机器学习:SVM(scikit-learn 中的 RBF、RBF 中的超参数 γ)
一、高斯核函数、高斯函数

- μ:期望值,均值,样本平均数;(决定告诉函数中心轴的位置:x = μ)
- σ2:方差;(度量随机样本和平均值之间的偏离程度:
 ,
, 为总体方差,
为总体方差,  为变量,
为变量,  为总体均值,
为总体均值,  为总体例数)
为总体例数)
- 实际工作中,总体均数难以得到时,应用样本统计量代替总体参数,经校正后,样本方差计算公式:S^2= ∑(X-
 ) ^2 / (n-1),S^2为样本方差,X为变量, 为样本均值,n为样本例数。
) ^2 / (n-1),S^2为样本方差,X为变量, 为样本均值,n为样本例数。
- σ:标准差;(反应样本数据分布的情况:σ 越小高斯分布越窄,样本分布越集中;σ 越大高斯分布越宽,样本分布越分散)
- γ = 1 / (2σ2):γ 越大高斯分布越窄,样本分布越集中;γ 越小高斯分布越宽,样本分布越密集;
二、scikit-learn 中的 RBF 核
1)格式
from sklearn.svm import SVC svc = SVC(kernel='rbf', gamma=1.0)
# 直接设定参数 γ = 1.0;
2)模拟数据集、导入绘图函数、设计管道
- 此处不做考察泛化能力,只查看对训练数据集的分类的决策边界,不需要进行 train_test_split;
模拟数据集
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets X, y = datasets.make_moons(noise=0.15, random_state=666) plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()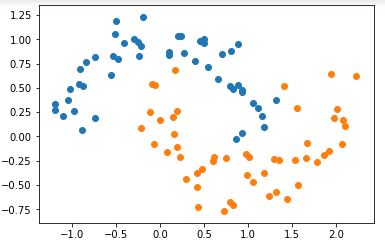
导入绘图函数
def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)设计管道
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler', StandardScaler()),
('svc', SVC(kernel='rbf', gamma=gamma))
])
3)调整参数 γ,得到不同的决策边界
- γ == 0.1
svc_gamma_01 = RBFKernelSVC(gamma=0.1)
svc_gamma_01.fit(X, y) plot_decision_boundary(svc_gamma_01, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()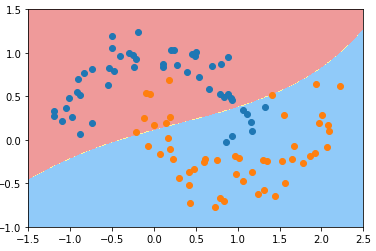
γ == 0.5
svc_gamma_05 = RBFKernelSVC(gamma=0.5)
svc_gamma_05.fit(X, y) plot_decision_boundary(svc_gamma_05, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()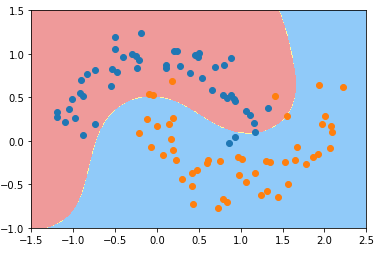
γ == 1
svc_gamma_1 = RBFKernelSVC(gamma=1.0)
svc_gamma_1.fit(X, y) plot_decision_boundary(svc_gamma_1, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()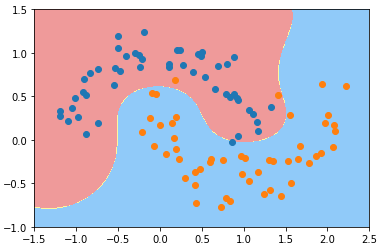
γ == 10
svc_gamma_10 = RBFKernelSVC(gamma=10)
svc_gamma_10.fit(X, y) plot_decision_boundary(svc_gamma_10, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()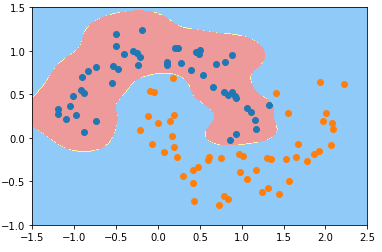
γ == 100
svc_gamma_100 = RBFKernelSVC(gamma=100)
svc_gamma_100.fit(X, y) plot_decision_boundary(svc_gamma_100, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
4)分析
- 随着参数 γ 从小到大变化,模型经历:欠拟合——优——欠拟合;
- γ == 100 时:
- 现象:每一个蓝色的样本周围都形成了一个“钟形”的图案,蓝色的样本点是“钟形”图案的顶部;
- 原因:γ 的取值过大,样本分布形成的“钟形”图案比较窄,模型过拟合;
- 决策边界几何意义:只有在“钟形”图案内分布的样本,才被判定为蓝色类型;否则都判定为黄山类型;
- γ == 10 时,γ 值减小,样本分布规律的“钟形”图案变宽,不同样本的“钟形”图案区域交叉一起,形成蓝色类型的样本的分布区域;
- 超参数 γ 值越小模型复杂度越低,γ 值越大模型复杂度越高;
机器学习:SVM(scikit-learn 中的 RBF、RBF 中的超参数 γ)的更多相关文章
- 【深度学习篇】--神经网络中的调优一,超参数调优和Early_Stopping
一.前述 调优对于模型训练速度,准确率方面至关重要,所以本文对神经网络中的调优做一个总结. 二.神经网络超参数调优 1.适当调整隐藏层数对于许多问题,你可以开始只用一个隐藏层,就可以获得不错的结果,比 ...
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- 机器学习算法中如何选取超参数:学习速率、正则项系数、minibatch size
机器学习算法中如何选取超参数:学习速率.正则项系数.minibatch size 本文是<Neural networks and deep learning>概览 中第三章的一部分,讲机器 ...
- 机器学习-kNN-寻找最好的超参数
一 .超参数和模型参数 超参数:在算法运行前需要决定的参数 模型参数:算法运行过程中学习的参数 - kNN算法没有模型参数- kNN算法中的k是典型的超参数 寻找好的超参数 领域知识 经验数值 实验搜 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- 机器学习:SVM(核函数、高斯核函数RBF)
一.核函数(Kernel Function) 1)格式 K(x, y):表示样本 x 和 y,添加多项式特征得到新的样本 x'.y',K(x, y) 就是返回新的样本经过计算得到的值: 在 SVM 类 ...
- 高斯RBF核函数中Sigma取值和SVM分离面的影响
1:高斯RBF核函数的定义 k(x) = exp(-x^2/(2×sigma)) 在MATLAB中输入一下代码:ezsurf('exp(-x^2/(2*sigma^2))'); 在GOOGLE中输入“ ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
随机推荐
- IntelliJ Idea 快捷键精选
Alt+Enter,导入包,自动修正Ctrl+F,查找文本Alt+Up/Down,上/下移一行:在方法间快速移动定位:与光标位置有关Alt+Shift+Up,多次up可选中一行Ctrl+X,剪切行Ct ...
- tomcat 正常启动但不能访问
Eclipse中的Tomcat可以正常启动,不过发布项目之后,无法访问,包括http://localhost:8080/的小猫页面也无法访问到,报404错误.这是因为Eclipse所指定的Server ...
- iptable防火墙面试题
第1章 (一)基础口试题 1.1 详述 iptales 工作流程以及规则过滤顺序? 1.防火墙是一层层过滤的.实际是按照配置规则的顺序从上到下,从前到后进行过滤的. 2.如果匹配上了规则,即明确表明是 ...
- jsp中的basePath和path(绝对路径 相对路径)
在JSP中的如果使用 "相对路径" 则有 可能会出现问题. 因为 网页中的 "相对路径" , 他是相对于 "URL请求的地址" 去寻找资源. ...
- json前后台传输,以及乱码中文问题探讨
背景介绍: 我现在的工作是做传统项目开发,没有用到框架.最近在做项目时,经常需要使用ajax从后台拿数据到前台,是json格式的.先说下我在项目中遇到的问题吧,前台拿到了数据,需要将其转化为对象,我使 ...
- PAT1023. Have Fun with Numbers (20)
#include <iostream> #include <map> #include <algorithm> using namespace std; strin ...
- HDU 5925 离散化
东北赛的一道二等奖题 当时学长想了一个dfs的解法并且通过了 那时自己也有一个bfs的解法没有拿出来 一直没有机会和时ji间xing来验证对错 昨天和队友谈离散化的时候想到了 于是用当时的思路做了一下 ...
- bzoj 1087 [SCOI2005]互不侵犯King 状态压缩dp
1087: [SCOI2005]互不侵犯King Time Limit: 10 Sec Memory Limit: 162 MB[Submit][Status][Discuss] Descripti ...
- nova Evacuate
作用:当一个 node down 掉后,在新的 node 上根据其 DB 中保存的信息重新 build down node 上虚机.这个往往在虚机 HA 方案中用到.它尽可能地将原来的虚机在新的主机上 ...
- PyCharm 的初始设置1
PyCharm 的初始设置 PyCharm 的官方网站地址是:https://www.jetbrains.com/pycharm/ 01. 恢复 PyCharm 的初始设置 PyCharm 的 配置信 ...