KNN-笔记(1)
1 - 背景
KNN:k近邻,表示基于k个最近的邻居的一种机器学习方法。该方法原理简单,构造方便。且是一个非参数化模型。
KNN是一个“懒学习”方法,也就是其本身没有训练过程。只有在对测试集进行结果预测的时候才会产生计算。KNN在训练阶段,只是简单的将训练集放入内存而已。该模型可以看成是对当前的特征空间进行一个划分。当对测试集进行结果预测时,先找到与该测试样本最接近的K个训练集样本,然后基于当前是分类任务还是回归任务来做对应的处理。
KNN模型中有三个需要注意的地方:
1 - 距离度量的方法;
2 - K值的选择;
3 - 最后的判别决策规则。
如上面第三个,较为简单的判别决策规则为:
1)分类任务,那么找这K个训练集样本中出现次数最多的那个标签作为该测试样本标签,如下图:
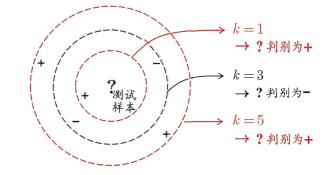
图1.1 周老师西瓜书图10.1
2)回归任务,基于这K个训练集样本求均值,将其作为该测试集样本的结果。
不过KNN正是因为基于K个近邻进行测量的方法,所以其出问题也就在这里,因为该模型不适合作为高特征维度下的选择。因为它会遇到维数灾难的问题。举个例子,假如当前数据集是均匀分布在一个D维特征的空间中的,假设我们需要计算测试样本\(x\)周边一个区域上的类别标签密度,那么我们期望基于足够大的区域范围的数据才能得到合理的结果,那么对应的边界长度公式为:
\]
也就是假如维度为\(D=10\),我们想评估10%的类别标签密度,那么每个维度上所需长度为\(e_{10}(0.1) = 0.8\),也就是我们需要每个维度上80%的长度范围内的数据,即使我们只需要估计1%的标签密度,我们每个维度上的长度也是\(e_{10}(0.01)=0.63\) 。
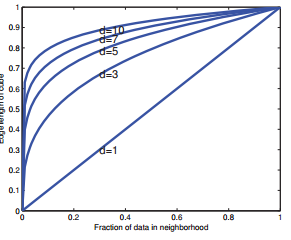
图2.2 mlapp上图1.16(b)
当维度为2,且样本能够无限多,那么该模型表现才是最好的(Cover and Hart 1967)。所以按道理,高维数据其实不适合KNN[]
不过幸运的是, 有一个效应可以在一定程度上抵消维度灾难, 那就是所谓的“ 非均匀性的祝福”(blessing of nonuniformity) 。
在大多数应用中, 样例在空间中并非均匀分布, 而是集中在一个低维流形manifold) 上面或附近。
这是因为数字图片的空间要远小于整个可能的空间。 学习器可以隐式地充分利用这个有效的更低维空间, 也可以显式地进行降维。[]
2 距离度量
KNN中最常用的方法就是欧式距离计算法,当然也有\(L_p\)距离和马氏距离等等。
假设样本的特征空间\(\chi\)是\(n\)维实数的向量空间\(\bf R^n\),\(x_i,x_j\in\chi\),$x_i=(x_i^{(1)}, x_i^{(2)}, ..., x_i^{(n)} ) \(,\)x_j=(x_j{(1)},x_j{(2)},...,x_j^{(n)})\(,那么\)x_i,x_j\(的\)L_p$距离定义为:
\]
这里\(p\geq1\),
当\(p=2\)时,称为欧式距离;
当\(p=1\)时,称为曼哈顿距离;
当\(p=\infty\)时,是各个坐标距离的最大值,即:
\]
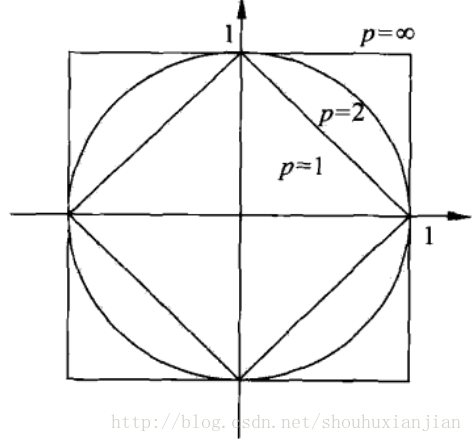
图2.1 李航统计学习方法图3.2
上图为在2维情况下到原点的距离为\(L_p=1\)的点构成的范围图
3 K值选取
K值的选择会对KNN模型的结果产生重大影响。这就是一个模型选择问题。
模型选择:假设当前是一个KNN回归问题。现在是需要对点\(x_0\)进行\(\hat f_k(x_0)\)拟合,假设该样本来自函数\(Y=f(X)+\epsilon\), 这里\(E(\epsilon)=0\), 且\(Var(\epsilon)=\sigma^2\)。为了简化问题,假设训练样本中\(x_i\)的值是固定的,那么在测试样本点\(x_0\)的期望预测误差也叫做测试或泛化误差,如:
EPE_k^{(x_0)}
&=& E[(Y-\hat f_k(x_0))^2|X=x_0]\\
&=& \sigma^2+[Bias^2(\hat f_k(x_0))+Var(\hat f_k(x_0))]\\
&=& \sigma^2+[f(x_0)-\frac{1}{k}\sum_{l=1}^kf(x(l))]^2+\frac{\sigma^2}{k}
\end{eqnarray}\]
第一项叫做不可避免的误差,是我们不可控制的,第二项和第三项是我们能够控制的,分别对应着模型的偏置和方差。偏置随着K变大而变大,方差随着K变大而变小。即K越大,模型越简单,K越小,模型越复杂:
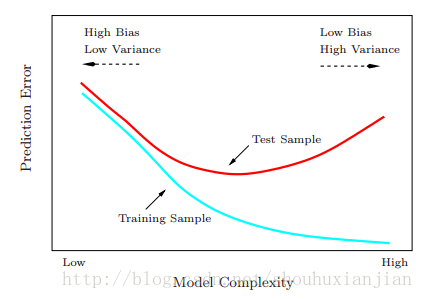
图2.2 esl书上的图2.11
4 搜索优化
实现KNN模型时,主要考虑的还有个问题是如何对训练集的样本点进行快速的K近邻搜索。当特征空间维度太大,或者训练集样本点很多的时候特别重要。最基础的搜索方法就是线性搜索了,可想而知每个测试样本在比较时,都需要去计算一遍训练集的所有样本。效率着实不高。所以才需要量身定做的数据结构搜索方法。
4.1 - KD树
4.2 - Ball树
(待续)
参考资料:
[] Machine Learning A Probabilistic Perspective
[] 李航,统计学习方法
[] The Elements of Statistical Learning Data Mining, Inference, and Prediction (Second Edition)
[] Pedro Domingos,A Few Useful Things to Know About Machine Learning
[] 以叶子为数据的http://www.cnblogs.com/lysuns/articles/4710712.html
[] http://blog.csdn.net/likika2012/article/details/39619687
KNN-笔记(1)的更多相关文章
- KNN笔记
KNN笔记 先简单加载一下sklearn里的数据集,然后再来讲KNN. import numpy as np import matplotlib as mpl import matplotlib.py ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 第2章KNN算法笔记_函数classify0
<机器学习实战>知识点笔记目录 K-近邻算法(KNN)思想: 1,计算未知样本与所有已知样本的距离 2,按照距离递增排序,选前K个样本(K<20) 3,针对K个样本统计各个分类的出现 ...
- opencv2.4.13+python2.7学习笔记--使用 knn对手写数字OCR
阅读对象:熟悉knn.了解opencv和python. 1.knn理论介绍:算法学习笔记:knn理论介绍 2. opencv中knn函数 路径:opencv\sources\modules\ml\in ...
- 机器学习笔记(5) KNN算法
这篇其实应该作为机器学习的第一篇笔记的,但是在刚开始学习的时候,我还没有用博客记录笔记的打算.所以也就想到哪写到哪了. 你在网上搜索机器学习系列文章的话,大部分都是以KNN(k nearest nei ...
- 学习笔记之k-nearest neighbors algorithm (k-NN)
k-nearest neighbors algorithm - Wikipedia https://en.wikipedia.org/wiki/K-nearest_neighbors_algorith ...
- 机器学习实战(Machine Learning in Action)学习笔记————02.k-邻近算法(KNN)
机器学习实战(Machine Learning in Action)学习笔记————02.k-邻近算法(KNN) 关键字:邻近算法(kNN: k Nearest Neighbors).python.源 ...
- kNN算法笔记
kNN算法笔记 标签(空格分隔): 机器学习 kNN是什么 kNN算法是k-NearestNeighbor算法,也就是k邻近算法.是监督学习的一种.所谓监督学习就是有训练数据,训练数据有label标好 ...
- retrival and clustering: week 2 knn & LSH 笔记
华盛顿大学 <机器学习> 笔记. knn k-nearest-neighbors : k近邻法 给定一个 数据集,对于查询的实例,在数据集中找到与这个实例最邻近的k个实例,然后再根据k个最 ...
- 【cs231n作业笔记】一:KNN分类器
安装anaconda,下载assignment作业代码 作业代码数据集等2018版基于python3.6 下载提取码4put 本课程内容参考: cs231n官方笔记地址 贺完结!CS231n官方笔记授 ...
随机推荐
- Python函数式编程(一):高级函数
首先有一个高级函数的知识. 一个函数可以接收另一个函数作为参数,这种函数就称之为高阶函数. def add(x, y, f): return f(x) + f(y) 当我们调用add(-, , abs ...
- canvas代替imgage,可以有效的提高大图片加载的速度!
//加载zepto插件 <script> //定义图片的数量 var total = 17; //获取屏幕的宽度 var zWin = $(window); //定义渲染图片的方法 var ...
- JAVA设计模式——代理(静态代理)
定义 为其它的对象提供一种代理,以控制这个对象的访问 使用场景 当不想直接访问某个对象的时候,就可以通过代理 1.不想买午餐,同事帮忙带 2.买车不用去厂里,去4s店 3.去代理点买火车票,不用去车站 ...
- IT真的是万能的吗?
朋友最近郁闷了,作为企业信息化主管的他最近经常听到的一句话就是:IT是万能的,不能拒绝用户的任何需求.这句话如果是普通用户私下开玩笑说说也就罢了,但现在演变成了老板在会议场合不止一次这么说,那就让人匪 ...
- Python 爬虫实例(爬百度百科词条)
爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入 ...
- element-ui的table动态生成表头和数据,且表中数据可编辑
1.实现表头的动态渲染 2.表头label和prop字段都要定义 3.去判断显示那个数据表 4.实现双击的时候在可编辑 // 双击修改 弹出input tableDbEdit(row, column, ...
- The JSP specification requires that an attribute name is
把另一个博客内容迁移到这里 七月 10, 2016 10:23:12 上午 org.apache.catalina.core.ApplicationDispatcher invoke 严重: Serv ...
- Oracle EBS FA 本年折旧
FUNCTION get_ytd_deprn(p_asset_id IN NUMBER, p_book_type_code IN VARCHAR2, p_rate_source_rule IN VAR ...
- 介绍一个比较了各种浏览器对于HTML5 等标准支持程度的网站
可以选择浏览器种类,版本,比较的功能 网站地址:https://caniuse.com/#comparison
- Vue使用枚举类型实现HTML下拉框
下拉框包含option中的Value和用来显示的选项, 一般后台都是使用的Value值,而不是显示在前台的选项 第一步: 编写下拉框需要的枚举类型 StatusEnum.java public enu ...