机器学习:SVM(scikit-learn 中的 RBF、RBF 中的超参数 γ)
一、高斯核函数、高斯函数

- μ:期望值,均值,样本平均数;(决定告诉函数中心轴的位置:x = μ)
- σ2:方差;(度量随机样本和平均值之间的偏离程度:
 ,
, 为总体方差,
为总体方差,  为变量,
为变量,  为总体均值,
为总体均值,  为总体例数)
为总体例数)
- 实际工作中,总体均数难以得到时,应用样本统计量代替总体参数,经校正后,样本方差计算公式:S^2= ∑(X-
 ) ^2 / (n-1),S^2为样本方差,X为变量, 为样本均值,n为样本例数。
) ^2 / (n-1),S^2为样本方差,X为变量, 为样本均值,n为样本例数。
- σ:标准差;(反应样本数据分布的情况:σ 越小高斯分布越窄,样本分布越集中;σ 越大高斯分布越宽,样本分布越分散)
- γ = 1 / (2σ2):γ 越大高斯分布越窄,样本分布越集中;γ 越小高斯分布越宽,样本分布越密集;
二、scikit-learn 中的 RBF 核
1)格式
from sklearn.svm import SVC svc = SVC(kernel='rbf', gamma=1.0)
# 直接设定参数 γ = 1.0;
2)模拟数据集、导入绘图函数、设计管道
- 此处不做考察泛化能力,只查看对训练数据集的分类的决策边界,不需要进行 train_test_split;
模拟数据集
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets X, y = datasets.make_moons(noise=0.15, random_state=666) plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()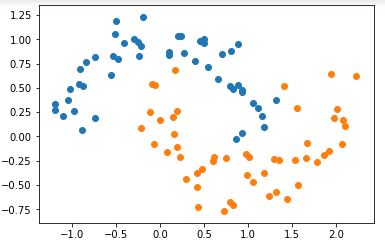
导入绘图函数
def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)设计管道
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler', StandardScaler()),
('svc', SVC(kernel='rbf', gamma=gamma))
])
3)调整参数 γ,得到不同的决策边界
- γ == 0.1
svc_gamma_01 = RBFKernelSVC(gamma=0.1)
svc_gamma_01.fit(X, y) plot_decision_boundary(svc_gamma_01, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()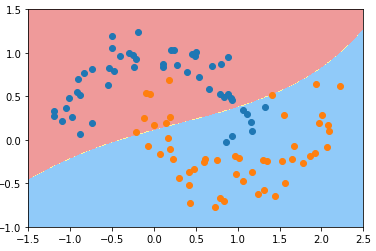
γ == 0.5
svc_gamma_05 = RBFKernelSVC(gamma=0.5)
svc_gamma_05.fit(X, y) plot_decision_boundary(svc_gamma_05, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()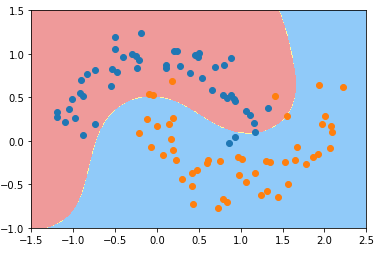
γ == 1
svc_gamma_1 = RBFKernelSVC(gamma=1.0)
svc_gamma_1.fit(X, y) plot_decision_boundary(svc_gamma_1, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()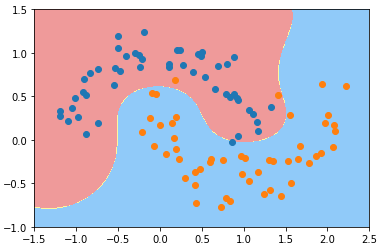
γ == 10
svc_gamma_10 = RBFKernelSVC(gamma=10)
svc_gamma_10.fit(X, y) plot_decision_boundary(svc_gamma_10, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()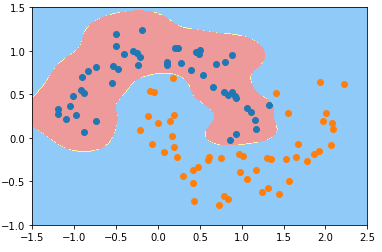
γ == 100
svc_gamma_100 = RBFKernelSVC(gamma=100)
svc_gamma_100.fit(X, y) plot_decision_boundary(svc_gamma_100, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
4)分析
- 随着参数 γ 从小到大变化,模型经历:欠拟合——优——欠拟合;
- γ == 100 时:
- 现象:每一个蓝色的样本周围都形成了一个“钟形”的图案,蓝色的样本点是“钟形”图案的顶部;
- 原因:γ 的取值过大,样本分布形成的“钟形”图案比较窄,模型过拟合;
- 决策边界几何意义:只有在“钟形”图案内分布的样本,才被判定为蓝色类型;否则都判定为黄山类型;
- γ == 10 时,γ 值减小,样本分布规律的“钟形”图案变宽,不同样本的“钟形”图案区域交叉一起,形成蓝色类型的样本的分布区域;
- 超参数 γ 值越小模型复杂度越低,γ 值越大模型复杂度越高;
机器学习:SVM(scikit-learn 中的 RBF、RBF 中的超参数 γ)的更多相关文章
- 【深度学习篇】--神经网络中的调优一,超参数调优和Early_Stopping
一.前述 调优对于模型训练速度,准确率方面至关重要,所以本文对神经网络中的调优做一个总结. 二.神经网络超参数调优 1.适当调整隐藏层数对于许多问题,你可以开始只用一个隐藏层,就可以获得不错的结果,比 ...
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- 机器学习算法中如何选取超参数:学习速率、正则项系数、minibatch size
机器学习算法中如何选取超参数:学习速率.正则项系数.minibatch size 本文是<Neural networks and deep learning>概览 中第三章的一部分,讲机器 ...
- 机器学习-kNN-寻找最好的超参数
一 .超参数和模型参数 超参数:在算法运行前需要决定的参数 模型参数:算法运行过程中学习的参数 - kNN算法没有模型参数- kNN算法中的k是典型的超参数 寻找好的超参数 领域知识 经验数值 实验搜 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- 机器学习:SVM(核函数、高斯核函数RBF)
一.核函数(Kernel Function) 1)格式 K(x, y):表示样本 x 和 y,添加多项式特征得到新的样本 x'.y',K(x, y) 就是返回新的样本经过计算得到的值: 在 SVM 类 ...
- 高斯RBF核函数中Sigma取值和SVM分离面的影响
1:高斯RBF核函数的定义 k(x) = exp(-x^2/(2×sigma)) 在MATLAB中输入一下代码:ezsurf('exp(-x^2/(2*sigma^2))'); 在GOOGLE中输入“ ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
随机推荐
- shell中嵌套执行expect命令实例(利用expect实现自动登录)
expect是 #!/bin/bashpasswd='123456'/usr/bin/expect <<EOFset time 30spawn ssh root@192.168.76.10 ...
- 如何在myEclipse中创建配置文件,比如:XXX.properties
myEclipse是没有直接生成配置文件的方法,除非去配置某些插件. 目前通用的方法是:随便新建一个文件(比如:XXX.xml),然后对该文件重命名,改成XXX.properties即可. 很简单有没 ...
- Eclipse安装SVN客户端
在Eclipse中安装SVN客户端有个好处,不用兼容其它操作系统都能保持一致的操作.比如再Linux下SVN客户端软件体验相对较差,但是基于命令行的操作却在Linux下无所不能. 一.通过在线安装 地 ...
- QT 事件处理 KeyPressEvent 和 定时器时间 Timer
1. 按键事件响应, 两种方法,一种直接处理Event,过滤出KeyPress,另一种直接处理KeyPressEvent. bool Dialog::event(QEvent *e) { if( e- ...
- Don't add unneeded context不要加不需要的文本
- Spring Boot入门——tomcat配置
1.通过配置文件配置 server.port = 8080 2.通过程序配置 import org.springframework.boot.SpringApplication; import org ...
- 详解 Android 通信
详解 Android 通信 :http://www.androidchina.net/5028.html
- tableau join 与格式问题
一开始我没有找到它的join 方法.其实应该是编辑相应的join关系.选择数据源,选择字段.数据源是可以选择的. 剩下的计算问题,要再弄下.不好说,这个其实烦了我很久了. 高级选项,扩展最大行数.即可 ...
- 条款51:编写new以及delete的时候需要固守常规
C++中delete一个指针之后,只是回收指针指向位置的空间,而指针本身的值不变.你需要手工将其赋值为NULL.注意的一点是delete NULL指针的时候不会有任何的事情发生 小结: o ...
- nyoj-158-省赛来了(组合数)
题目链接 /* Name:nyoj-158-省赛来了 Copyright: Author: Date: 2018/4/25 17:07:22 Description: 暴力,秒天秒地 */ #incl ...