【C++ Primer | 10】泛型算法
#include<iostream>
#include<algorithm>
#include<vector>
#include<string>
#include<fstream>
using namespace std; void elimDups(vector<string> &words)
{
sort(words.begin(), words.end());
auto unique_end = unique(words.begin(), words.end());
words.erase(unique_end, words.end());
} void display(vector<string> &words)
{
for (auto c : words)
cout << c << " ";
cout << endl;
} int main()
{
ifstream in("test.txt");
if (!in)
{
cout << "打开文件失败" << endl;
exit();
} vector<string> words;
string str;
while (in >> str)
words.push_back(str);
elimDups(words);
display(words);
return ;
}

输出结果:

定制操作
示例代码:
#include<iostream>
#include<algorithm>
#include<vector>
#include<string>
#include<fstream>
using namespace std; void elimDups(vector<string> &words)
{
sort(words.begin(), words.end());
auto unique_end = unique(words.begin(), words.end());
words.erase(unique_end, words.end());
} void biggies(vector<string> &words, vector<string>::size_type sz)
{
elimDups(words); //将单词按字典排序,删除重复单词
stable_sort(words.begin(), words.end(), [](const string &a, const string &b) { return a.size() < b.size(); });
auto wc = find_if(words.begin(), words.end(), [sz](const string &a) { return a.size() >= sz; });
auto count = words.end() - wc;
for_each(wc, words.end(), [](const string &s) { cout << s << " "; });
cout << endl;
} int main()
{
ifstream in("test.txt");
if (!in)
{
cout << "打开文件失败" << endl;
exit();
} vector<string> words;
string str;
while (in >> str)
words.push_back(str);
auto sz = ;
biggies(words, sz);
return ;
}
输出结果:

再探迭代器
3. 反向迭代器
#include<iostream>
#include<vector>
#include<iterator>
using namespace std; int main()
{
vector<int> vec = { , , , , , , , , , };
for (auto r_iter = vec.crbegin(); r_iter != vec.crend(); ++r_iter)
cout << *r_iter << " ";
cout << endl;
return ;
}
输出结果:

#include <iostream>
#include <deque>
#include <algorithm>
#include <iterator>
using namespace std; void print(int elem)
{
cout << elem << ' ';
} int main()
{
deque<int> coll;
for (int i = ; i <= ; ++i)
coll.push_back(i); deque<int>::iterator pos1;
pos1 = find(coll.begin(), coll.end(), ); deque<int>::iterator pos2;
pos2 = find(coll.begin(), coll.end(), );
for_each(pos1, pos2, print);
cout << endl; deque<int>::reverse_iterator rpos1(pos1);
deque<int>::reverse_iterator rpos2(pos2);
for_each(rpos2, rpos1, print);
cout << endl;
return ;
}
输出结果:

【分析】
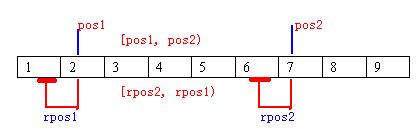
代码首先在一个deque中插入1到9,然后查找元素值为2和7的位置,分别赋值给迭代器pos1和pos2,然后输出,由于STL中的操作总是左开右闭的区间,即[2,7),所以输出2 3 4 5 6,7不会输出。
接下来将迭代器转换成逆向迭代器,再次输出,对于反向迭代器,由于是反向,所以按逻辑来说它是左开右闭的(这里我尝试了rpos2为iterator.end(),rpos1为iterator.begin(),此时输出全部),即(7,2](事实上还是左闭右开,只不过此时的左和iterator顺序一样)。所以输出6 5 4 3 2,下面的图片解释的很清楚。
【C++ Primer | 10】泛型算法的更多相关文章
- c++ primer 11 泛型算法
使用泛型算法必须包含头文件#inlucde <algorithm> 标准库还定义一组泛化的算术算法,其命名习惯与泛型算法相同,包含头文件#include <numeric> f ...
- C++ Primer 5th 第10章 泛型算法
练习10.1:头文件algorithm中定义了一个名为count的函数,它类似find,接受一对迭代器和一个值作为参数.count返回给定值在序列中出现的次数.编写程序,读取int序列存入vector ...
- [C++ Primer] : 第10章: 泛型算法
概述 泛型算法: 称它们为"算法", 是因为它们实现了一些经典算法的公共接口, 如搜索和排序; 称它们是"泛型的", 是因为它们可以用于不同类型的元素和多种容器 ...
- C++ Primer : 第十章 : 泛型算法 之 只读、写和排序算法
大多数算法都定义在<algorithm>头文件里,而标准库还在头文件<numeric>里定义了一组数值泛型算法,比如accumulate. ● find算法,算法接受一对迭代 ...
- 【足迹C++primer】30、概要(泛型算法)
概要(泛型算法) 大多数算法的头文件中定义algorithm在. 标准库也是第一个文件numeric它定义了一套通用算法. #include<iostream> #include<n ...
- C++ Primer笔记6_STL之泛型算法
1.泛型算法: 大多数算法定义在头文件algorithm中.标准库还在头文件numeric中定义了一组数值泛型算法 仅仅读算法: 举例: find函数用于找出容器中一个特定的值,有三个參数 int v ...
- 【c++ Prime 学习笔记】第10章 泛型算法
标准库未给容器添加大量功能,而是提供一组独立于容器的泛型算法 算法:它们实现了一些经典算法的公共接口 泛型:它们可用于不同类型的容器和不同类型的元素 利用这些算法可实现容器基本操作很难做到的事,例如查 ...
- C++ Primer 读书笔记:第11章 泛型算法
第11章 泛型算法 1.概述 泛型算法依赖于迭代器,而不是依赖容器,需要指定作用的区间,即[开始,结束),表示的区间,如上所示 此外还需要元素是可比的,如果元素本身是不可比的,那么可以自己定义比较函数 ...
- C++ Primer 学习笔记_45_STL实践与分析(19)--泛型算法的结构
STL实践与分析 --泛型算法的结构 引言: 正如全部的容器都建立在一致的设计模式上一样,算法也具有共同的设计基础. 算法最主要的性质是须要使用的迭代器种类.全部算法都指定了它的每一个迭代器形參可使用 ...
- C++ 泛型算法
<C++ Primer 4th>读书笔记 标准容器(the standard container)定义了很少的操作.标准库并没有为每种容器类型都定义实现这些操作的成员函数,而是定义了一组泛 ...
随机推荐
- vmware启动虚拟机发现没权限
前期安装未参与,但了解大致情况: 物理机上安装CentOS7系统,然后安装VMWare,虚拟了几台CentOS6 遇到的问题:物理机重启后,以root进入系统,但打开VMWare显示是普通用户权限,以 ...
- 虚拟机CentOS7下NAT模式的网络配置
NAT模式 就是让Guest OS借助NAT(网络地址交换)功能,通过Host OS所在的网络来访问公网.也就是说,使用NAT模式可以实现Guest OS轻松访问互联网,可以访问宿主计算机所在网络的其 ...
- dubbo源码分析1——SPI机制的概要介绍
插件机制是Dubbo用于可插拔地扩展底层的一些实现而定制的一套机制,比如dubbo底层的RPC协议.注册中心的注册方式等等.具体的实现方式是参照了JDK的SPI思想,由于JDK的SPI的机制比较简单, ...
- PEP525--异步生成器
[译] PEP 525--异步生成器 PEP原文:https://github.com/python/peps/blob/master/pep-0525.txt 创建日期:2016-07-18 译者 ...
- C++ 类中特殊的成员变量(常变量、引用、静态)的初始化方法
有些成员变量的数据类型比较特别,它们的初始化方式也和普通数据类型的成员变量有所不同.这些特殊的类型的成员变量包括: a.引用 b.常量 c.静态 d.静态常量(整型) e.静态常量(非整型) 常量和引 ...
- Html input 常见问题
1.input回车事件不执行导致页面刷新 场景:在文本框中输入关键字按回车,页面自动刷新了 <form name="keywordForm" method="pos ...
- 使用sudo而无需输入密码的设置
在linux上,root用户是老大,什么事都能做.但是,很多时候由于安全等各种原因,我们不希望把root用户开放给大家,但是又希望其他的用户可以有root的权限,所以就有了sudo用户.而执行sudo ...
- MySQL-mysql 8.0.12安装教程
1.下载zip安装包 去官网下载MySQL8.0 For Windows zip包,下载地址:https://dev.mysql.com/downloads/mysql/ 2.安装 解压zip包到安装 ...
- 007grafana监控时间戳转换
一. https://d.jyall.me/dashboard-solo/db/soloview?panelId=1&var-metrics=stats.gauges.zookeeper.mo ...
- virtual box 安装centos min
2018-4-19 22:20:40 星期四 之前不小心把用了很久的centos镜像删掉了.....这里记录下安装最小版centos的步骤 1. 安装centos 2. 开启网络, 并设置为随机启动 ...