爬虫之抓取js生成的数据
有很多页面,当我们用request发送请求,返回的内容里面并没有页面上显示的数据,主要有两种情况,一是通过ajax异步发送请求,得到响应把数据放入页面中,对于这种情况,我们可以查看关于ajax的请求,然后分析ajax请求路径和响应,拿到想要的数据;另外一种就是js动态加载得到的数据,然后放入页面中。这两种情况下,对于用户利用浏览器访问时,都不会发现有什么异常,会迅速的得到完整页面。
其实我们之前学过一个selenium模块,通过操纵浏览器,然后拿到浏览器显示出来的数据,这种方式是可以拿到数据的,但本节是要分析如何找到那个js在控制数据的生成,及js发送请求的路径,从而我们可以向这个路径发送请求,直接就得到数据。
在之前的爬虫过程中,我最烦的就是关于js动态生成的数据,我根本无法找到是哪一个js实现的(因为js太多了),今天看了大佬的博客,瞬间感觉简单了很多,谢谢大佬,祭出大佬的博客:https://www.cnblogs.com/bobo-zhang/p/10561617.html
一、需求描述及页面分析
1,需求描述
基础页面路径:https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html
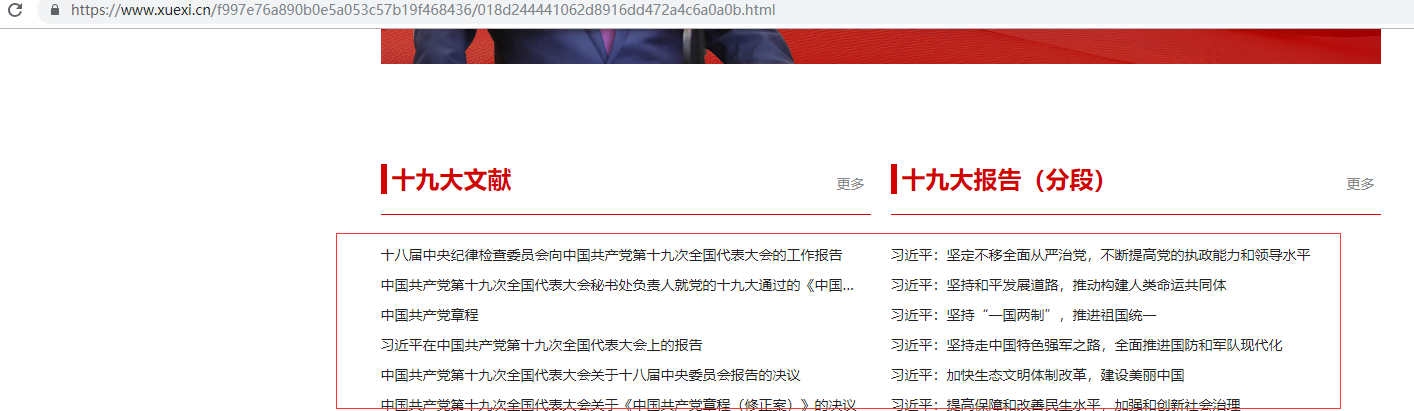
点击进入每个标题里面:
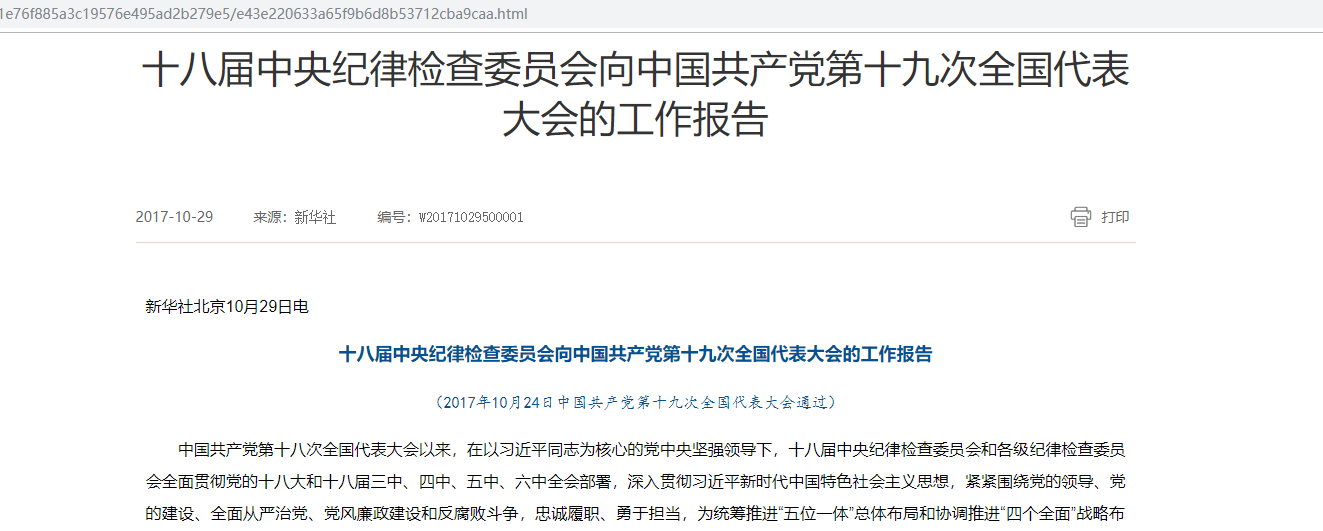
需求就是爬取每个标题下的新闻内容
2,页面分析
2.1 主页面
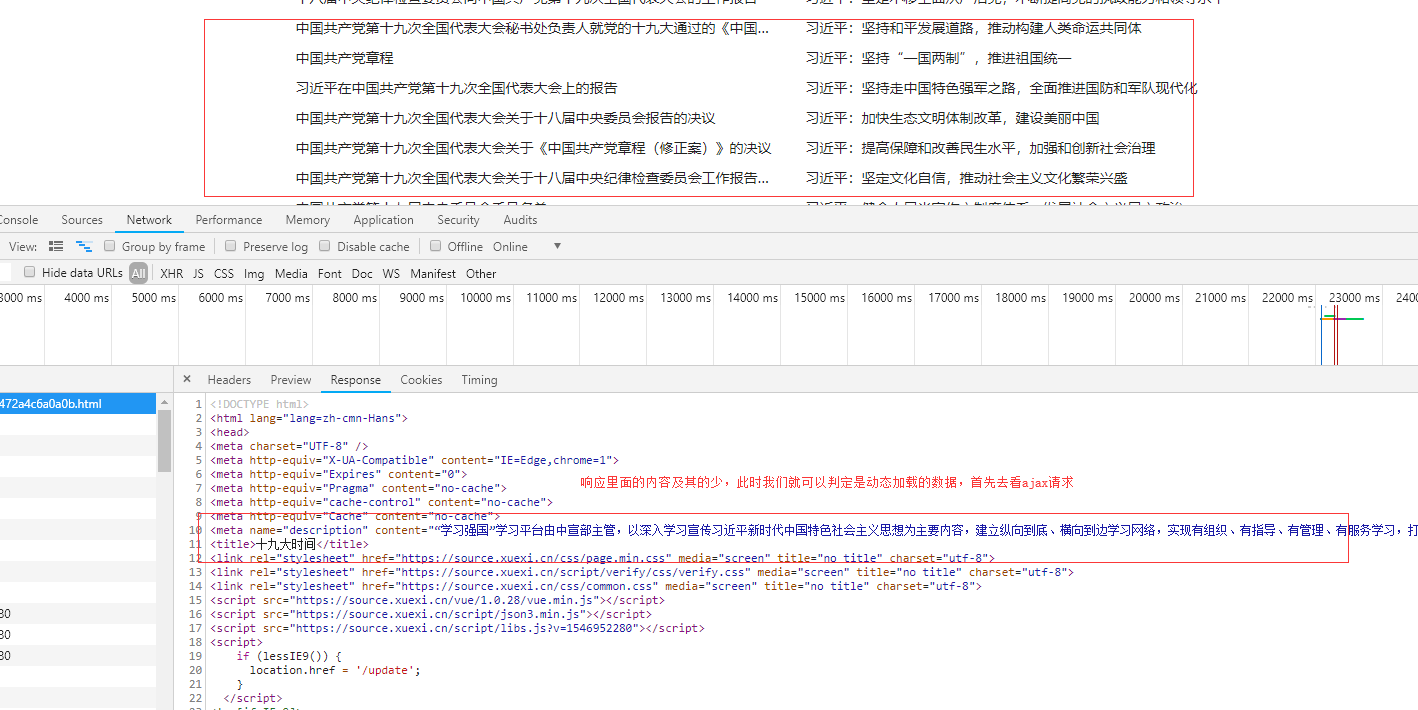
查看ajax请求:
接下来我们就解析如何找出发送请求的js
二、查找发送请求的js
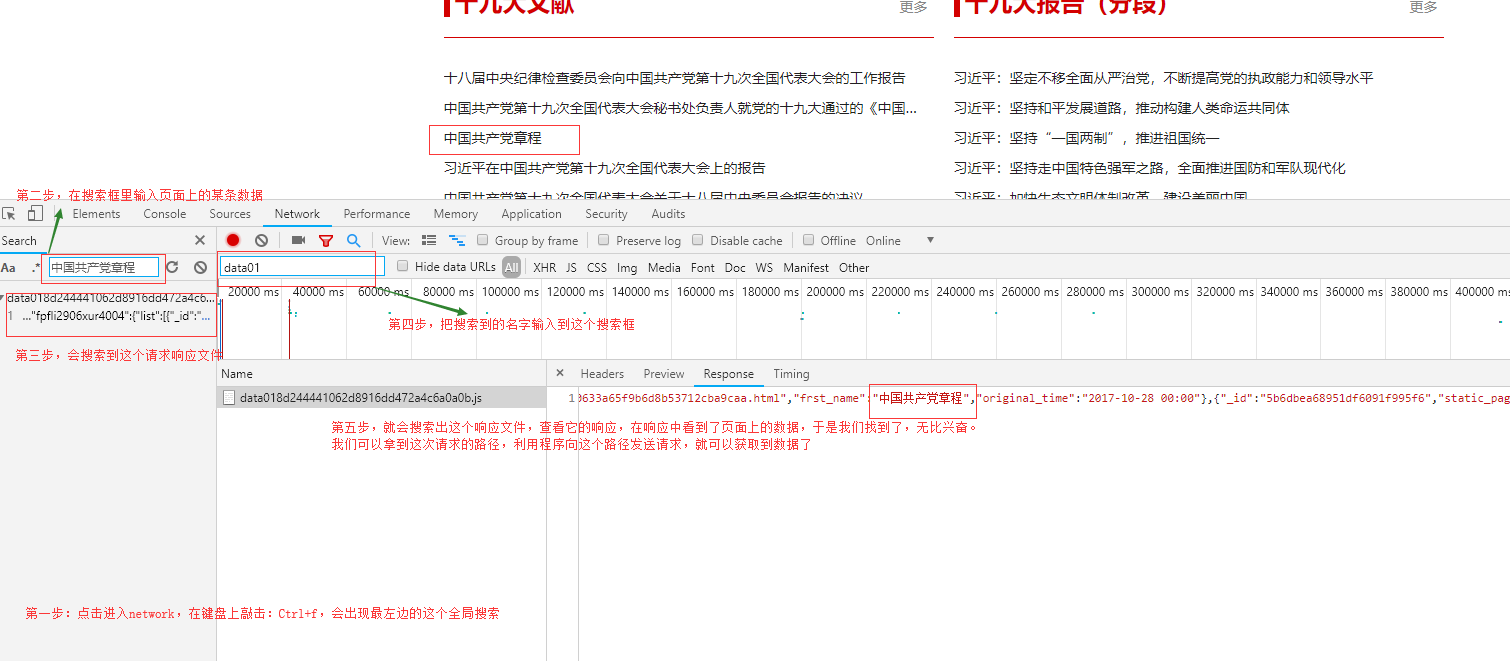
在响应的数据里,包含新闻标题,以及本条新闻的详情页路径,于是现在我们去访问详情页,以及分析详情页
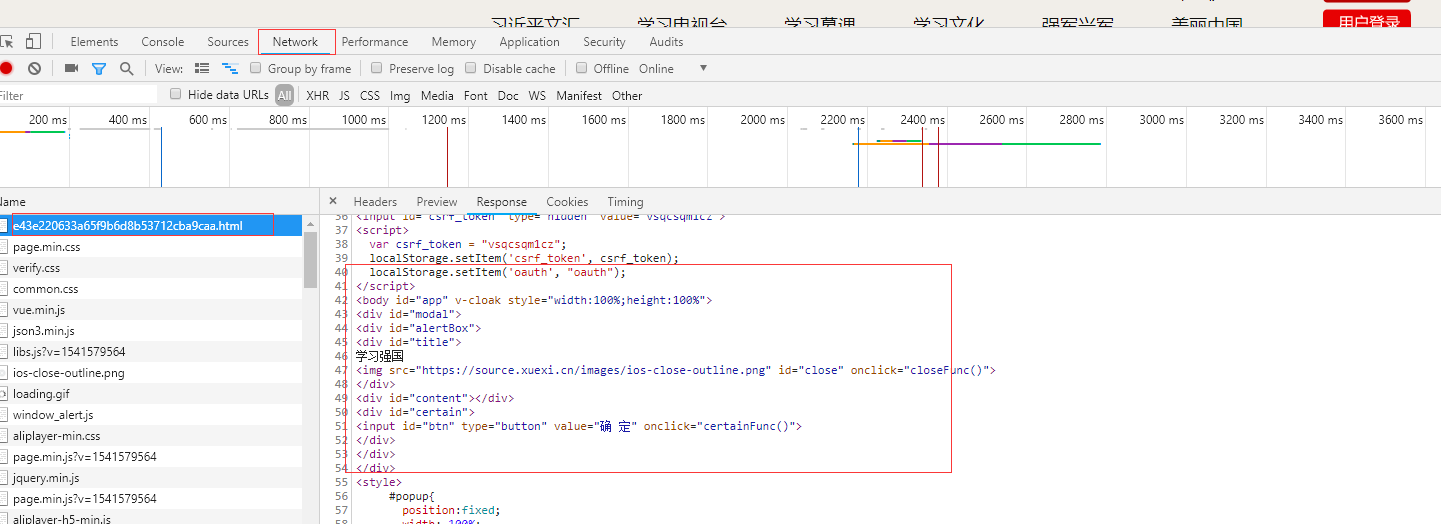
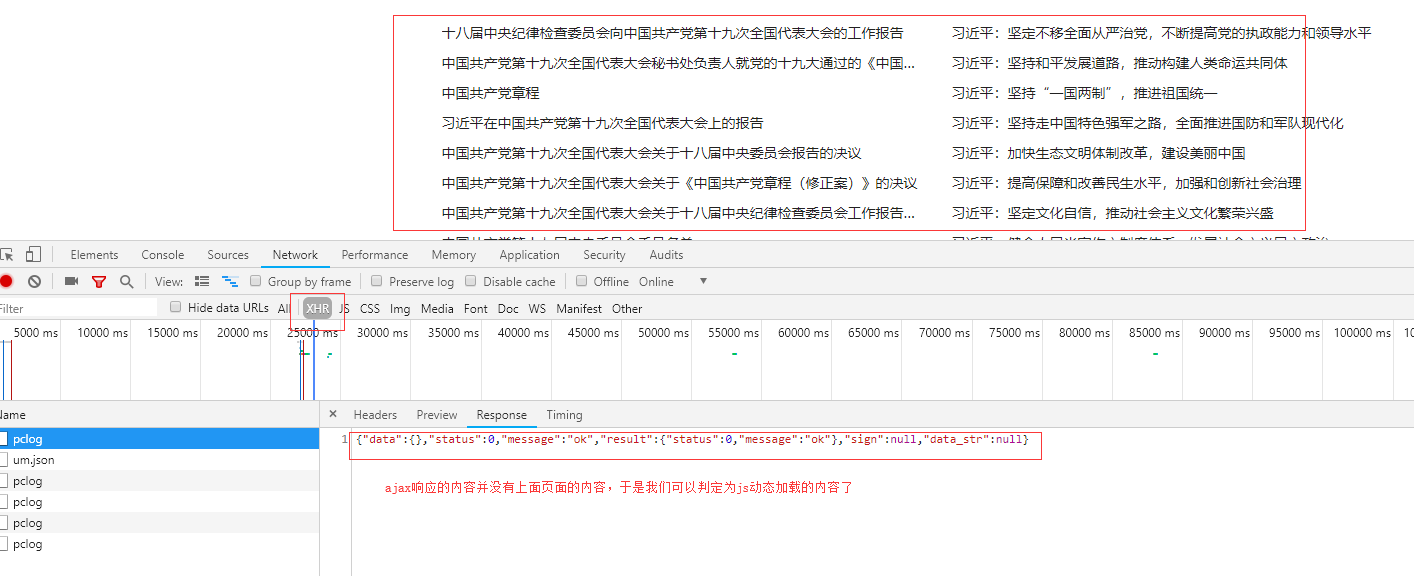
访问详情页,查看详情页的响应,数据里面也没包含具体数据,那它就和主页面一样,接下来去看ajax:
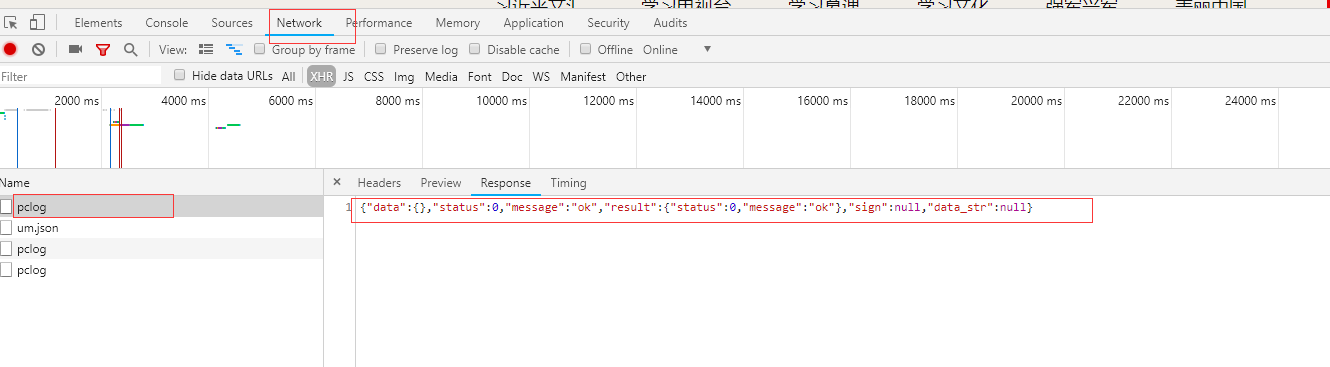
ajax并没有新闻相关数据,所以不是利用ajax请求拿到数据的,那只有剩下js了,我们就去寻找是哪个js发送的请求来获取数据,步骤上面一致:
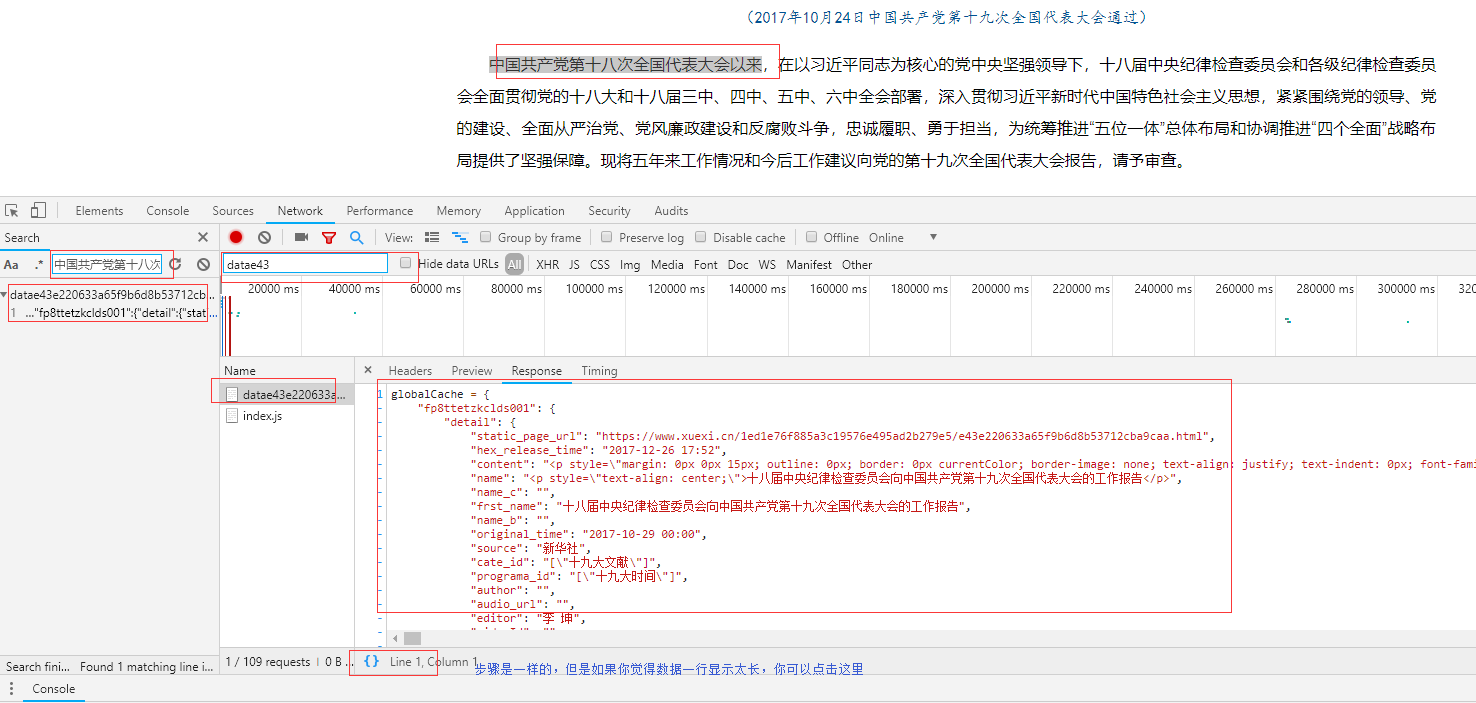
详情页数据的js请求路径:

详情页请求路径:

我们可以看到,详情页数据的请求路径在最后一个斜杠前面的路径和详情页的请求路径在最后一个斜杠前面都是一样的。于是我们可以这样:
第一步:拿到详情页的请求路径:
url1='https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html'
第二步:把url1最后一个斜杠后面的内容替换掉
url2='https://www.xuexi.cn/%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #把url1用‘/’分割,拿到第四部分,即索引为3,然后拼接进去既可
这样就构造好了一个详情页数据请求路径,然后直接去访问这个路径既可拿到数据,就不用去访问详情页了
爬虫之抓取js生成的数据的更多相关文章
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
- htmilunit-- 针对抓取js生成的数据
public static String getHtml(String html){ // 模拟一个浏览器 @SuppressWarnings("resou ...
- 【转】Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
- Python爬虫:抓取手机APP的数据
摘要 大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 表单: 表单中包括了用户名和密码,当然都是加密 ...
- 抓取Js动态生成数据且以滚动页面方式分页的网页
代码也可以从我的开源项目HtmlExtractor中获取. 当我们在进行数据抓取的时候,如果目标网站是以Js的方式动态生成数据且以滚动页面的方式进行分页,那么我们该如何抓取呢? 如类似今日头条这样的网 ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
随机推荐
- Day07 (黑客成长日记) 函数的参数及作用
定义函数: 1.定义函数注意: (1)位置参数:直接定义函数. def func(a,b): print(a,b) func(1,2) (2)默认参数:关键字参数:参数名= ‘默认的值‘ def fu ...
- 摘录<小王子>——[法]安东·圣埃克苏佩里
四 大人们都喜欢数字.你要是向他们说起一个新朋友,他们提出的问题从来问不到点子上. 他们绝不会问:"他的嗓音怎么样?他喜欢什么游戏?比如,他喜欢搜集蝴蝶标本吗?" 他们总是问你:& ...
- 【转】RPC介绍
转自:http://www.cnblogs.com/Vincentlu/p/4185299.html 摘要: RPC——Remote Procedure Call Protocol,这是广义上的解释, ...
- ELK从5.6.3升级到6.3.0总结
ELK从5.6.3升级到6.3.0总结 由于6.3.0默认有es的监控功能,并且我们现在es总是有各种问题,原有的es开源插件head和HQ的监控都不够详细,所以决定升级es集群.我们目前es有5个n ...
- @Slf4j注解实现日志输出
自己写日志的时候,肯定需要: private final Logger logger = LoggerFactory.getLogger(LoggerTest.class); 每次写新的类,就需要重新 ...
- 搭建node js的运行环境。
第一步:首先安装一个NVM,就是一个node的版本管理器. nvm的下载地址::https://github.com/coreybutler/nvm-windows/releases,我选择下载的是n ...
- Linux基础操作命令
一.系统信息 arch 显示机器的处理器架构(1) uname -m 显示机器的处理器架构(2) uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 – (SMBIO ...
- Java核心技术卷一基础知识-第5章-继承-读书笔记
第5章 继承 本章内容: * 类.超类和子类 * Object:所有类的超类 * 泛型数组列表 * 对象包装器和自动装箱 * 参数数量可变的方法 * 枚举类 * 反射 * 继承设计的技巧 利用继承,人 ...
- PHP之ThinkPHP框架(界面)
Thinkphp框架其精髓就在于实现了MVC思想,其中M为模板.V为视图.C为控制器,模板一般是公共使用类,在涉及数据库时,一般会跟数据表同名,视图会和控制器类里的方法进行名字的一一对应. 下载及配置 ...
- [EXP]windows全版本SMB溢出工具加强版
工具:k8加强版zzz 编译:python 漏洞:MS17-010 用法: zzz_exploit.exe 192.11.22.82zzz_exploit.exe 192.11.22.82 exe参数 ...