Intellij IDEA连接Spark集群
1. 首先安装Scala插件,File->Settings->Plugins,搜索出Scla插件,点击Install安装;
2. File->New Project->maven,新建一个Maven项目,填写GroupId和ArtifactId;
3. 编辑pom.xml文件,添加项目所需要的依赖:
<properties>
<scala.version>2.10.5</scala.version>
<hadoop.version>2.6.5</hadoop.version>
</properties> <repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency> </dependencies>
4. File->Project Structure->Libraries,选择和Spark运行环境一致的Scala版本:
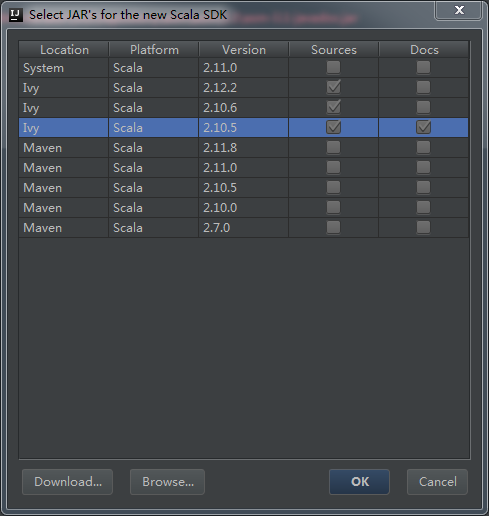
5. File->Project Structure->Modules,在src/main/下面增加一个scala文件夹,并且设置成source文件夹;
6. 在scala文件夹下面新建一个scala文件SparkPi:
import scala.math.random
import org.apache.spark._ object SparkPi {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi").setMaster("spark://master:7077").setJars(Seq("E:\\Intellij\\Projects\\SparkExample\\SparkExample.jar"))
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
println("Time:" + spark.startTime)
val n = math.min(1000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}
7. File->Project Structure->Artifacts,新建一个Jar->From modules with dependencies...,选择Main Class:

设置Output directory,删掉不必要的jar:

7. Build->Build Artifacts...,生成jar,然后再运行,成功!

Intellij IDEA连接Spark集群的更多相关文章
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- IntelliJ IDEA编写的spark程序在远程spark集群上运行
准备工作 需要有三台主机,其中一台主机充当master,另外两台主机分别为slave01,slave02,并且要求三台主机处于同一个局域网下 通过命令:ifconfig 可以查看主机的IP地址,如下图 ...
- windows下通过idea连接hadoop和spark集群
###windows下链接hadoop集群 1.假如在linux机器上已经搭建好hadoop集群 2.在windows上把hadoop的压缩包解压到一个没有空格的目录下,比如是D盘根目录 3.配置环境 ...
- Spark集群测试
1. Spark Shell测试 Spark Shell是一个特别适合快速开发Spark原型程序的工具,可以帮助我们熟悉Scala语言.即使你对Scala不熟悉,仍然可以使用这一工具.Spark Sh ...
- Spark集群模式概述
作者:foreyou出处:http://www.foreyou.net/2015/06/22/spark-cluster-mode-overview/声明:本文采用以下协议进行授权: 署名-非商用|C ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- Spark集群术语
Spark集群术语解析 1. Application Application是用户在Spark上构建(编写)的程序,包含driver program 和executors(分布在集群中多个节点上运行的 ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
随机推荐
- 图标框架Font Awesome
直接引入Font Awesome的css <!DOCTYPE html> <html lang="en"> <head> <meta ch ...
- python笔记27-lxml.etree解析html
前言 之前分享过一个python爬虫beautifulsoup框架可以解析html页面,最近看到lxml框架的语法更简洁,学过xpath定位的,可以立马上手. 使用环境: python 3.6 lxm ...
- Java_集合操作_将元素插入List的指定位置
package test; import java.util.ArrayList; import java.util.List; public class test { public static v ...
- 《MATLAB面向对象程序设计》
<MATLAB面向对象程序设计> 基本信息 作者: 苗志宏 马金强 出版社:电子工业出版社 ISBN:9787121233449 上架时间:2014-6-18 出版日期:2014 年 ...
- linux 7z 命令编译安装,mac安装p7zip
linux 7z 命令编译安装 7zip是一个开源的压缩软件 7z格式是压缩率最高的格式 服务器备份 数据几个g 要是tar压缩下载的话 时间太长 7zip压缩出来体积很小 首先安装 我这是 ce ...
- Restful API 的设计规范(转)
1. URI URI 表示资源,资源一般对应服务器端领域模型中的实体类.URI规范 不用大写; 用中杠-而不用下杠_; 参数列表要encode; URI中的名词表示资源集合,使用复数形式; 资源集合与 ...
- 服务器配置多版本CUDA、CUdnn(不同Linux账户使用不同CUDA、CUdnn版本)
一.由于实验室大家使用的CUDA.CUdnn不同,所以需要在同一台服务器安装多个版本,而且要不引起冲突,方法如下: 1.一般来说CUDA安装在 /usr/local 目录下(当然你可以通过“echo ...
- [转]你如何面对—LNMP高并发时502
From : http://www.topthink.com/topic/5683.html 之前php-fpm配置: 单个php-fpm实例,使用socket方式,内存8G 静态方式,启动php-f ...
- Host-Only模式
Host-Only模式 在Host-Only模式下,虚拟网络是一个全封闭的网络,它唯一能够访问的就是主机.其实Host-Only网络和NAT网络很相似,不同的地方就是Host-Only网络没有NAT服 ...
- 用网站(WebSite而不是WebProject)项目构建ASP.NET MVC网站
从ASP.NET MVC第一个版本开始到现在,创建ASP.NET MVC项目的官方方法只有一个,“文件”->“新建”->“项目”,然后选择ASP.NET MVC X Web应用程序. 这种 ...