Flume-1.8.0_部署与常用案例
该文章是基于 Hadoop2.7.6_01_部署 进行的
Flume官方文档:FlumeUserGuide
常见问题:记flume部署过程中遇到的问题以及解决方法(持续更新)
1. 前言
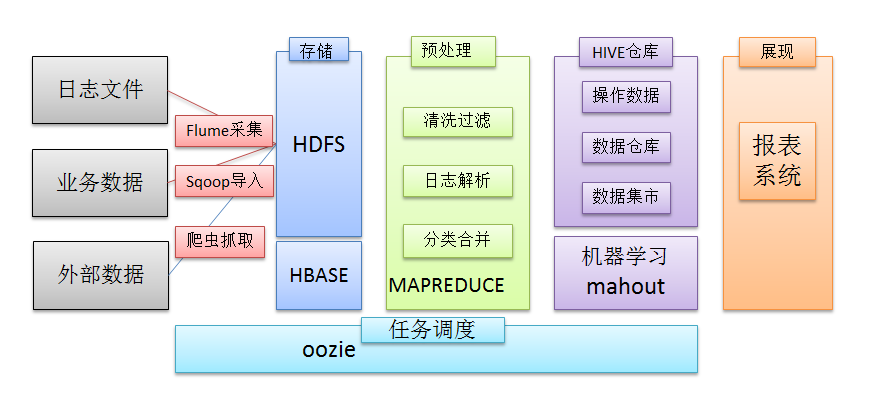
在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架,如图所示:
2. Flume介绍
2.1. 概述
- Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
- Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中
- 一般的采集需求,通过对flume的简单配置即可实现
- Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
2.2. 运行机制
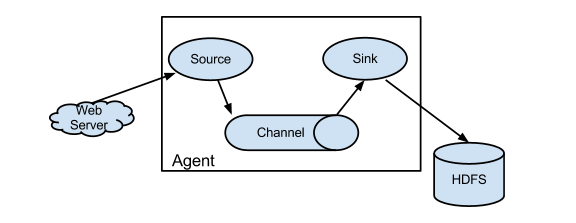
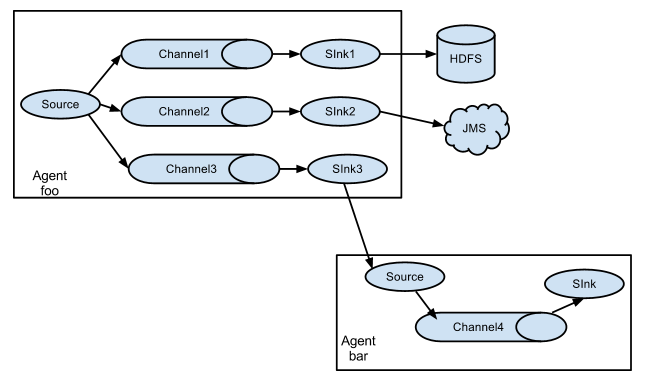
1、 Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
2、 每一个agent相当于一个数据传递员,内部有三个组件:
注意:Source 到 Channel 到 Sink之间传递数据的形式是Event事件;Event事件是一个数据流单元。
a) Source:采集源,用于跟数据源对接,以获取数据
b) Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
c)Channel:angent内部的数据传输通道,用于从source将数据传递到sink
3. Flume采集系统结构图
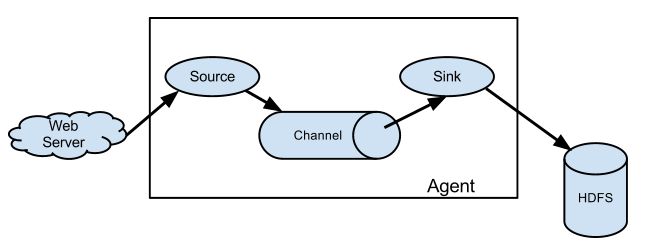
3.1. 简单结构
单个agent采集数据
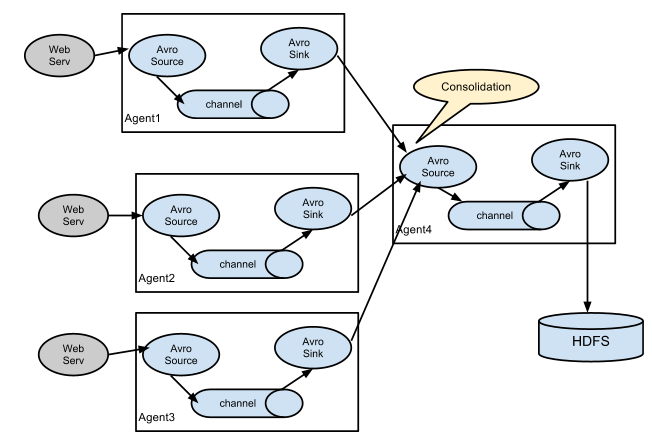
3.2. 复杂结构
多级agent之间串联
4. Flume的安装部署
4.1. 软件部署
[yun@mini01 software]$ pwd
/app/software
[yun@mini01 software]$ tar xf apache-flume-1.8.-bin.tar.gz
[yun@mini01 software]$ mv apache-flume-1.8.-bin /app/flume-1.8.
[yun@mini01 software]$ cd /app/
[yun@mini01 ~]$ ln -s flume-1.8. flume # 建立软连接
[yun@mini01 ~]$ ll
total
lrwxrwxrwx yun yun Jul : flume -> flume-1.8.
drwxrwxr-x yun yun Jul : flume-1.8.
………………
4.2. 环境变量
[root@mini01 profile.d]# pwd
/etc/profile.d
[root@mini01 profile.d]# cat flume.sh
export FLUME_HOME="/app/flume"
export PATH=$FLUME_HOME/bin:$PATH
[root@mini01 profile.d]# logout
[yun@mini01 ~]$ source /etc/profile # 环境变量生效
5. 采集案例
5.1. 简单案例——从网络端口接收数据下沉到logger
配置文件
[yun@mini01 conf]$ pwd
/app/flume/conf
[yun@mini01 conf]$ ll
total
-rw-r--r-- yun yun Sep flume-conf.properties.template
-rw-r--r-- yun yun Sep flume-env.ps1.template
-rw-r--r-- yun yun Sep flume-env.sh.template
-rw-r--r-- yun yun Sep log4j.properties
-rw-rw-r-- yun yun Jul : netcat-logger.conf
[yun@mini01 conf]$ cat netcat-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port =
# bind = localhost 绑定的是本地端口 # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
#下沉的时候是一批一批的, 下沉的时候是一个个eventChannel参数解释:
#capacity:默认该通道中最大的可以存储的event数量
#trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume启动
[yun@mini01 conf]$ pwd
/app/flume/conf
# 其中--conf-file 指定的配置文件可以为相对路径也可以是绝对路径
[yun@mini01 conf]$ flume-ng agent --conf conf --conf-file netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
………………
// :: INFO node.Application: Starting Channel c1
// :: INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
// :: INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: c1 started
// :: INFO node.Application: Starting Sink k1
// :: INFO node.Application: Starting Source r1
// :: INFO source.NetcatSource: Source starting
// :: INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:]
source端的Telnet输入
[yun@mini01 ~]$ telnet localhost
Trying ::...
telnet: connect to address ::: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'. OK OK
334334634geg
OK
gwegweg
OK
^]
telnet> quit
Connection closed.
当在Telnet端输入,logger显示
// :: INFO sink.LoggerSink: Event: { headers:{} body: 0D . }
// :: INFO sink.LoggerSink: Event: { headers:{} body: 0D . }
// :: INFO sink.LoggerSink: Event: { headers:{} body: 0D 334334634geg. }
// :: INFO sink.LoggerSink: Event: { headers:{} body: 0D gwegweg. }
5.2. 监视文件夹——下沉到logger
配置文件
[yun@mini01 conf]$ pwd
/app/flume/conf
[yun@mini01 conf]$ ll
total
-rw-r--r-- yun yun Sep flume-conf.properties.template
-rw-r--r-- yun yun Sep flume-env.ps1.template
-rw-r--r-- yun yun Sep flume-env.sh.template
-rw-r--r-- yun yun Sep log4j.properties
-rw-rw-r-- yun yun Jul : netcat-logger.conf
-rw-rw-r-- yun yun Jul : spooldir-logger.conf
[yun@mini01 conf]$ cat spooldir-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
#监听目录,spoolDir指定目录, fileHeader要不要给文件加前缀名
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /app/software/flume
a1.sources.r1.fileHeader = true # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume启动
[yun@mini01 conf]$ pwd
/app/flume/conf
[yun@mini01 conf]$ flume-ng agent --conf conf --conf-file spooldir-logger.conf --name a1 -Dflume.root.logger=INFO,console
………………
// :: INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: c1 started
// :: INFO node.Application: Starting Sink k1
// :: INFO node.Application: Starting Source r1
// :: INFO source.SpoolDirectorySource: SpoolDirectorySource source starting with directory: /app/software/flume
// :: INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean.
// :: INFO instrumentation.MonitoredCounterGroup: Component type: SOURCE, name: r1 started
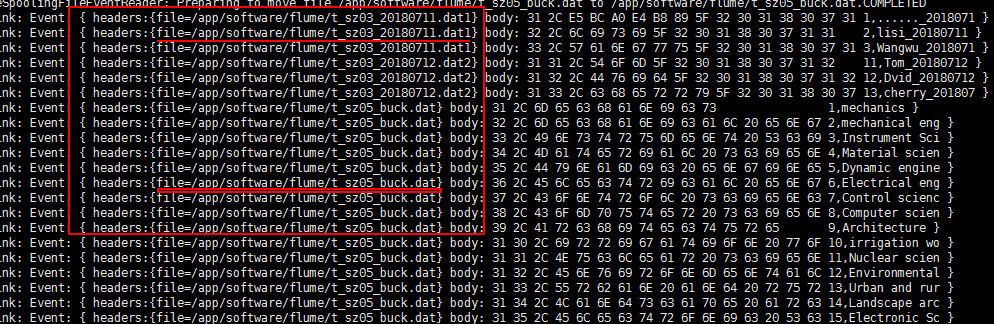
往/app/software/flume目录加入文件
# 原文件目录
[yun@mini01 hive]$ pwd
/app/software/hive
[yun@mini01 hive]$ ll
total
-rw-rw-r-- yun yun Jul : t_sz01.dat
-rw-rw-r-- yun yun Jul : t_sz01.dat2
-rw-rw-r-- yun yun Jul : t_sz02_ext.dat
-rw-rw-r-- yun yun Jul : t_sz03_20180711.dat1
-rw-rw-r-- yun yun Jul : t_sz03_20180711.dat2
-rw-rw-r-- yun yun Jul : t_sz03_20180712.dat1
-rw-rw-r-- yun yun Jul : t_sz03_20180712.dat2
-rw-rw-r-- yun yun Jul : t_sz05_buck.dat
-rw-rw-r-- yun yun Jul : t_sz05_buck.dat.bak
[yun@mini01 hive]$ cp -a t_access_times.dat t_sz01.dat t_sz01.dat2 ../flume/
[yun@mini01 hive]$ cp -a t_sz05_buck.dat t_sz05_buck.dat2 ../flume/
############################################
# 对应的flume目录 注意文件名不能重复,否则flume会报错,也不能是一个目录
[yun@mini01 flume]$ pwd
/app/software/flume
[yun@mini01 flume]$ ll
total
-rw-rw-r-- yun yun Jul : t_access_times.dat.COMPLETED
-rw-rw-r-- yun yun Jul : t_sz01.dat2.COMPLETED
-rw-rw-r-- yun yun Jul : t_sz01.dat.COMPLETED
-rw-rw-r-- yun yun Jul : t_sz05_buck.dat
-rw-rw-r-- yun yun Jul : t_sz05_buck.dat.COMPLETED
有fileHeader配置
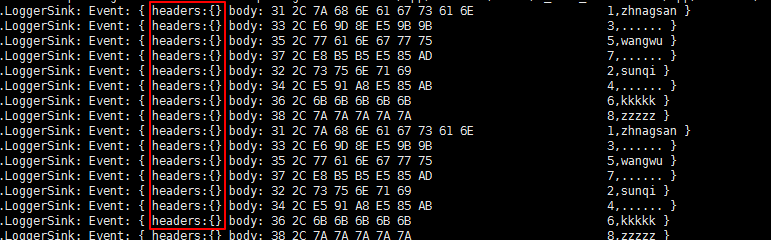
有fileHeader配置
5.3. 用tail命令获取数据,下沉到HDFS
配置文件
[yun@mini01 conf]$ pwd
/app/flume/conf
[yun@mini01 conf]$ ll
total
-rw-r--r-- yun yun Sep flume-conf.properties.template
-rw-r--r-- yun yun Sep flume-env.ps1.template
-rw-r--r-- yun yun Sep flume-env.sh.template
-rw-r--r-- yun yun Sep log4j.properties
-rw-rw-r-- yun yun Jul : netcat-logger.conf
-rw-rw-r-- yun yun Jul : spooldir-logger.conf
-rw-rw-r-- yun yun Jul : tail-hdfs.conf
[yun@mini01 conf]$ cat tail-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /app/webservice/logs/access.log
a1.sources.r1.channels = c1 # Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
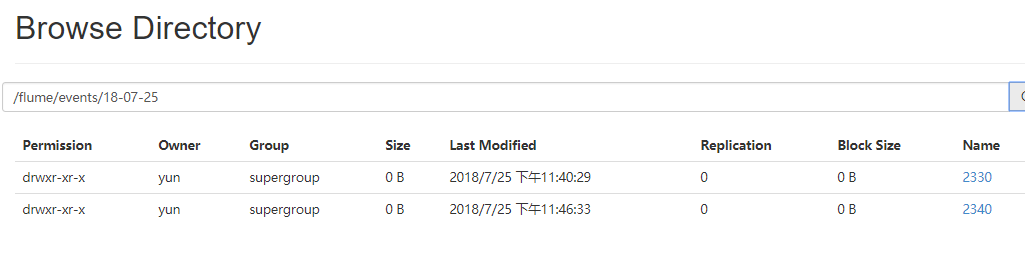
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
# 以下3项表示每隔10分钟切换目录存储
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue =
a1.sinks.k1.hdfs.roundUnit = minute
# 滚动当前文件前等待的秒数
a1.sinks.k1.hdfs.rollInterval =
# 文件大小以字节为单位触发滚动
a1.sinks.k1.hdfs.rollSize =
# 在滚动之前写入文件的事件数
a1.sinks.k1.hdfs.rollCount =
# 在它被刷新到HDFS之前写入文件的事件数量。100个事件为一个批次
a1.sinks.k1.hdfs.batchSize =
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume启动
[yun@mini01 conf]$ flume-ng agent -c conf -f tail-hdfs.conf -n a1
启动jar包打印日志
[yun@mini01 webservice]$ pwd
/app/webservice
[yun@mini01 webservice]$ java -jar testlog.jar &
可参见:Hadoop2.7.6_02_HDFS常用操作 ----- 3.3. web日志模拟
浏览器查看flume下沉的数据
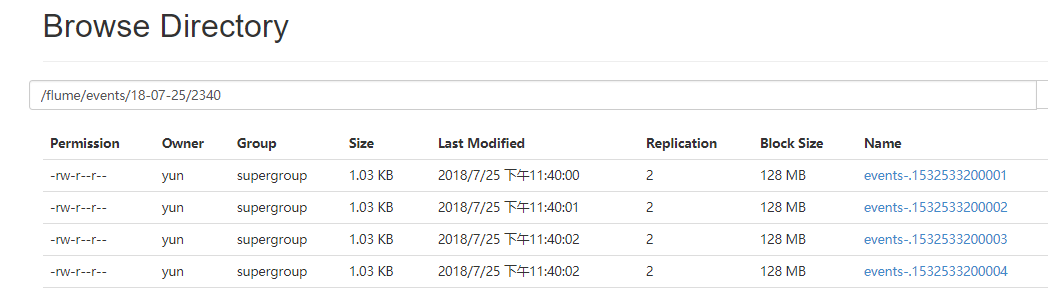
5.4. 级联下沉到HDFS
由mini01 的flume发送数据到mini02的flume,然后由mini02的flume下沉到HDFS。
其中mini02的flume安装过程略。
配置文件mini01
[yun@mini01 conf]$ pwd
/app/flume/conf
[yun@mini01 conf]$ ll
total
-rw-r--r-- yun yun Sep flume-conf.properties.template
-rw-r--r-- yun yun Sep flume-env.ps1.template
-rw-r--r-- yun yun Sep flume-env.sh.template
-rw-r--r-- yun yun Sep log4j.properties
-rw-rw-r-- yun yun Jul : netcat-logger.conf
-rw-rw-r-- yun yun Jul : spooldir-logger.conf
-rw-rw-r-- yun yun Jul : tail-avro-avro-logger.conf
-rw-rw-r-- yun yun Jul : tail-hdfs.conf
[yun@mini01 conf]$ cat tail-avro-avro-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /app/webservice/logs/access.log
a1.sources.r1.channels = c1 # Describe the sink
#绑定的不是本机, 是另外一台机器的服务地址, sink端的avro是一个发送端, avro的客户端, 往mini02这个机器上发
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = mini02
a1.sinks.k1.port =
a1.sinks.k1.batch-size = # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置文件mini02
[yun@mini02 conf]$ pwd
/app/flume/conf
[yun@mini02 conf]$ ll
total
-rw-rw-r-- yun yun Jul : avro-hdfs.conf
-rw-r--r-- yun yun Sep flume-conf.properties.template
-rw-r--r-- yun yun Sep flume-env.ps1.template
-rw-r--r-- yun yun Sep flume-env.sh.template
-rw-r--r-- yun yun Sep log4j.properties
[yun@mini02 conf]$ cat avro-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
#source中的avro组件是接收者服务, 绑定本机
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = # Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/new-events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
# 以下3项表示每隔10分钟切换目录存储
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue =
a1.sinks.k1.hdfs.roundUnit = minute
# 滚动当前文件前等待的秒数
a1.sinks.k1.hdfs.rollInterval =
# 文件大小以字节为单位触发滚动
a1.sinks.k1.hdfs.rollSize =
# 在滚动之前写入文件的事件数
a1.sinks.k1.hdfs.rollCount =
# 在它被刷新到HDFS之前写入文件的事件数量,每批次事件最大数
a1.sinks.k1.hdfs.batchSize =
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
# 启动mini02的flume # 启动mini01的flume
启动jar包打印日志
[yun@mini01 webservice]$ pwd
/app/webservice
[yun@mini01 webservice]$ java -jar testlog.jar &
可参见:Hadoop2.7.6_02_HDFS常用操作 ----- 3.3. web日志模拟
浏览器查看flume下沉的数据
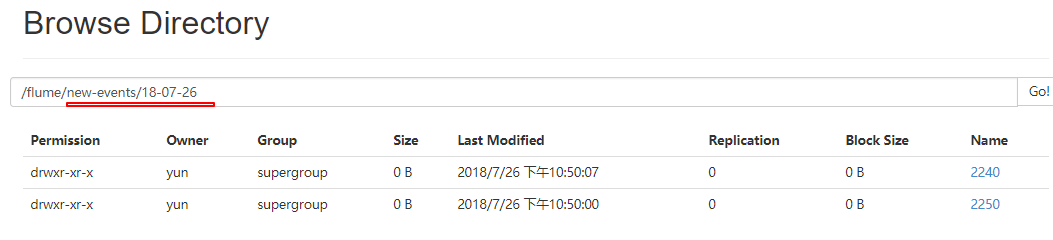
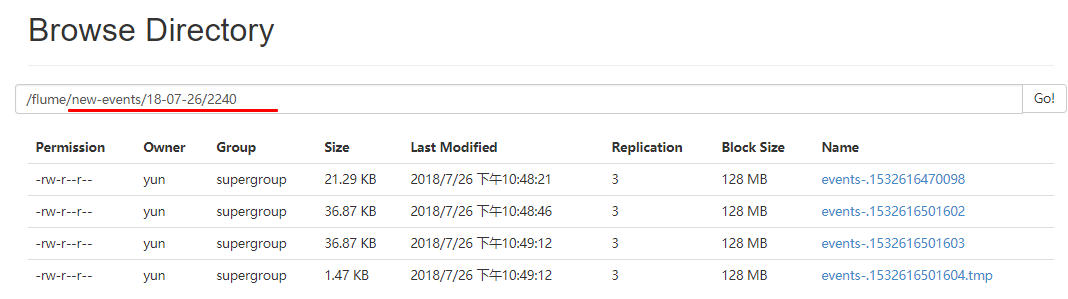
6. 更多source和sink组件
Flume支持众多的source和sink类型,详细手册可参考官方文档
Flume-1.8.0_部署与常用案例的更多相关文章
- css书写规范 & 页面布局规范 &常用案例经验总结
CSS 属性书写顺序(重点) 建议遵循以下顺序: 布局定位属性:display / position / float / clear / visibility / overflow(建议 displa ...
- Hadoop生态圈-phoenix完全分布式部署以及常用命令介绍
Hadoop生态圈-phoenix完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. phoenix只是一个插件,我们可以用hive给hbase套上一个JDBC壳,但是你 ...
- flume+kafka+storm单机部署
flume-1.6.0 kafka0.9.0.0 storm0.9.6 一.部署flume 1.解压 tar -xzvf apache-flume-1.6.0-bin.tar.gz -C ../app ...
- Ansible安装部署以及常用模块详解
一. Ansible 介绍Ansible是一个配置管理系统configuration management system, python 语言是运维人员必须会的语言, ansible 是一个基于py ...
- ansible环境部署及常用模块总结 - 运维笔记
一. Ansible 介绍Ansible是一个配置管理系统configuration management system, python 语言是运维人员必须会的语言, ansible 是一个基于py ...
- Ansible安装部署及常用模块详解
Ansible命令使用 Ansible语法使用ansible <pattern_goes_here> -m <module_name> -a <arguments> ...
- Dom操作的常用案例实现
本文介绍几个Dom操作的几个常用的案例.虽然现在各种web框架层出不穷,也很方便.但是了解最基本的实现方法对我们开发还是有很大的帮助的: 1.图片滚动案例 1.1 效果如下: 1.2 代码如下: ...
- Liunx 部署环境常用命令
在Linux环境中部署web项目中常用到一些命令,在此记录已做备用: 1. 查看当前工作目录: pwd [选项] 常用参数: pwd -P 显示出实际路径,而非使用连接(link)路径. 2. 列出目 ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
随机推荐
- [java核心技术01]__继承与多态、重载与重写、抽象类与接口
前言 前面简单学习了面向对象的知识,知道了其两个重要的特性,继承与多态,今天就围绕着面向对象的这两个特性,将继承与多态及相关的几个几个定义重载与重写,抽象类与接口的相关知识具体学习一下. 类的继承 关 ...
- 【awesome-dotnet-core-learning】(3)-Bogus-假数据生成器
[awesome-dotnet-core-learning](3)-Bogus-假数据生成器 简介 Bogus一个简单而强大的假数据生成器,用于C#,F#和VB.NET.从著名的faker.js移植过 ...
- mysql存储引擎选择(转)
MySQL 的存储引擎可能是所有关系型数据库产品中最具有特色的了,不仅可以同时使用多种存储引擎,而且每种存储引擎和MySQL之间使用插件方式这种非常松的耦合关系.由于各存储引擎功能特性差异较大,这篇文 ...
- Tomcat启动时项目重复加载的问题
最近在项目开发测试的时候,发现Tomcat启动时项目重复加载,导致资源初始化两次的问题 导致该问题的原因: 如下图:在Eclipse中将Server Locations设置为“Use Tomcat ...
- php手撸轻量级开发(二)框架加载
先上图,有图有真相 1. 加载index文件 index文件是整个项目的唯一入口,任何请求进入项目都是走的index,只是带的参数不一样,然后再在index文件里加载其他文件,相当于把其他文件整个复制 ...
- scikit-learn入门导航
scikit-learn是一个非常强大的机器学习库, 提供了很多常见机器学习算法的实现. scikit-learn可以通过pip进行安装: pip install -U scikit-learn 不过 ...
- 微服务学习二:springboot与swagger2的集成
现在测试都提倡自动化测试,那我们作为后台的开发人员,也得进步下啊,以前用postman来测试后台接口,那个麻烦啊,一个字母输错就导致测试失败,现在swagger的出现可谓是拯救了这些开发人员,便捷之处 ...
- [转]【Angular4】基础(一):脚手架 Angular CLI
本文转自:https://blog.csdn.net/u013451157/article/details/79444495 版权声明:本文为博主原创文章,未经博主允许不得转载. https://bl ...
- 获取微信的access_tokey,处理json格式的数据
#region 获取微信凭证 public string GetAccessToken(string wechat_id) { string accessToken = ""; D ...
- 解决System.Data.SqlClient.SqlException (0x80131904): Timeout 时间已到的问题
这段时间写Android和IOS服务时 sql数据库查询有数据正常,没数据总是报异常:System.Data.SqlClient.SqlException (0x80131904): Timeout ...