原理还没有完全完成,但是现在先总结分享一下笔者因为需要所整理的一些关于Hbase的东西。
Hbase概述
什么是Hbase?
首先我们还是来看看Hbase在百度上面是怎么解释的:

Hbase概述
Hbase简单结构概述
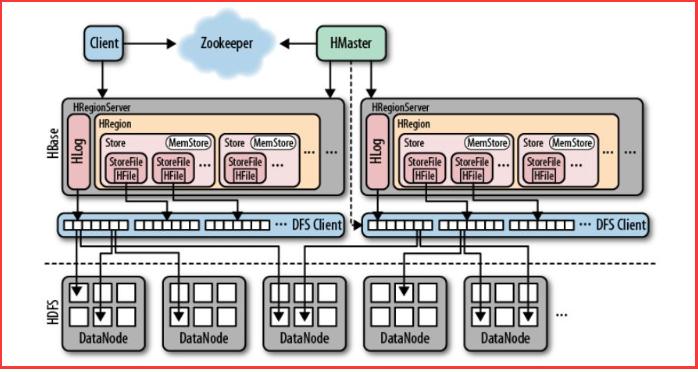
首先我们先来看一张图:
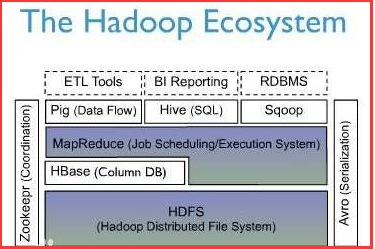
从上面的那张图中,我们可以发现:
HBase是一个构建在HDFS上的分布式列存储系统,并且hbase内部管理的文件都存储在hdfs中;
HBase是基于Google BigTable模型开发的,典型的key/value系统;
HBase是Apache Hadoop生态系统中的重要一员,主要用于海量结构化数据存储;
从逻辑上讲,HBase将数据按照表、行和列进行存储;
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
Hbase表特点
大:一个表可以有数十亿行,上百万列;
无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
面向列:面向列(族)的存储和权限控制,列(族)独立检索;
稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
数据类型单一:Hbase中的数据都是字符串,没有类型。
Hbase数据模型
Hbase的数据模型分为逻辑模型和物理模型:
1)逻辑模型
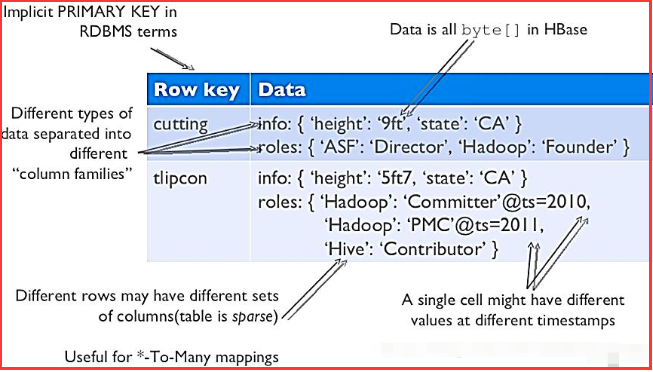
2)物理模型
每个column family存储在HDFS上的一个单独文件中,空值不会被保存。
Key 和 Version number在每个 column family中均有一份;
HBase 为每个值维护了多级索引,即:<key, column family, column name, timestamp>
物理存储:
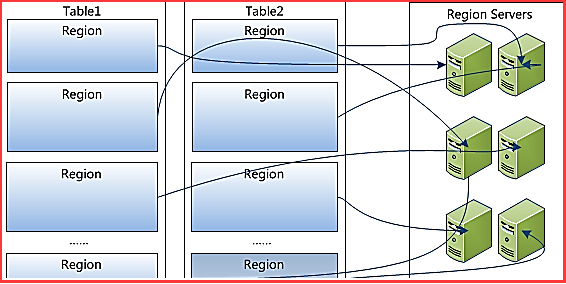
Table中所有行都按照row key的字典序排列;
Table在行的方向上分割为多个Region;
Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新region,之后会有越来越多的region;
Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上;
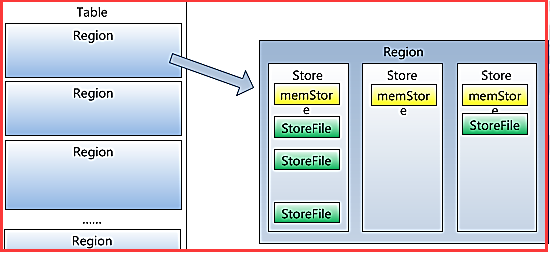
Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上。如下所示:
Hbase的架构介绍
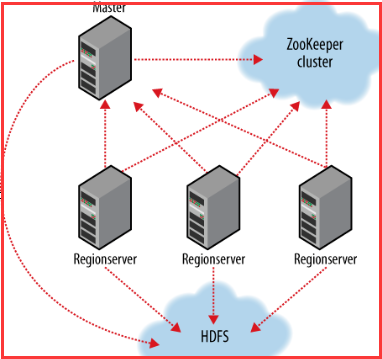
Client:
包含访问HBase的接口,并维护cache来加快对HBase的访问,比如region的位置信息。
Master:
为Region server分配region;
负责Region server的负载均衡;
发现失效的Region server并重新分配其上的region;
管理用户对table的增删改查操作。
Region Server:
Regionserver维护region,处理对这些region的IO请求;
Regionserver负责切分在运行过程中变得过大的region。
Zookeeper作用:
通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册;
存贮所有Region的寻址入口;
实时监控Region server的上线和下线信息。并实时通知给Master;
存储HBase的schema和table元数据;
默认情况下,HBase 管理ZooKeeper 实例,比如, 启动或者停止ZooKeeper;
Zookeeper的引入使得Master不再是单点故障。
Write-Ahead-Log(WAL):
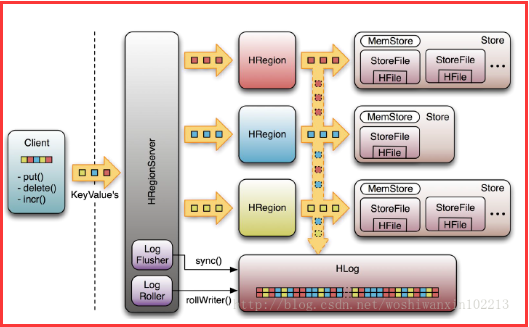
该机制用于数据的容错和恢复:
每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复
HBase容错性:
Master容错:Zookeeper重新选择一个新的Master
无Master过程中,数据读取仍照常进行;
无master过程中,region切分、负载均衡等无法进行;
RegionServer容错:定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer
Zookeeper容错:Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例
Region定位流程: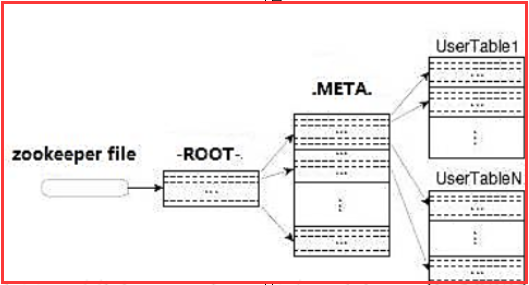
寻找RegionServer:
ZooKeeper--> -ROOT-(单Region)--> .META.--> 用户表
-ROOT-
表包含.META.表所在的region列表,该表只会有一个Region;
Zookeeper中记录了-ROOT-表的location。
-META-
表包含所有的用户空间region列表,以及RegionServer的服务器地址。
Hbase使用场景介绍
当需要很大数据量的存储以及数据高并发操作频繁的时候,或者需要对数据进行随机读写操作的时候,一般都会使用Hbase,但是关于Hbase的读写访问相对来说是非常简单的操作了。
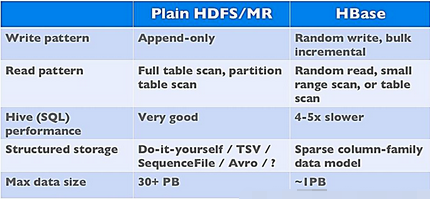
Hbase和Hdfs的区别
之前我们说到,Hbase是基于HDFS上的一个分布式存储系统,那么Hbase和Hdfs有什么区别呢?下面我们就简单介绍一下二者之间的区别。
两者都具有良好的容错性和扩展性,都可以扩展到成百上千个节点;
HDFS适合批处理场景;不支持数据随机查找;不适合增量数据处理;不支持数据更新。
参考文章:《Hbase原理、基本概念、基本架构》
Hbase的安装
介绍了Hbase相关的基本概念以及相关的基本架构,接下来笔者就要开始介绍Hbase的安装相关了。请注意,安装Hbase之前,请务必将Hadoop以及JDK在centos上面安装完成。
软件的下载
官网下载:
使用secureCRT将下载的压缩包上传到centOS
下载了hbase之后,我们就要使用secureCRT将我们从官网下载的压缩包上传到centOS中
解压
将上传上去的hbase使用tar命令解压到/usr/local目录下:
.tar.gz -C /usr/local #解压到/usr/local目录下,改名 ./hbase
解压好hbase之后,请记得到/etc/profile文件中设置hbase的环境变量。
配置hosts
到相关目录/etc/hosts看看是不是已经配置了hosts,按道理来说,弄Hadoop集群的时候,就应该完成这一个步骤了,配置如下:

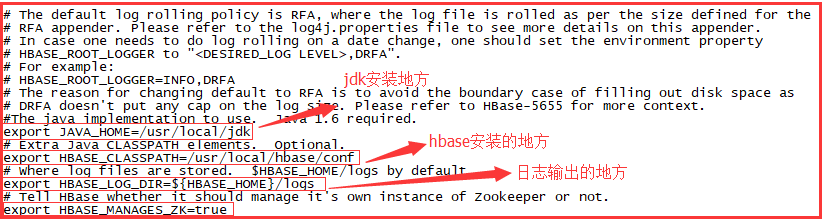
配置hbase-env.sh文件
到相关目录下/usr/local/hbase/conf下面配置hbase-env.sh:
配置regionservers

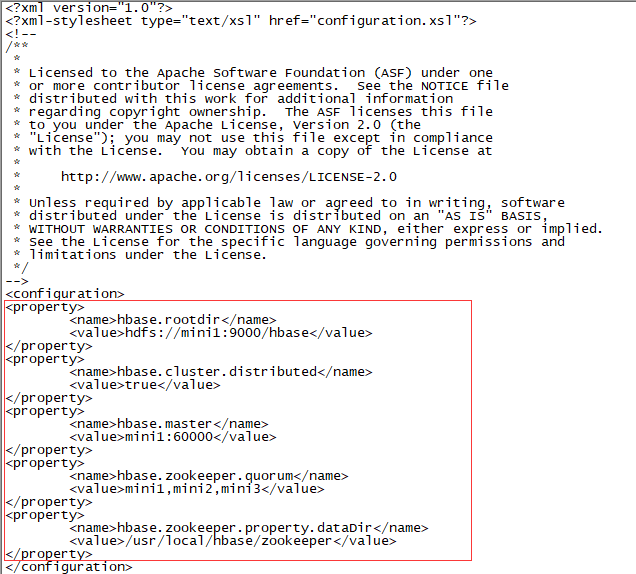
配置hbase-site.xml文件
(重要)将配置好的hbase使用scp命令传输到另外的regionservers上
到hbase安装的相关目录/usr/local下,使用scp命令传输到regionservers上面:
scp -r ./hbase mini2:/usr/local scp -r ./hbase mini3:/usr/local
启动hbase集群
在hadoop启动的前提下面启动hbase,可以使用jps命令查看进程,也可以到/usr/local/hadoop/bin目录下使用下面的命令:
[root@mini1 ~]# cd /usr/local/hadoop/bin [root@mini1 bin]# ls container-executor hadoop hadoop.cmd hdfs hdfs.cmd mapred mapred.cmd rcc test-container-executor yarn yarn.cmd [root@mini1 bin]# ./hdfs dfsadmin -report Configured Capacity: (33.97 GB) Present Capacity: (30.07 GB) DFS Remaining: (30.07 GB) DFS Used: ( KB) DFS Used%: 0.00% Under replicated blocks: Blocks with corrupt replicas: Missing blocks: ------------------------------------------------- Live datanodes (): Name: (mini2) Hostname: mini2 Decommission Status : Normal Configured Capacity: (16.99 GB) DFS Used: ( KB) Non DFS Used: (1.95 GB) DFS Remaining: (15.03 GB) DFS Used%: 0.00% DFS Remaining%: 88.50% Configured Cache Capacity: ( B) Cache Used: ( B) Cache Remaining: ( B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: Last contact: Fri Mar :: EST Name: (mini3) Hostname: mini3 Decommission Status : Normal Configured Capacity: (16.99 GB) DFS Used: ( KB) Non DFS Used: (1.95 GB) DFS Remaining: (15.03 GB) DFS Used%: 0.00% DFS Remaining%: 88.50% Configured Cache Capacity: ( B) Cache Used: ( B) Cache Remaining: ( B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: Last contact: Fri Mar :: EST
出现上面的live datanodes(2),说明我们已经将我们的hadoop启动成功了。
启动hbase集群
到相应的/usr/local/hbase/bin/目录下执行命令:
./start-hbase.sh
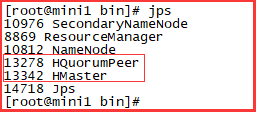
启动成功的标志
使用jps,可以发现进程如下:
主服务器:
mini2:
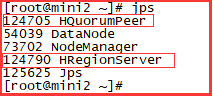
mini3:
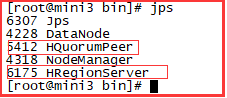
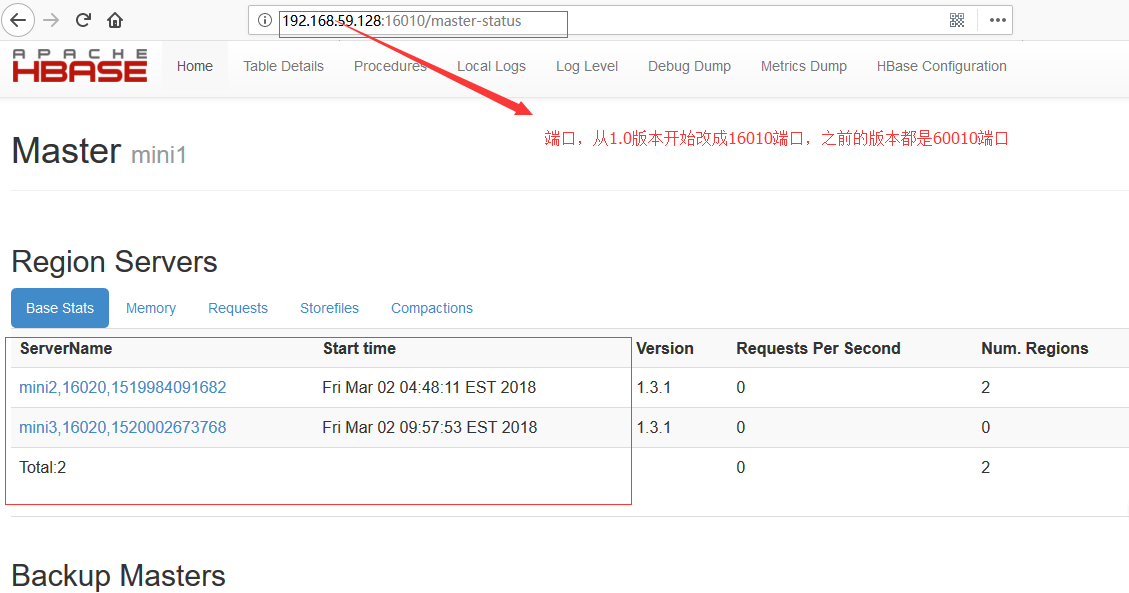
通过浏览器验证:
hbase shell简单命令的执行
进入数据库
在hbase的安装目录/usr/local/hbase/bin中执行命令:

查看数据库的状态

查看数据库版本

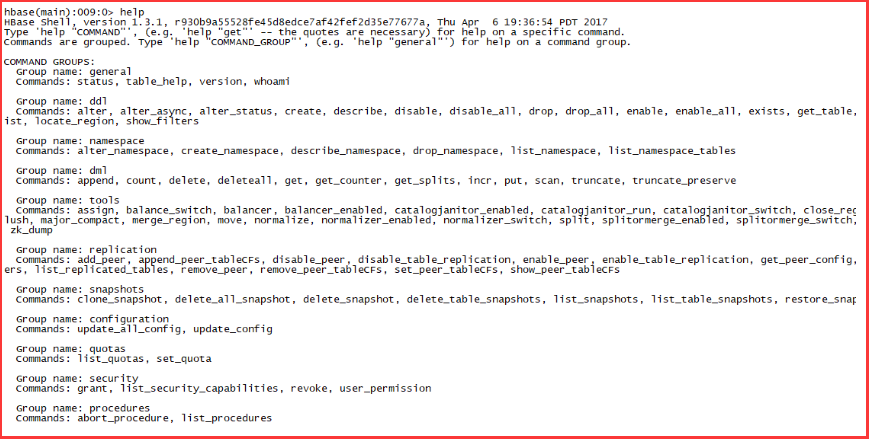
帮助命令
hbase概述和安装的更多相关文章
- HBase的概述和安装部署
一.HBase概述 1.HBase是Hadoop数据库,是一个分布式.可扩展的大数据存储. HBase是用于对大数据进行随机.实时读写访问的非关系型数据库,它的目标托管非常大的表——数十亿行N百万列. ...
- HBase伪分布式安装(HDFS)+ZooKeeper安装+HBase数据操作+HBase架构体系
HBase1.2.2伪分布式安装(HDFS)+ZooKeeper-3.4.8安装配置+HBase表和数据操作+HBase的架构体系+单例安装,记录了在Ubuntu下对HBase1.2.2的实践操作,H ...
- OpenVAS漏洞扫描基础教程之OpenVAS概述及安装及配置OpenVAS服务
OpenVAS漏洞扫描基础教程之OpenVAS概述及安装及配置OpenVAS服务 1. OpenVAS基础知识 OpenVAS(Open Vulnerability Assessment Sys ...
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- hbase伪分布式安装(单节点安装)
hbase伪分布式安装(单节点安装) http://hbase.apache.org/book.html#quickstart 1. 前提配置好java,环境java变量 上传jdk ...
- hbase完全分布式安装
hbase完全分布式安装 http://hbase.apache.org/book.html#standalone_dist master ...
- C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节
C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节 1.Qt概述 1.1 什么是Qt Qt是一个跨平台的C++图形用户界面应用程序框架.它为应用程序开发者提供建立艺术级图形界面 ...
- hbase单机版安装+phoneix SQL on hbase 单节点安装
hbase 单机安装部署及phoneix 单机安装 Hbase 下载 (需先配置jdk) https://www.apache.org/dyn/closer.lua/hbase/2.0.1/hbase ...
随机推荐
- python,验证码生成
<pre>import string import random from PIL import Image from PIL import ImageDraw from PIL impo ...
- MFC程序打包方法
目录 1. 新建工程 2. 设置信息 3. 其他设置 4. 生成安装包 1. 新建工程 在同一个解决方案下,新建一个Setup工程,工程名为SetupVSR. (1)在"解决方案资源管理器& ...
- 2018-2019-2 20175202实验二《Java面向对象程序设计》实验报告
2018-2019-2 20175202实验二<Java面向对象程序设计>实验报告 一.实验内容 1. 初步掌握单元测试和TDD 2. 理解并掌握面向对象三要素:封装.继承.多态 3. 初 ...
- python selenium TouchAction模拟移动端触摸操作(十八)
最近做移动端H5页面的自动化测试时候,需要模拟一些上拉,下滑的操作,最初考虑使用使用selenium ActionChains来模拟操作,但是ActionChains 只是针对PC端程序鼠标模拟的一系 ...
- [转]CPU-bound(计算密集型) 和I/O bound(I/O密集型)
转自:http://blog.csdn.net/q_l_s/article/details/51538039 I/O密集型 (CPU-bound) I/O bound 指的是系统的CPU效能相对硬盘/ ...
- python安装media报错
Try https://pypi.python.org/pypi/setuptools easy_install LEE 我后来,依次在Python2.7中装了 numpy-1.7.0-win32-s ...
- nginx配置备份
server { listen 80; server_name localhost; set $expires_duration "30d"; if ($uri ~* \.html ...
- promise 基础知识
promise 基础知识 proise:1.Promise是异步编程的一种解决方案,它有三种状态,分别是pending-进行中.resolved-已完成.rejected-已失败2.创建实例//met ...
- php.ini文件下载
该php.ini文件为修改版,完美运行,存于360云盘.
- Realm 处理List<String> 问题 Type parameter 'java.lang.String' is not within its bound; should implement 'io.realm.RealmModel
public class InitAppBean extends RealmObject { private String sapling; private String logistics; pri ...