iris数据集(鸢尾花)
包含三个花的品种(Iris setosa(山鸢尾),Iris virginica(北美鸢尾),Iris versicolor(变色鸢尾))
每个品种各50个样
每个样本四个特征参数(萼片长度和宽度、花瓣长度和宽度)
scikit-learn自带一些经典的数据集,如iris,digits,boston house prices,可以直接导入
导入数据方式:
from sklearn import datasets
iris=datasets.load_iris()
导入的数据是一种字典形式,特征存储在iris.data中,标签存储在iris.target中
如利用该数据集画出散点图
程序如下:
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np iris=datasets.load_iris()
irisFeature=iris.data
irisTarget=iris.target for i in range(len(irisTarget)):
if irisTarget[i]==0:
plt.scatter(irisFeature[i,0], irisFeature[i,1],c="r",marker="v")
elif irisTarget[i]==1:
plt.scatter(irisFeature[i,0], irisFeature[i,1], c="g",marker="")
else:
plt.scatter(irisFeature[i,0], irisFeature[i,1], c="b",marker="o")
plt.title("iris")
plt.xlabel("ewidth")
plt.ylabel("elength")
plt.show()
运行效果:
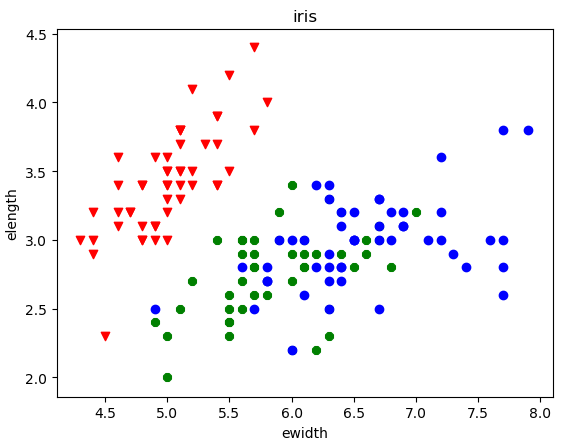
横轴表示萼片宽度,纵轴为萼片长度,倒三角为山鸢尾,绿色圆为北美鸢尾,蓝色圆为变色鸢尾。
iris数据集(鸢尾花)的更多相关文章
- iris数据集
iris以鸢尾花的特征作为数据来源,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性,是在数据挖掘.数据分类中非常常用的测试集.训练集. 链接地址
- Iris数据集实战
本次主要围绕Iris数据集进行一个简单的数据分析, 另外在数据的可视化部分进行了重点介绍. 环境 win8, python3.7, jupyter notebook 目录 1. 项目背景 2. 数据概 ...
- 机器学习笔记2 – sklearn之iris数据集
前言 本篇我会使用scikit-learn这个开源机器学习库来对iris数据集进行分类练习. 我将分别使用两种不同的scikit-learn内置算法--Decision Tree(决策树)和kNN(邻 ...
- 用Python实现支持向量机并处理Iris数据集
SVM全称是Support Vector Machine,即支持向量机,是一种监督式学习算法.它主要应用于分类问题,通过改进代码也可以用作回归.所谓支持向量就是距离分隔面最近的向量.支持向量机就是要确 ...
- iris数据集(.csv .txt)免费下载
我看CSDN下载的iris数据集都需要币,我愿意免费共享,希望下载后的朋友们给我留个言 分享iris数据集(供学习使用): 链接: https://pan.baidu.com/s/1Knsp7zn-C ...
- 从Iris数据集开始---机器学习入门
代码多来自<Introduction to Machine Learning with Python>. 该文集主要是自己的一个阅读笔记以及一些小思考,小总结. 前言 在开始进行模型训练之 ...
- 85、使用TFLearn实现iris数据集的分类
''' Created on 2017年5月21日 @author: weizhen ''' #Tensorflow的另外一个高层封装TFLearn(集成在tf.contrib.learn里)对训练T ...
- R语言实现分层抽样(Stratified Sampling)以iris数据集为例
R语言实现分层抽样(Stratified Sampling)以iris数据集为例 1.观察数据集 head(iris) Sampling)以iris数据集为例"> 选取数据集中前6个 ...
- iris数据集预测
iris数据集预测(对比随机森林和逻辑回归算法) 随机森林 library(randomForest) #挑选响应变量 index <- subset(iris,Species != " ...
- BP神经网络算法程序实现鸢尾花(iris)数据集分类
作者有话说 最近学习了一下BP神经网络,写篇随笔记录一下得到的一些结果和代码,该随笔会比较简略,对一些简单的细节不加以说明. 目录 BP算法简要推导 应用实例 PYTHON代码 BP算法简要推导 该部 ...
随机推荐
- 5款 Mac 常用PDF阅读和编辑软件推荐
PDF和Word.TXT等文档一样,都是我们最常用的文档格式,那么一款好用的浏览或编辑PDF的工具就很有必要了,今天和大家分享5款Mac上优秀的PDF阅读和编辑工具. 以下内容来自[风云社区 SCOE ...
- 保存指定目录及其子目录的jpg文件
import os txt_path = 't1.txt' f = open(txt_path, mode='a', encoding='utf-8') def all_path(dirname): ...
- flask模版继承和block
模版继承和block的目的就是为了减少前端代码量 flask_ones.py #encoding:utf-8 from flask import Flask,url_for,redirect,rend ...
- db mysql / mysql cluster 5.7.19 / performance
s 问题1: 数据库底层若表碎片化严重,导致表索引走向偏差,致使该表读写速度变慢,影响业务运行 解决1: 数据库表重组 end
- Spring Boot笔记二:快速创建以及yml文件自动注入
上个笔记写了如何自己去创建Spring boot,以及如何去打jar包,其实,还是有些麻烦的,我们还自己新建了几个文件夹不是. Idea可以让我们快速的去创建Spring boot应用,来看 一.快速 ...
- 6、JPA-映射-单向一对多
一个用户对应多个订单 实体类 Customer package com.jpa.yingshe; import javax.persistence.*; import java.util.HashSe ...
- Redis之主从复制
定义:主机数据更新后根据配置策略,自动同步到备的Master/slave机制,Master以写为主,Slave以读为主. Tip:配从(从库)不配主(主库) 1.从库配置: slave of 主库IP ...
- Hadoop记录-hadoop和hbase监控有那些比较好的工具
New Relic hadoop jmx granfa falcon Ganglia,Nagios和Chukwa 自带监控软件 hadoop yarn 开启jmx监控 打开{hadoop_home} ...
- windows安装mysql示例
1. 下载mysql安装包,如: mysql-5.6.34-winx64.zip2. 解压安装包到指定目录,如:D盘,即:D:\mysql-5.6.34-winx643. 配置 cd D:\mysql ...
- 【转载】详解KMP算法
网址:https://www.cnblogs.com/yjiyjige/p/3263858.html