IntelliJ IDEA编写的spark程序在远程spark集群上运行
准备工作
需要有三台主机,其中一台主机充当master,另外两台主机分别为slave01,slave02,并且要求三台主机处于同一个局域网下
通过命令:ifconfig
可以查看主机的IP地址,如下图所示
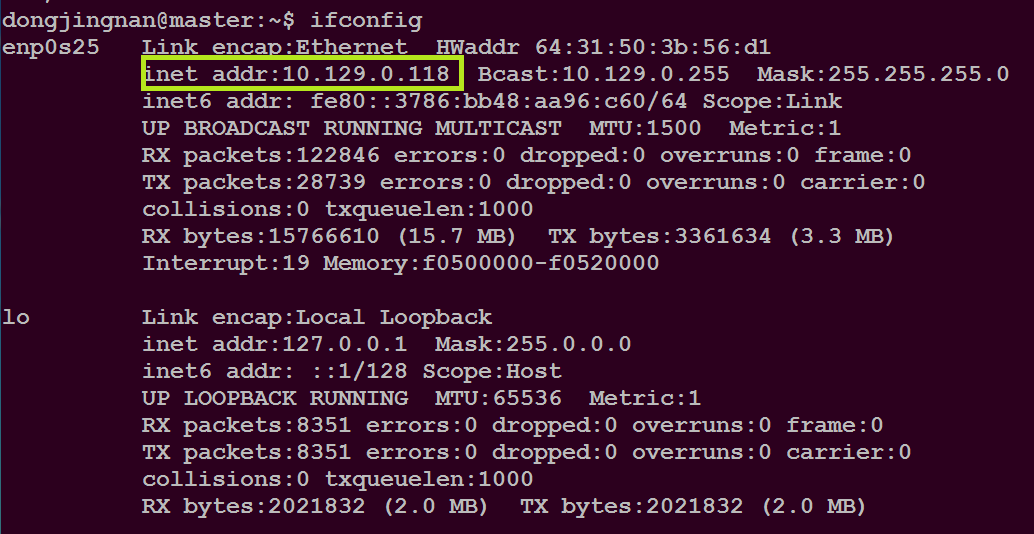
本集群的三台机器的IP地址如下
10.129.0.118 master
10.129.0.223 slave01
10.129.0.124 slave02
通过命令:ping IP地址
可以查看与另一台主机的连通性
如下所示
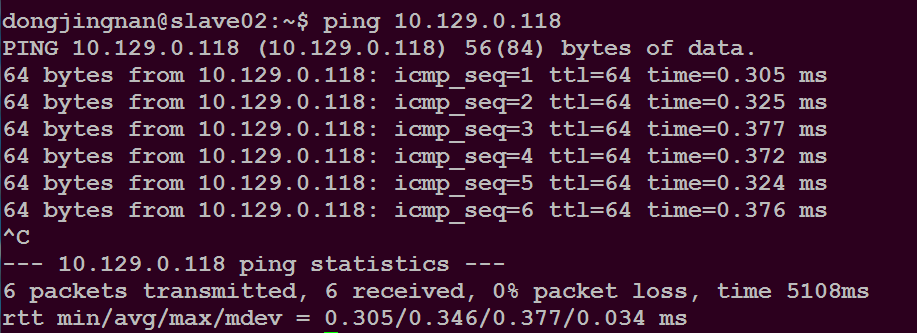
注意:在shell命令下通过CTRL+C 可以结束命令的执行
三台主机的用户名均为dongjingnan
修改三台主机的/etc/hosts

在文件开头添加如下内容
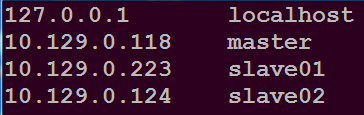
配置ssh无密码登录本机和集群
在master主机上执行如下命令



将master主机上的公钥发给slave01,slave02

在slave01和slave02上都执行如下命令


可以通过命令:ssh 主机名
登录指定主机,如下所示
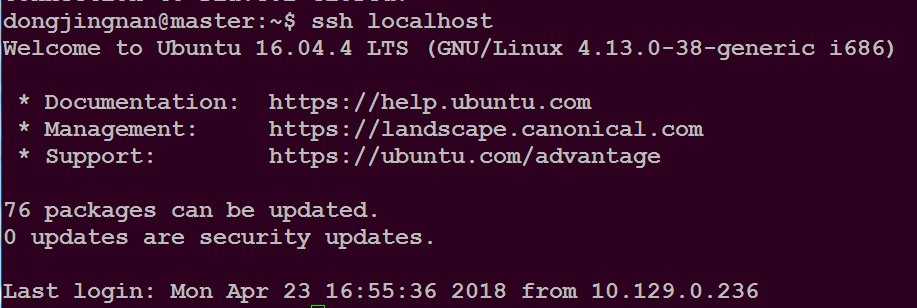
通过命令:exit //退出

JDK和hadoop的配置和安装

如果无法安装可以通过命令:sudo apt-get update //更新软件库
执行命令:sudo vim ~/.bashrc
在~/.bashrc中添加如下内容
export JAVA_HOME=/usr/lib/jvm/default-java
执行命令:source ~/.bashrc
使~/.bashrc文件修改生效
执行命令:java -version
查看jdk版本号,如下图所示

通过网站https://mirrors.cnnic.cn/apache/hadoop/common/
下载hadoop的最新稳定的版本
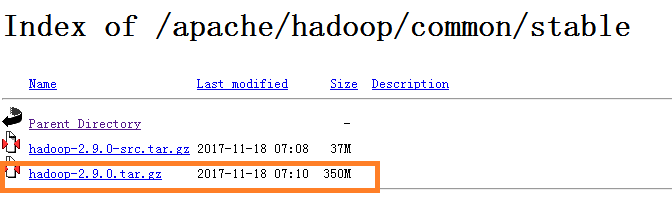
在用户主目录下执行命令$ sudo tar -zxvf ~/Downloads/hadoop-2.9.0.tar.gz -C /usr/local
在用户主目录下执行命令$ cd /usr/local/
在 /usr/local/ 目录下执行命令$ sudo mv ./hadoop-2.9.0 ./hadoop
在 /usr/local/ 目录下执行命令$ sudo chown -R dongjingnan ./hadoop //将dongjingnan替换成你的用户名
编辑 ~/.bahrc 文件,在里面添加如下内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存之后,执行命令: source ~/.bashrc
切换到目录/usr/local/hadoop/etc/hadoop 并查看该目录下的文件
执行命令$ sudo vim slaves
将里面的内容替换成
slave01
slave02
保存后,执行命令$ sudo vim core-site.xml
修改成如下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
保存后,执行命令$ sudo vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
保存后,执行命令$ sudo cp mapred-site.xml.template mapred-site.xml
执行命令$ sudo vim mapred-site.xml
添加如下内容
<configuration>
<porperty>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
保存后,执行命令$ sudo vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanage.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>
保存后,将master上的/usr/local/hadoop目录复制到各个节点上
在用户的主目录执行命令$ sudo tar -zcf ~/hadoop.master.tar.gz /usr/local/hadoop
在用户的主目录执行命令$ scp ~/hadoop.master.tar.gz slave01:/home/dongjingnan
在用户的主目录执行命令$ scp ~/hadoop.master.tar.gz slave02:/home/dongjingnan
执行命令$ ssh slave01
在slave01的主目录执行命令$ sudo tar -zxvf ~/hadoop.master.tar.gz /usr/local
在slave01的主目录执行命令$ sudo chown -R dongjingnan /usr/local/hadoop
执行命令$ exit
在master主目录执行命令$ ssh slave02
在slave02的主目录执行命令$ sudo tar -zxvf ~/hadoop.master.tar.gz /usr/local
在slave02的主目录执行命令$ sudo chown -R dongjingnan /usr/local/hadoop
执行命令$ exit
在master主目录执行如下命令$ sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
添加一个属性
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
保存后,在master主目录下执行如下命令$ sudo vim yarn-site.xml
删除yarn.nodemanager.resource.memory-mb属性
保存后退出
在master主目录下执行命令$ hadoop namenode -format
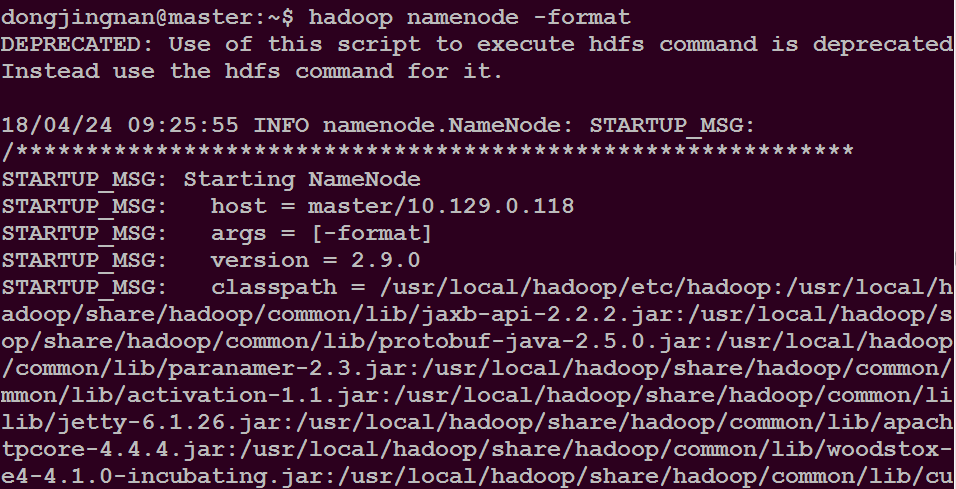
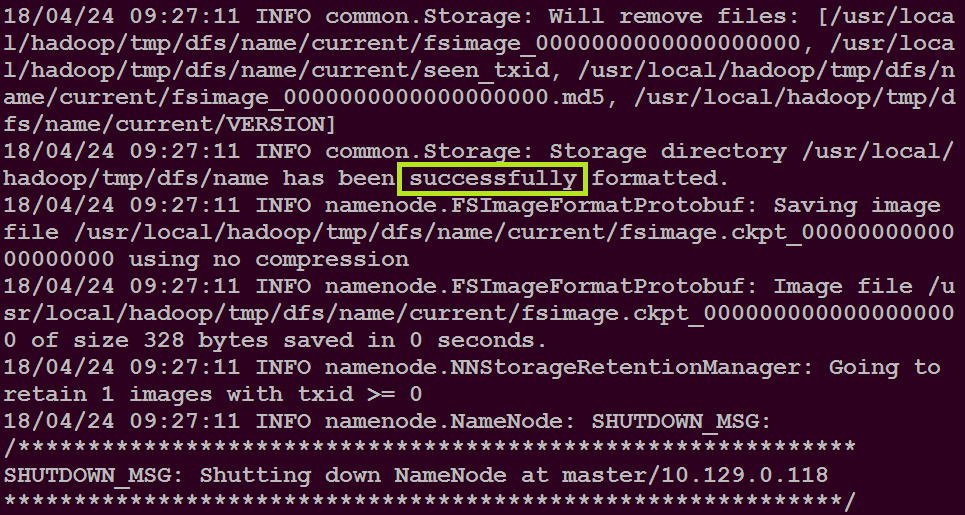
在master主目录下执行命令$ start-all.sh
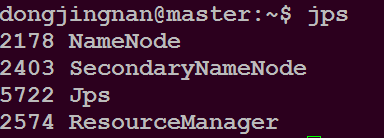
在master主目录下执行命令$ jps
可以看到如下进程
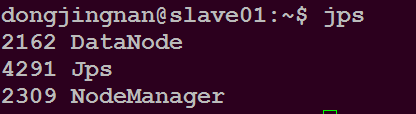
在slave01主目录下执行命令$ jps
可以看到如下进程
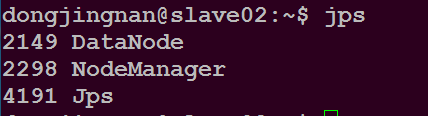
在slave02主目录下执行命令$ jps
可以看到如下进程
到此,hadoop集群安装完毕
hadoop集群启动时可能出现的问题
问题描述:slave01和slave02都没有出现DataNode进程
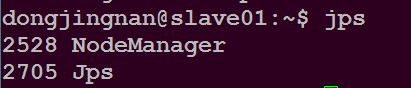
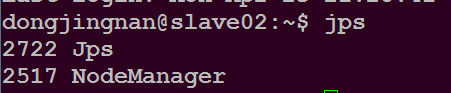
解决办法:每次启动集群前删除slave01和slave02节点上/usr/local/hadoop/tmp/dfs/目录下的data文件夹,然后新建一个data空的文件夹
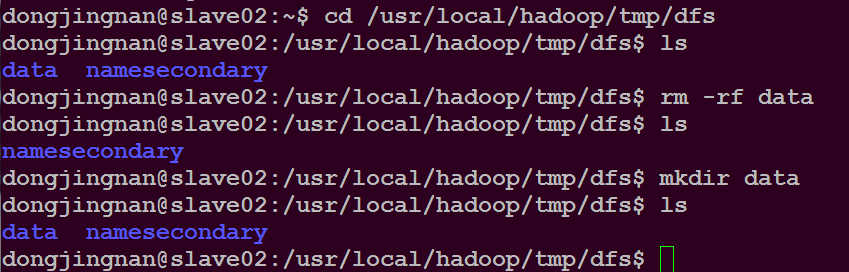
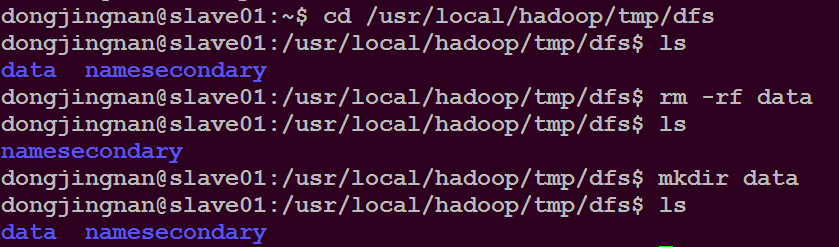
再重新格式化namenode节点,就可以解决了。
在master节点执行命令$ stop-all.sh
可以关闭hadoop集群
接下来进行spark集群的安装
在火狐浏览器输入网址http://spark.apache.org/downloads.html 可以下载spark软件包
在master主目录下执行命令$ sudo tar -zxvf ~/Downloads/spark-2.3.0-bin-without-hadoop.tgz -C /usr/local
在master主目录下执行命令$ sudo mv /usr/local/spark-2.3.0-bin-without-hadoop /usr/local/spark
在master主目录下执行命令$ sudo chown -R dongjingnan /usr/local/spark
修改~/.bashrc文件
添加如下内容

执行命令$ source ~/.bashrc
执行命令$ cd /usr/local/spark/conf
执行命令$ cp slaves.template slaves
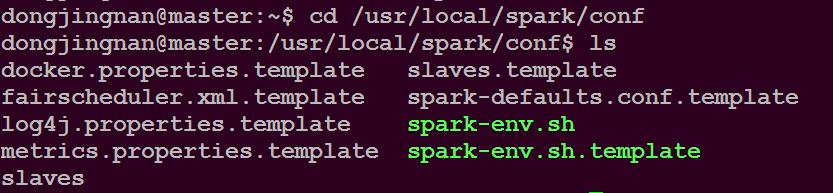
执行命令$ sudo vim slaves
添加如下内容
slave01
slave02
执行命令$ cp spark-env,.sh.template spark-env.sh
执行命令$ sudo vim spark-env.sh

添加如下内容

SPARK_MASTER_IP设置为你自己的master的IP地址
保存后,执行如下命令$
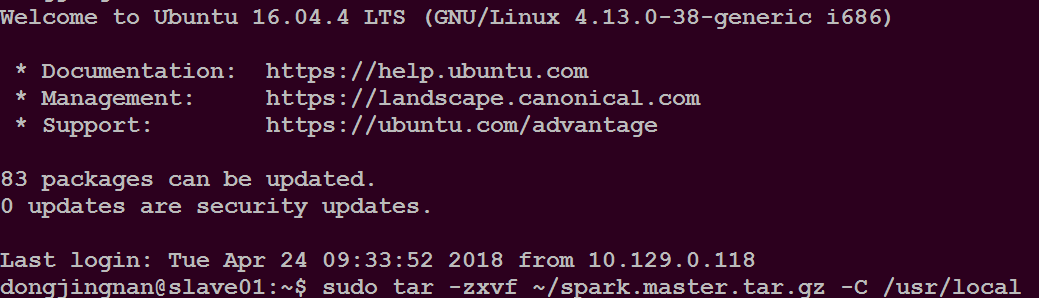
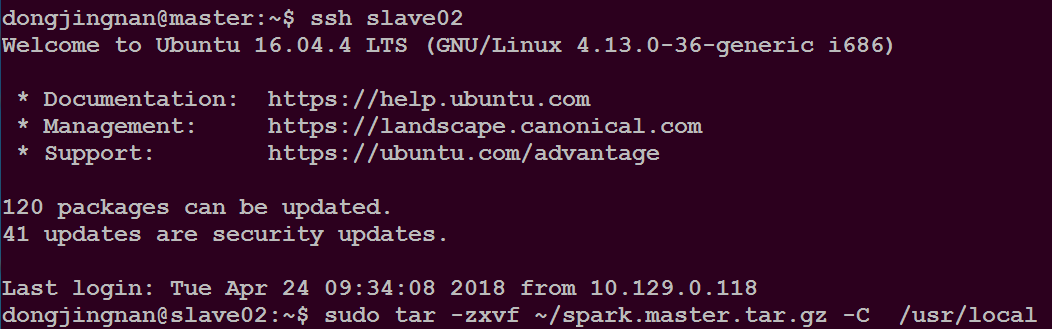
将/usr/local/目录下的spark文件夹打包后发送到slave01和slave02
如下所示


将slave01和slave02节点上的spark.master.tar.gz解压到/usr/local/目录下,并授权给slave01和slave02的用户名


启动hadoop集群
执行命令$ start-all.sh
启动spark集群
执行命令$ start-master.sh
执行命令$ start-slaves.sh
如下图所示

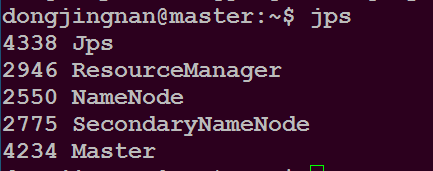
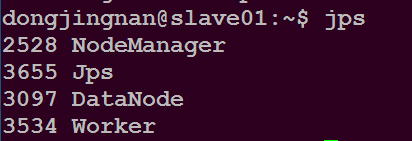
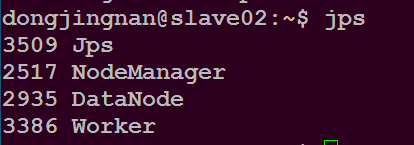
在master主机登录网址http://master:8080 可以看到如下内容
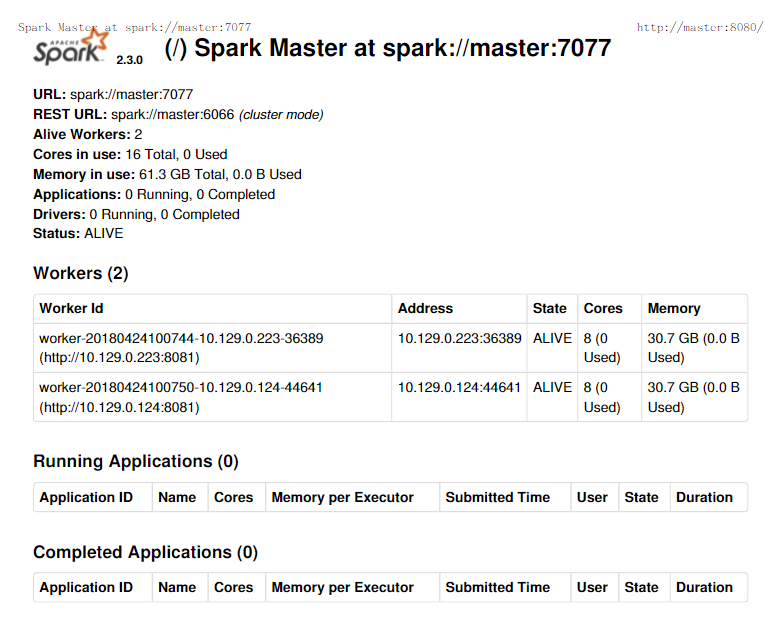
关闭spark集群
执行命令$ stop-slaves.sh
执行命令$ stop-master.sh
在集群中运行应用程序JAR包

在集群中运行spark-shell
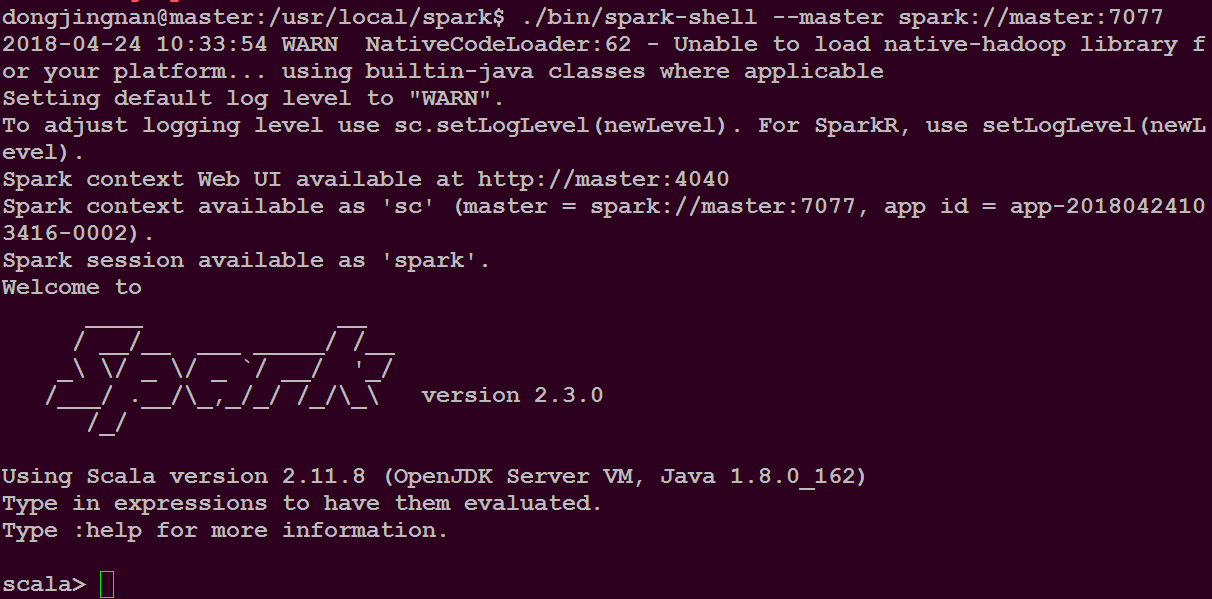
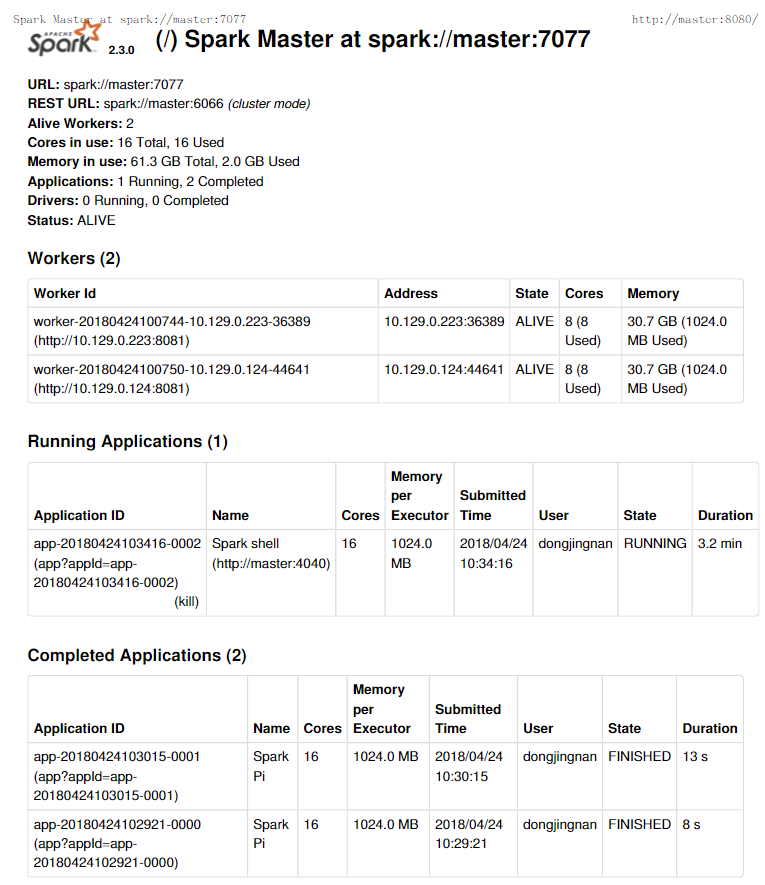
用户在master主机上的火狐浏览器登录网址http://master:8080/ 查看应用的运行情况
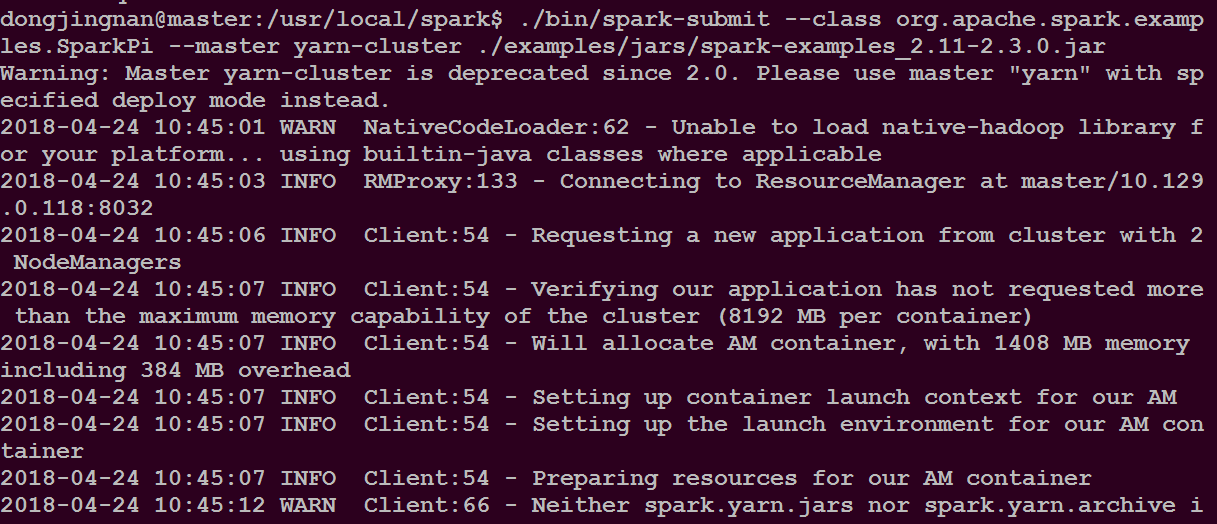
向hadoop yarn 集群管理器提交应用
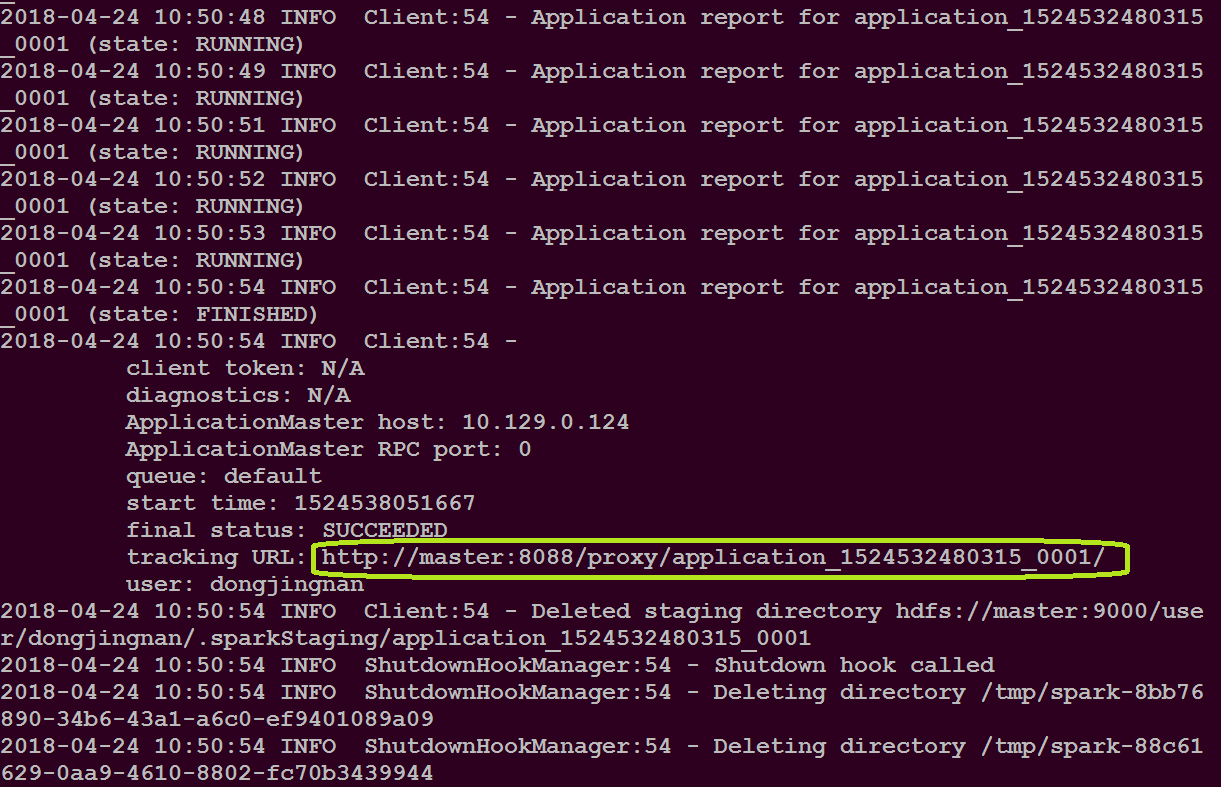
在master主机登录上图绿色圈住的网址,查看应用的运行情况

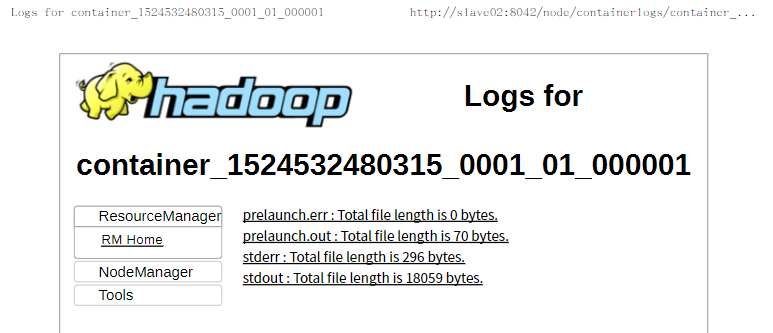
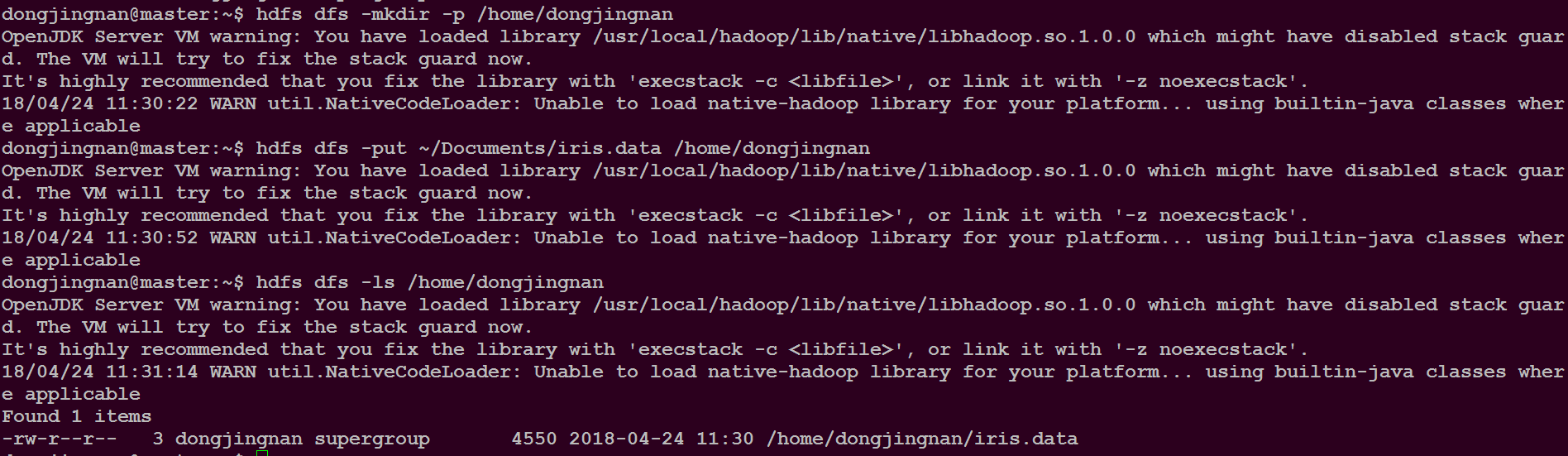
为了进行下面的程序,请把所需的文件上传到hdfs中,以备后面使用,另外每次关机之后,再重启后又要重新做一遍
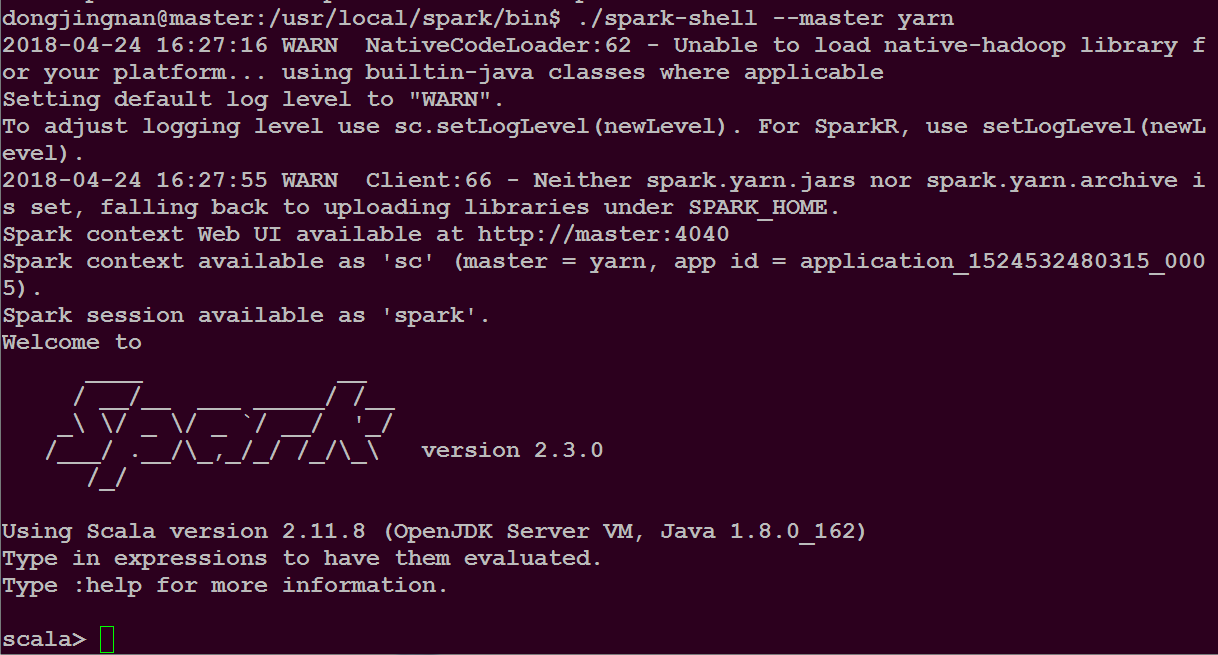
在集群中运行spark-shell
本实验所需的数据集可以在网址https://archive.ics.uci.edu/ml/machine-learning-databases/ 下载
实验所需的数据集是鸢尾花数据集
在网址https://www.jetbrains.com/idea/downloads/#section=windows 下载Intellij IDEA
选择使用的操作系统的环境,建议下载Ultimate版本,因为好像Community版本不能够将编写的程序打包成jar文件,下文要用到打包的jar文件
刚开始的时候不要设置SparkConf后的setmaster()内容
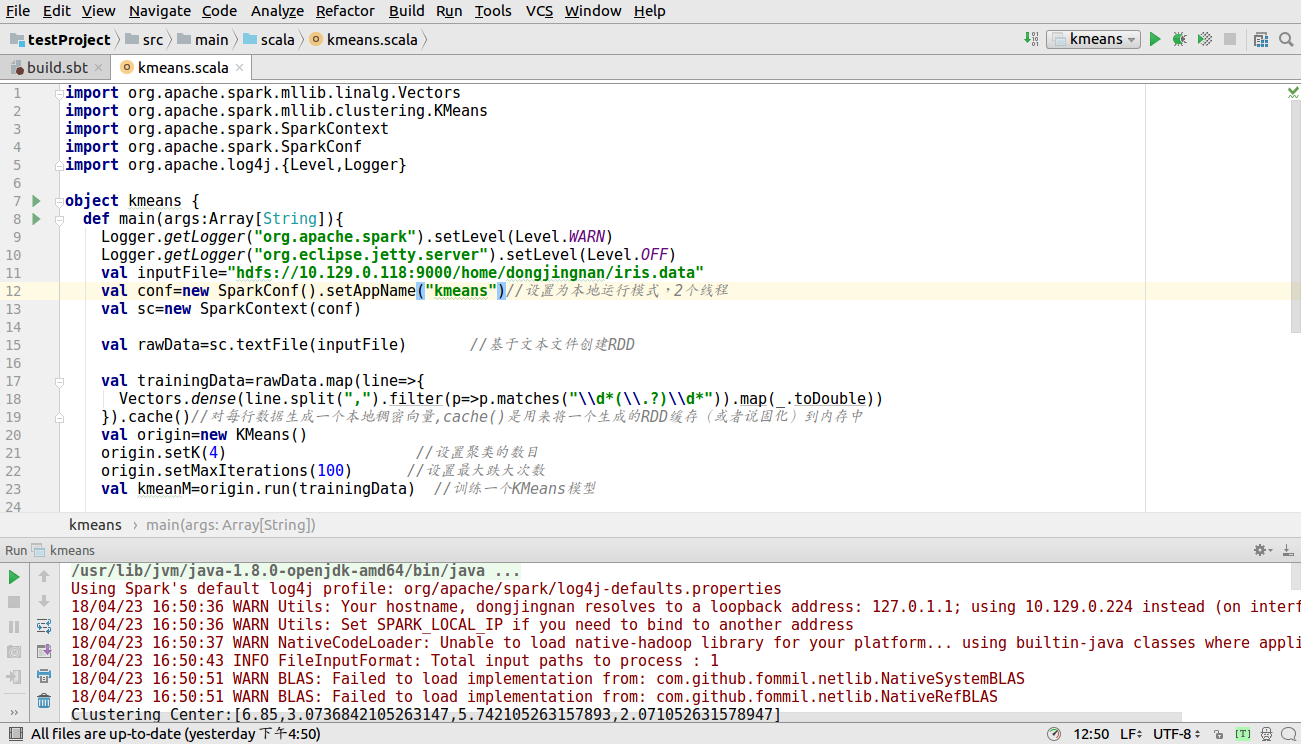
kmeans算法的实现代码如下图所示
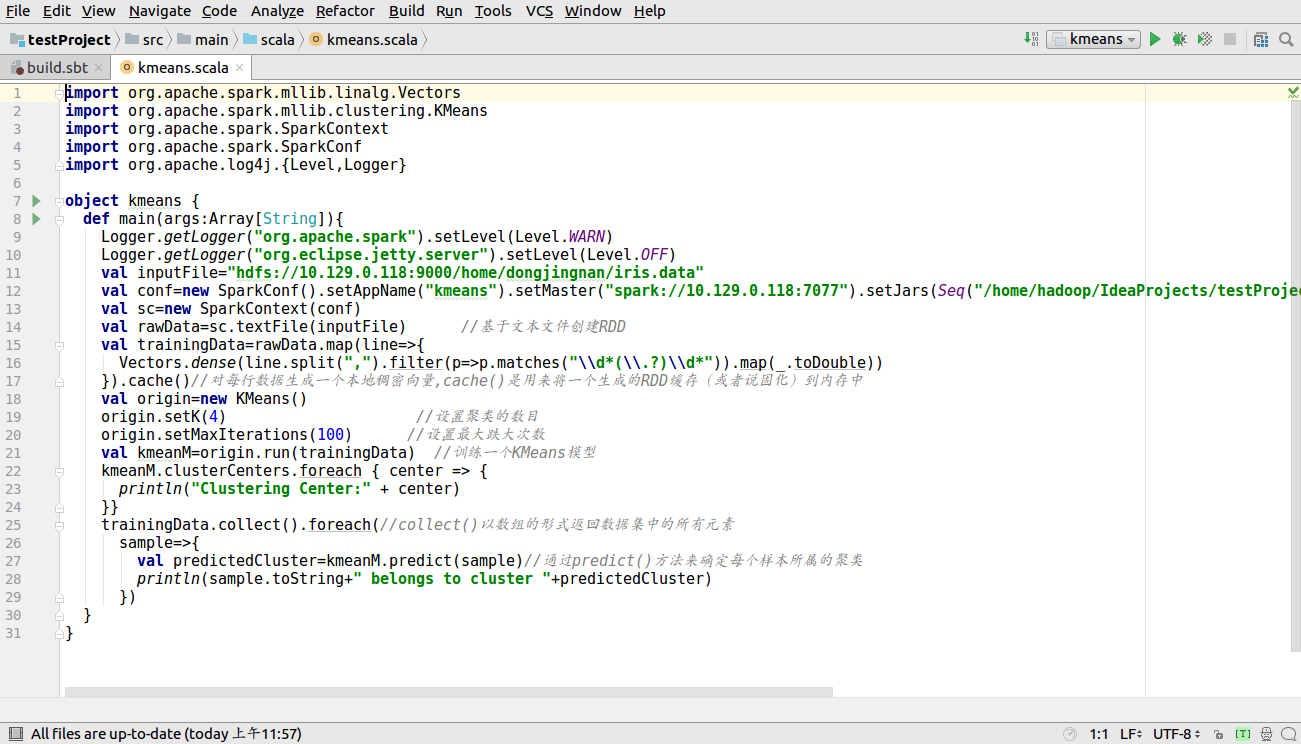
打包过程如下所示,点击file--Project Structure--单击+号
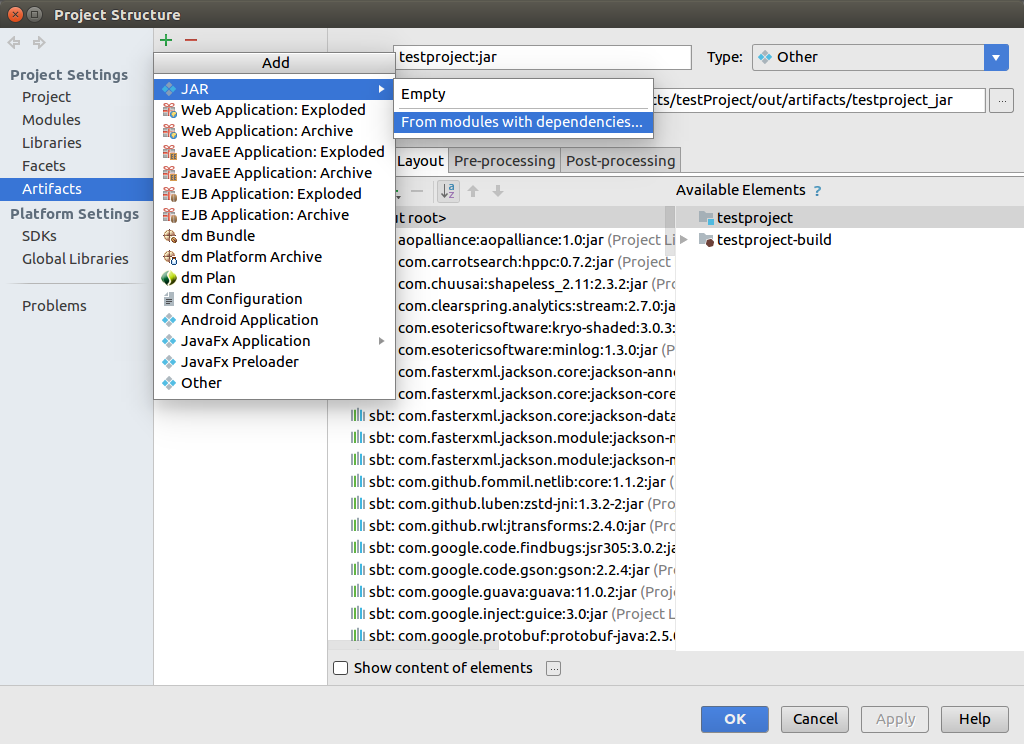
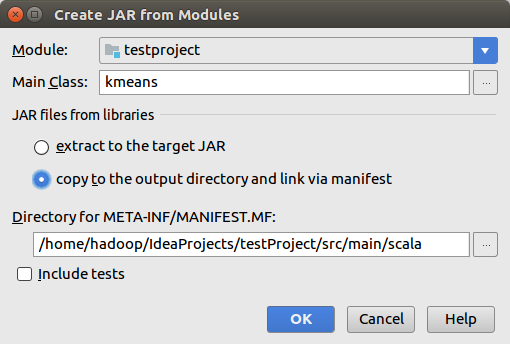
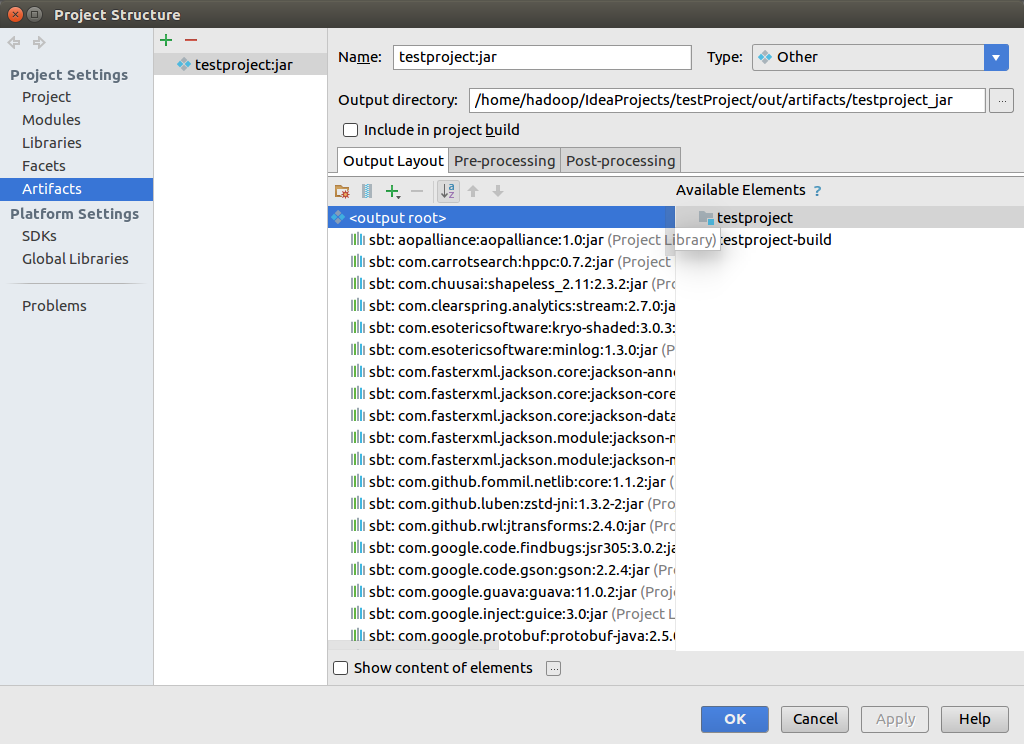
单击Build-Build Artifacts.. 之后在单击下图中的Build
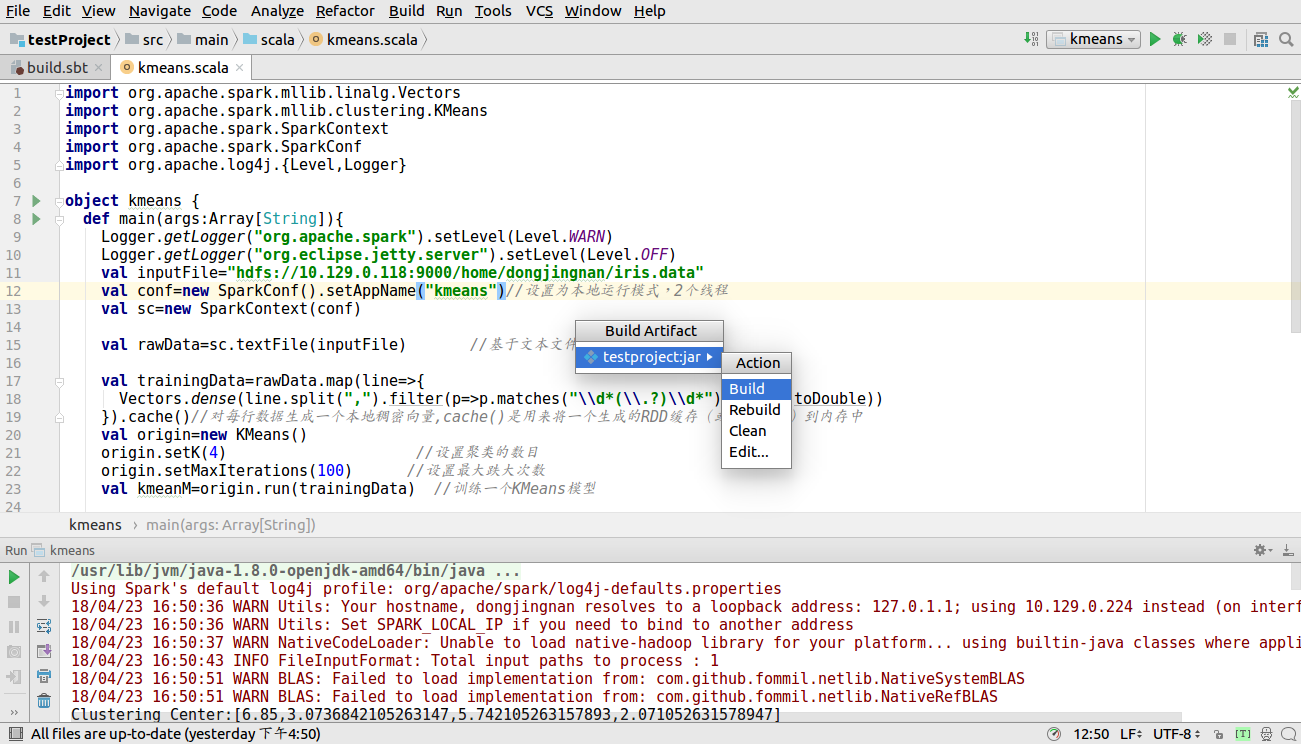
稍等会,可以看到下图中出现out 文件夹
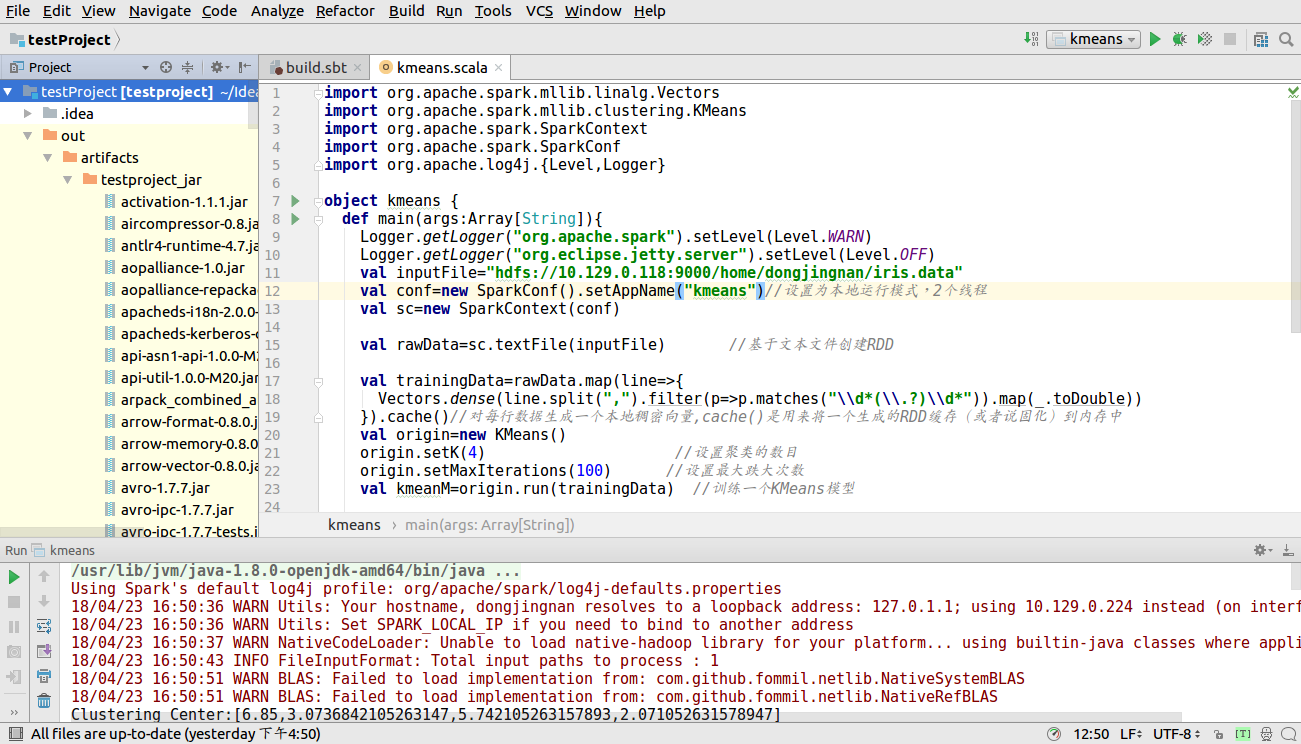
找到项目打包成的jar文件夹,如下图所示
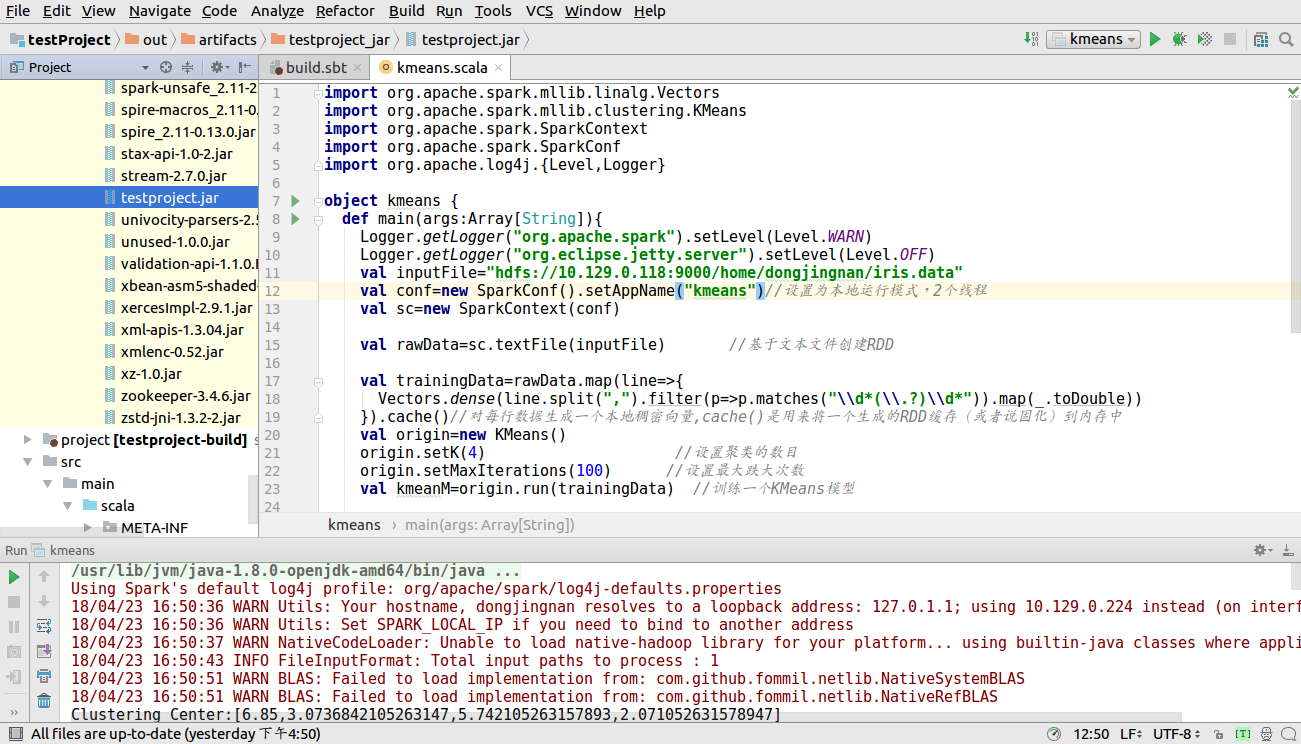
此时设置SparkConf后的setMaster()和setJar()
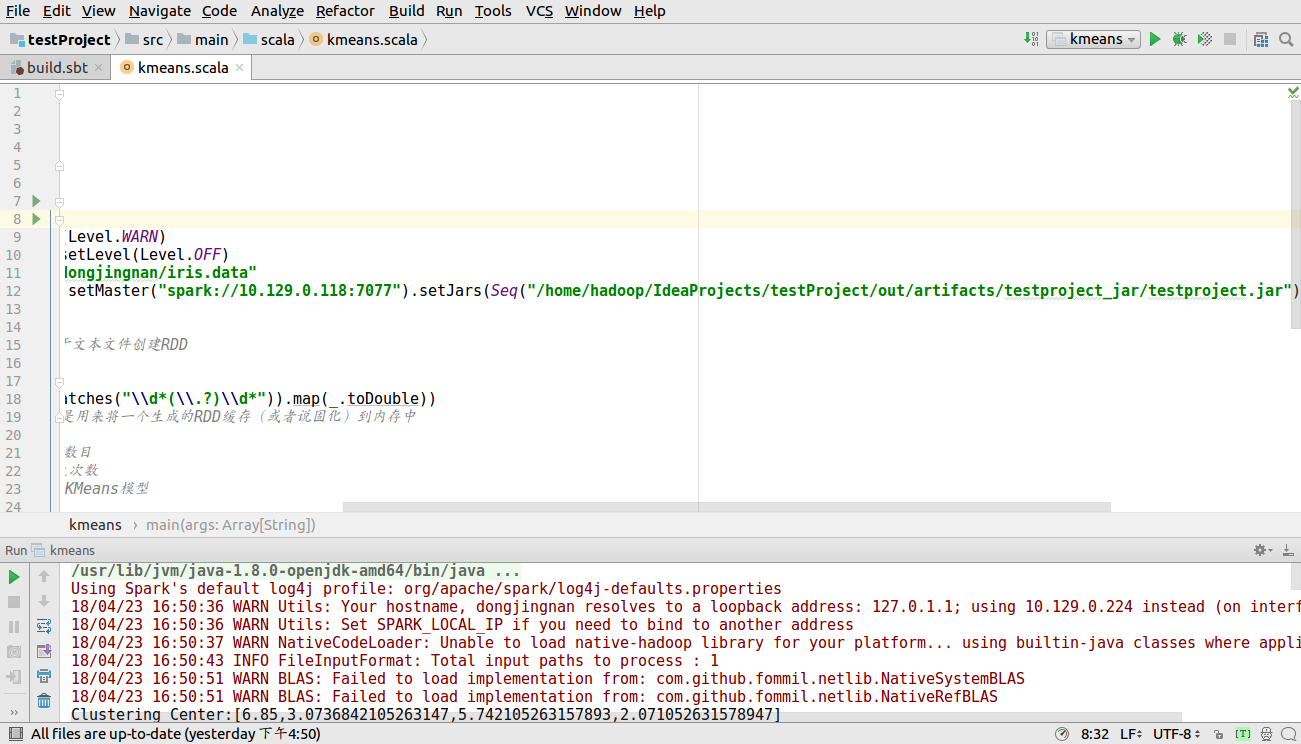
接下来运行程序单击Run-->Run kmeans 出现如下图所示
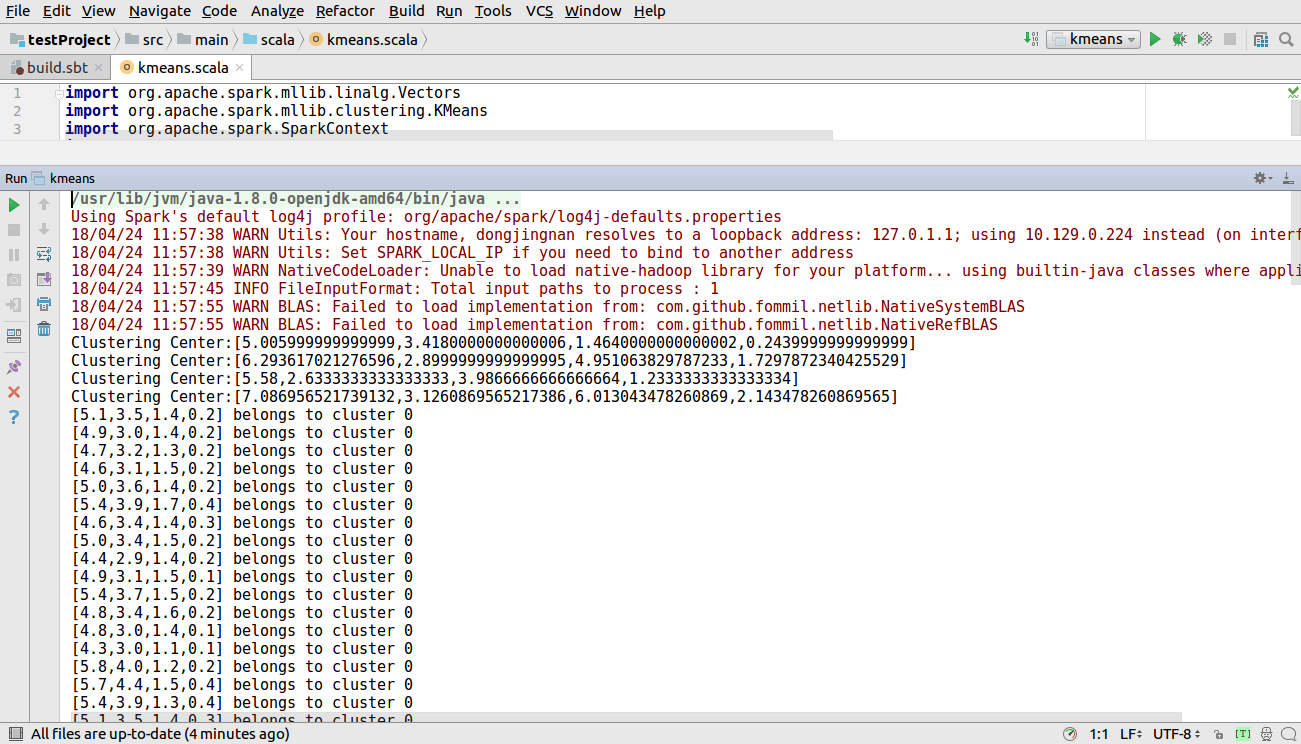
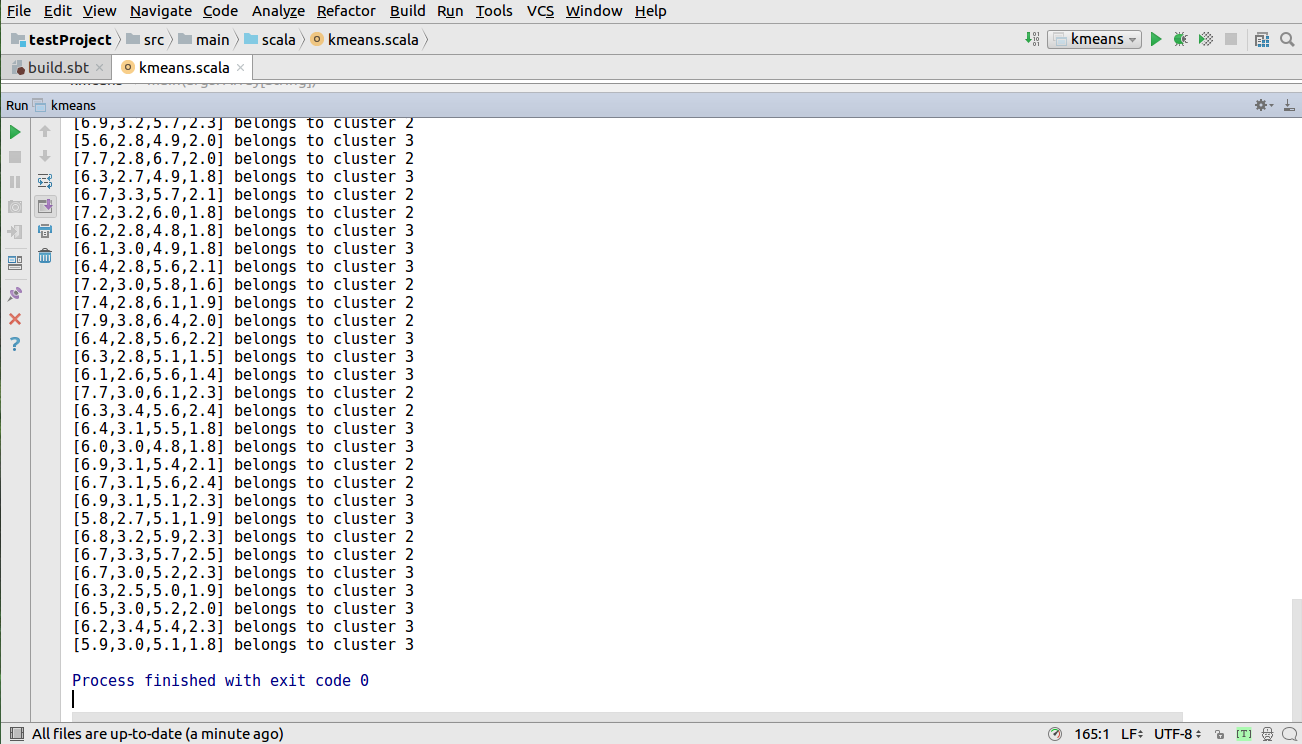
打开网址htttps://master:7077/查看应用运行情况
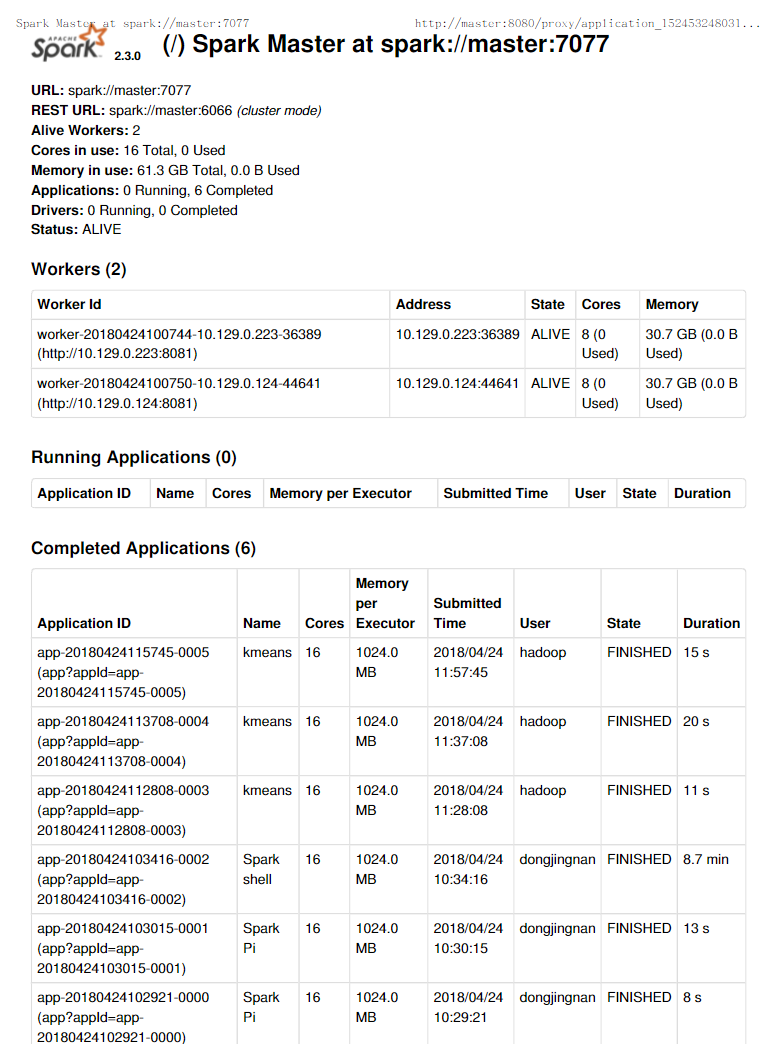
到此,整个项目运行完毕。
谢谢观看,不对之处,欢迎多多指正。
IntelliJ IDEA编写的spark程序在远程spark集群上运行的更多相关文章
- Spark优化之二:集群上运行jar程序,状态一直Accepted且不停止不报错
如果运行Spark集群时状态一直为Accepted且不停止不报错,比如像下面这样的情况: 15/06/14 11:33:33 INFO yarn.Client: Application report ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控
写在前面 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试 用python + hado ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- 在集群上运行Spark
Spark 可以在各种各样的集群管理器(Hadoop YARN.Apache Mesos,还有Spark 自带的独立集群管理器)上运行,所以Spark 应用既能够适应专用集群,又能用于共享的云计算环境 ...
随机推荐
- HBase—列族数据库的术语
1. 列族数据库的基本组件 键空间,行键,列,列族 2. 什么是键空间 keyspace? 键空间 keyspace 是列族数据库的顶级数据结构,它在逻辑上能够容纳列族,行键以及与之相关的其他数据结构 ...
- DOM基础操作(三)
DOM剩余的两个操作一并带来! 1.删除操作 removeChild 这个方法依然是父级调用的,参数就是要删除的子节点,其实实际上是剪切,这个方法会把我们删除掉的元素给返回,我们可以用一个变量去保存这 ...
- DB2 Metadata
http://www.devart.com/dotconnect/db2/docs/MetaData.html Instead of specifying the metadata collectio ...
- Java 实时论坛 - Sym 1.4.0 发布
简介 Sym 是一个用 Java 写的实时论坛,欢迎来体验! 如果你需要搭建一个企业内网论坛,请使用 SymX. 作者 Sym 的主要作者是 Daniel 与 Vanessa,所有贡献者可以在这里看到 ...
- Selenium之TestNG安装
一.在Eclipse中安装TestNG 1.打开eclipse-->help-->Install New Software-->Add,输入Name和Location后,点击OK. ...
- malloc()函数,calloc()函数,realloc()函数,free()函数
malloc()函数 头文件:#include <stdlib.h> malloc() 函数用来动态地分配内存空间,其原型为:void* malloc (size_t size); [参数 ...
- MyBatis基本配置和实践(四)
一.Mybatis整合spring 1.整合思路 SqlSessionFactory对象应该放到spring容器中作为单例存在. 传统dao的开发方式中,应该从spring容器中获得sqlsessio ...
- Attribute+Reflection,提高代码重用
这篇文章两个目的,一是开阔设计的思路,二是实例代码可以拿来就用. 设计的思路来源于<Effective c#>第一版Item 24: 优先使用声明式编程而不是命令式编程.特别的地方是,希望 ...
- 【Oracle】Update方法
1.单表更新 update customers set city_name='山西省太原市' where city_name='山西太原' 2.两表(多表)关联update -- 被修改值由另一个表运 ...
- leetcode Ch8-Others
1. Rotate Image 旋转图像 顺时针旋转90度:先沿水平线翻转,再沿主对角线翻转. 逆时针旋转90度:先沿竖直线翻转,再沿主对角线翻转. 顺时针旋转180度:水平翻转和竖直翻转各一次. 逆 ...