『Sklearn』特征向量化处理
『Kaggle』分类任务_决策树&集成模型&DataFrame向量化操作
|
1
2
3
4
5
6
7
8
9
|
'''特征提取器'''from sklearn.feature_extraction import DictVectorizervec = DictVectorizer(sparse=False)print(X_train.to_dict(orient='record'))X_train = vec.fit_transform(X_train.to_dict(orient='record'))print(X_train)print(vec.feature_names_)X_test = vec.transform(X_test.to_dict(orient='record')) |
涉及两个操作,
- DataFrame字典化
- 字典向量化
1.DataFrame字典化

|
1
2
3
4
5
6
7
8
9
10
|
import numpy as npimport pandas as pdindex = ['x', 'y']columns = ['a','b','c']dtype = [('a','int32'), ('b','float32'), ('c','float32')]values = np.zeros(2, dtype=dtype)df = pd.DataFrame(values, index=index)df.to_dict(orient='record') |
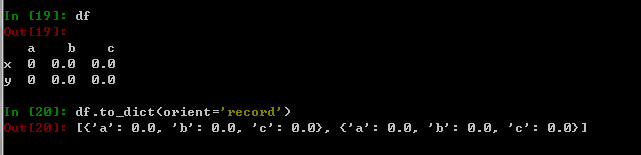
2.字典向量化
DictVectorizer: 将dict类型的list数据,转换成numpy array,具有属性vec.feature_names_,查看提取后的特征名。
具体效果如下,
>>> from sklearn.feature_extraction import DictVectorizer
>>> v = DictVectorizer(sparse=False)
>>> D = [{'foo': 1, 'bar': 2}, {'foo': 3, 'baz': 1}]
>>> X = v.fit_transform(D)
>>> X
array([[ 2., 0., 1.],
[ 0., 1., 3.]])
>>> v.transform({'foo': 4, 'unseen_feature': 3})
array([[ 0., 0., 4.]])
数字的特征不变,没有该特征的项给赋0,对于未参与训练的特征不予考虑。
对应到本程序,
print(X_train.to_dict(orient='record')):
[{'sex': 'male', 'pclass': '3rd', 'age': 31.19418104265403},
...... ....... ....... ......
{'sex': 'female', 'pclass': '1st', 'age': 31.19418104265403}]
提取特征,
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
print(X_train):[[ 31.19418104 0. 0. 1. 0. 1. ]
[ 31.19418104 1. 0. 0. 1. 0. ]
[ 31.19418104 0. 0. 1. 0. 1. ]
...,
[ 12. 0. 1. 0. 1. 0. ]
[ 18. 0. 1. 0. 0. 1. ]
[ 31.19418104 0. 0. 1. 1. 0. ]]
数字的年龄没有改变,其他obj特征变成了onehot编码的特征,各列意义可以查看的,
print(vec.feature_names_):
['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male']
一个直观例子:
v = DictVectorizer(sparse=False)
v.fit_transform([{'a':1},{'a':2},{'a':3}])
Out[7]:
array([[ 1.],
[ 2.],
[ 3.]])
v.feature_names_
Out[8]:
['a']
v.fit_transform([{'a':'1'},{'a':'2'},{'a':'3'}])
Out[9]:
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
v.feature_names_
Out[10]:
['a=1', 'a=2', 'a=3']
注意,v.feature_names_输出顺序和v.fit_transform()生成顺序是一一对应的,
v.fit_transform([{'a':'2q'},{'a':'1v'},{'a':'3t'},{'a':'3t'}])
Out[17]:
array([[ 0., 1., 0.],
[ 1., 0., 0.],
[ 0., 0., 1.],
[ 0., 0., 1.]])
v.feature_names_
Out[18]:
['a=1v', 'a=2q', 'a=3t']然后,
np.argmax(np.array([[ 0., 1., 0.],
[ 1., 0., 0.],
[ 0., 0., 1.],
[ 0., 0., 1.]]),axis=1)
Out[19]:
array([1, 0, 2, 2])
进一步的,也就是说v.feature_names_输出顺序对应于v.fit_transform()的非onehot排序。
『Sklearn』特征向量化处理的更多相关文章
- 『Sklearn』框架自带数据集接口
自带数据集类型如下: # 自带小型数据集# sklearn.datasets.load_<name># 在线下载数据集# sklearn.datasets.fetch_<name&g ...
- 『Sklearn』数据划分方法
原理介绍 K折交叉验证: KFold,GroupKFold,StratifiedKFold, 留一法: LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,Lea ...
- 『TensorFlow』读书笔记_降噪自编码器
『TensorFlow』降噪自编码器设计 之前学习过的代码,又敲了一遍,新的收获也还是有的,因为这次注释写的比较详尽,所以再次记录一下,具体的相关知识查阅之前写的文章即可(见上面链接). # Aut ...
- 『TensorFlow』读书笔记_VGGNet
VGGNet网络介绍 VGG系列结构图, 『cs231n』卷积神经网络工程实践技巧_下 1,全部使用3*3的卷积核和2*2的池化核,通过不断加深网络结构来提升性能. 所有卷积层都是同样大小的filte ...
- 『计算机视觉』Mask-RCNN_从服装关键点检测看KeyPoints分支
下图Github地址:Mask_RCNN Mask_RCNN_KeyPoints『计算机视觉』Mask-RCNN_论文学习『计算机视觉』Mask-RCNN_项目文档翻译『计算机视觉』Mas ...
- 『TensotFlow』RNN中文文本_上
中文文字预处理流程 文本处理 读取+去除特殊符号 按照字段长度排序 辅助数据结构生成 生成 {字符:出现次数} 字典 生成按出现次数排序好的字符list 生成 {字符:序号} 字典 生成序号list ...
- 『cs231n』通过代码理解风格迁移
『cs231n』卷积神经网络的可视化应用 文件目录 vgg16.py import os import numpy as np import tensorflow as tf from downloa ...
- 『计算机视觉』Mask-RCNN_锚框生成
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 『计算机视觉』Mask-RCNN_推断网络其六:Mask生成
一.Mask生成概览 上一节的末尾,我们已经获取了待检测图片的分类回归信息,我们将回归信息(即待检测目标的边框信息)单独提取出来,结合金字塔特征mrcnn_feature_maps,进行Mask生成工 ...
随机推荐
- python webdriver操作浏览器句柄
断言 assert self.driver.title.find(u"搜狗搜索引擎")>=0, "assert error" 浏览器后退,前进,前进前要先 ...
- C++ Word Count 发布程序
前段时间,模仿 Linux 系统下的 wc 程序,在 Windows 系统环境下使用 C/C++ 实现了一个相似的 WC 程序,只不过有针对性,针对的是 C/C++,Java 等风格的源代码文件. 此 ...
- Linux基础命令---dumpe2fs
dumpe2fs 显示ext2.ext3.ext4文件系统的超级快和块组信息.此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.openSUSE.Fedora. 1.语法 ...
- chrome谷歌浏览器用这种方式清除缓存比较方便了,必须是调试模式才行
chrome谷歌浏览器用这种方式清除缓存比较方便了 PS:必须是调试模式才行,可以不是手机模式 ,有些低版本浏览器可能没有这个功能. ----------------------------- ...
- Linux学习笔记之Centos7安装GNOME桌面环境
最小化安装Centos7,系统默认是命令行界面,如果像我一样有特殊需求,这时就需要我们手动来安装用户图形界面了. 1.查看一下当前的运行级别和可以安装的group. systemctl get-def ...
- 使整个页面变灰的css代码
* { filter:progid:DXImageTransform.Microsoft.BasicImage(grayscale=); -webkit-filter: grayscale(%); - ...
- 20145221高其_PC平台逆向破解_advanced
20145221高其_PC平台逆向破解_advanced 实践目录 shellcode注入 Return-to-libc 攻击实验 shellcode注入 概述 Shellcode实际是一段代码(也可 ...
- Visual Studio 2012 编译错误【error C4996: 'scanf': This function or variable may be unsafe. 】的解决方案(转载)
转载:http://www.th7.cn/Program/c/201303/127343.shtml 原因是Visual C++ 2012 使用了更加安全的 run-time library rout ...
- C# string字节数组转换
string转byte[]:byte[] byteArray = System.Text.Encoding.Default.GetBytes ( str ); byte[]转string:string ...
- 如果恨一个程序员,忽悠他去做iOS开发
如果你恨一个程序员,忽悠他去做iOS开发.不管他背景是cobel还是 java,送他一本iOS开发的书.这种书最好是国人写的,容易以偏概全一点,相比洋鬼子的书,更容易学到皮毛.这叫舍不得孩子套不着狼, ...