物体检测丨浅析One stage detector「YOLOv1、v2、v3、SSD」
引言
之前做object detection用到的都是two stage,one stage如YOLO、SSD很少接触,这里开一篇blog简单回顾该系列的发展。很抱歉,我本人只能是蜻蜓点水,很多细节也没有弄清楚。有需求的朋友请深入论文和代码,我在末尾也列出了很多优秀的参考文章。
YOLOv1
You Only Look Once: Unified, Real-Time Object Detection
核心思想
- 用一个CNN实现end-to-end,将目标检测作为回归问题解决。

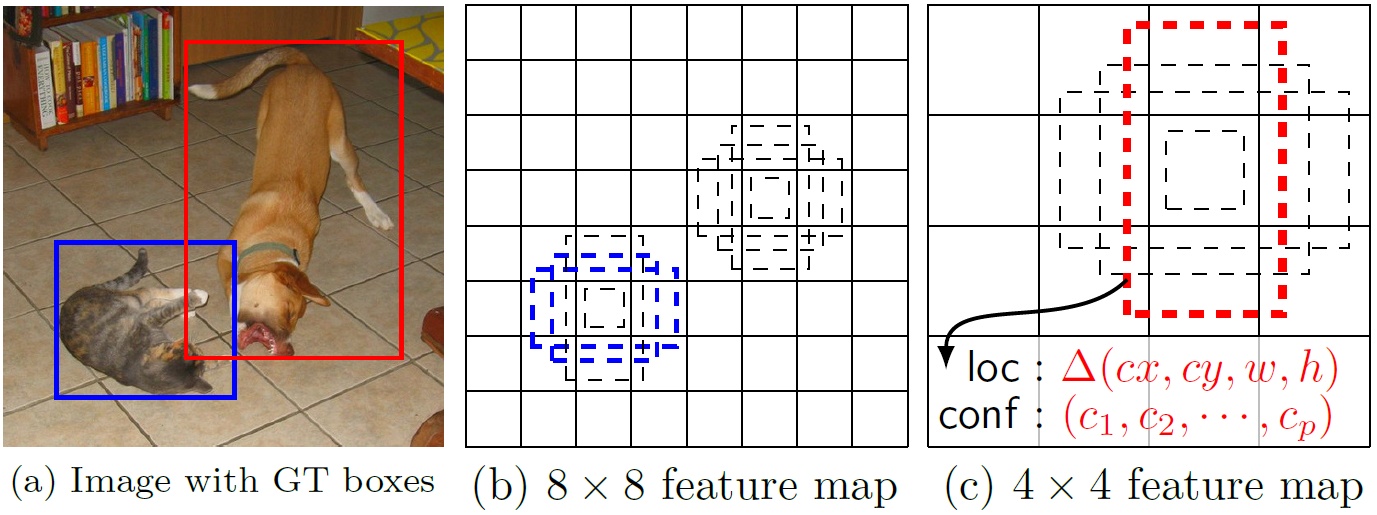
将输入图片分割为\(S\times S\)网格,如果物体的中心落入网格中央,这个网格将负责检测这个物体。因此网络学会了去预测中心落在该网格中的物体。
每个网格预测\(B\)个bounding boxes和confidence scores。confidence scores包含两方面:
- 这个boundingbox包含物体的可能性\(Pr(Object)\):bb包含物体时\(Pr(Object)=1\)否则为0。
- 这个boundingbox的准确度\(IOU^{truth}_{pred}\):pred和gt的IoU。
因此,confidence scores可定义为$Pr(Object)*IoU^{truth}_{pred} $
每个bbox包含5个predictions:\(x,y,w,h和confidence\):\((x,y)\)表示bbox中心坐标,\(h,w\)表示bbox长宽,\(confidence\)表示pred和gt box的IoU。
每个网格预测\(C\)个类别概率\(Pr(Class_i|Object)\),表示该网格负责预测的边界框目标属于各类的概率。我们不考虑box的数量即\(B\)。
测试阶段我们将类别概率和confidence score相乘,得每个box的类特定confidence score:
\[Pr(Class_i|Object)*Pr(Object)*IoU^{truth}_{pred}=Pr(Class_i)*IoU^{truth}_{pred}\]
表示box中类别出现的概率和预测box与目标的拟合程度。
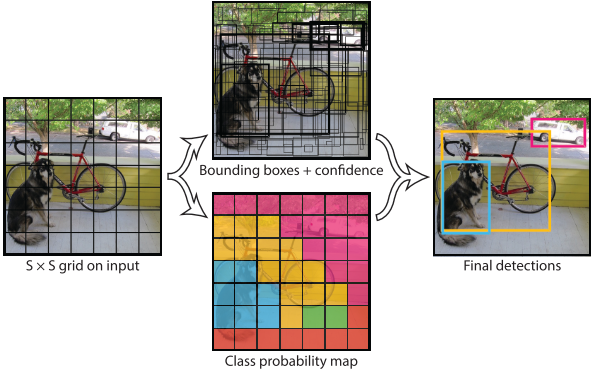
将图片分解为$S\times S \(个gird,每个grid预测\)B\(个bbox,confidence和\)C\(个类概率,预测值为\)S\times S \times (B*5+C)$
网络架构

网络结构参考GooLeNet,包含24个卷积层和2个激活层,卷积层使用1x1卷积降维然后跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU:\(max(x,0.1x)\),最后一层采用线性激活层。
网络输出维度为30(\(B=2\)),前20个元素是类别概率值,然后2个是边界框置信度,最后8个是bbox的\((x,y,w,h)\)。
- Loss:YOLO把分类问题转化为回归问题
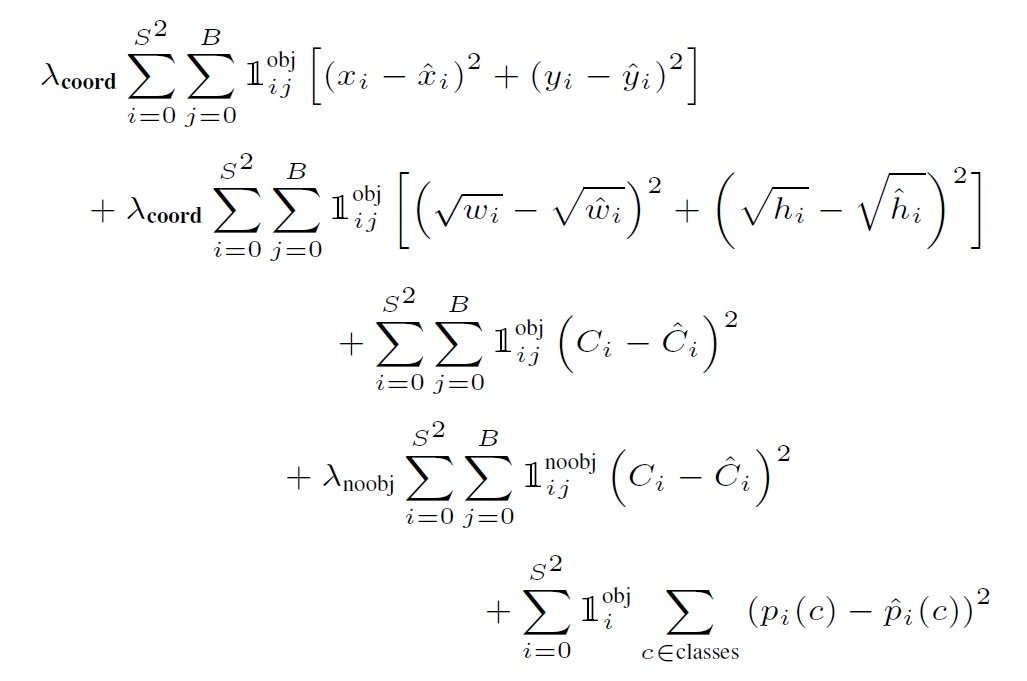
第一项是bbox中心坐标误差项;第二项是bbox高与宽误差项;
第三项是包含目标bbox置信度误差项;第四项是不包含目标bbox置信度误差项;
最后一项是包含目标的grid分类误差项。
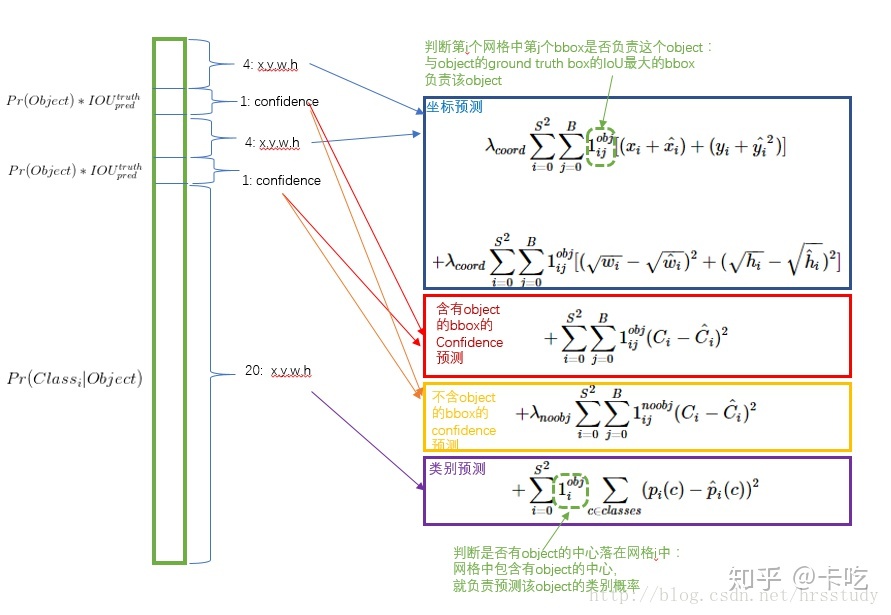
将Loss对应到predtion张量上:
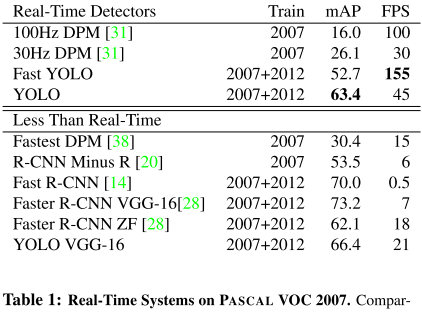
实验结果
SSD
SSD:Single Shot MultiBox Detector
核心思想
速度比YOLO快,精度可以跟Faster RCNN媲美。
采用多尺度特征图用于检测:大特征图检测小目标,小特征图检测大目标。
采用卷积进行检测:与YOLO最后采用全连接层不同,SSD直接采用卷积提取检测结果。
设置先验框:借鉴Faster RCNN中anchor理念,为每个网格设置不同长宽比的anchor,bbox以anchor为基准。
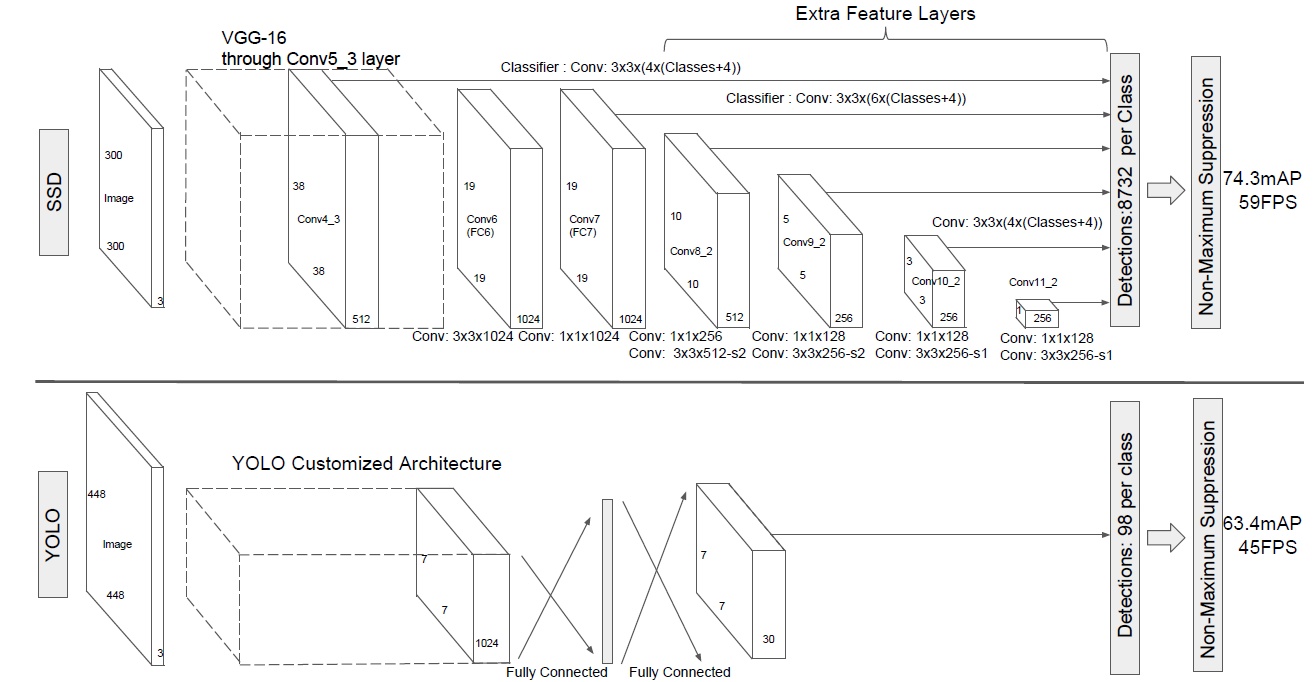
网络架构
在VGG16基础上增加了卷积层获得更多特征图用于检测。
上是SSD,下是YOLO
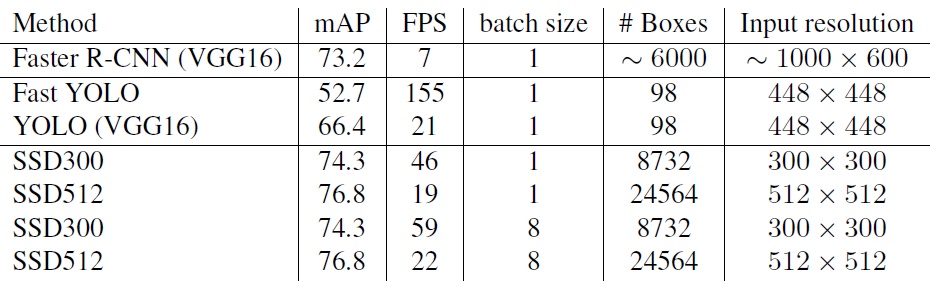
实验结果
YOLOv2
YOLO9000: Better, Faster, Stronger
核心思想
YOLOv1虽然检测速度快,但检测精度不如RCNN,YOLOv1定位不够准确,召回率也低。于是YOLOv2提出了几种改进策略来提升YOLO模型的定位准确度和召回率,并保持检测速度。
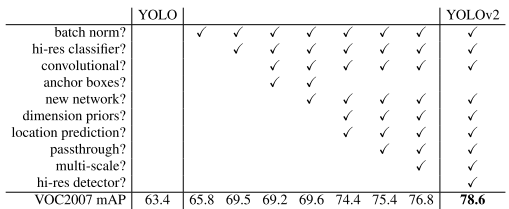
Better
Batch Normalization:加快收敛并起到正则化效果,防止过拟合。
High Resolution Classifier:在ImageNet数据上使用\(448\times448\)输入来finetune。
Convolutional With Anchor Boxes:借鉴Faster R-CNN中RPN的anchor boxes策略,预测offset而不是coordinate。
Dimension Clusters:采用k-means来替代人工选取anchor。并使用下式来度量距离。
\[d(box,centroid)=1-IOU(box, centroid)\]
Direct location prediction:改变了预测bbox的计算公式
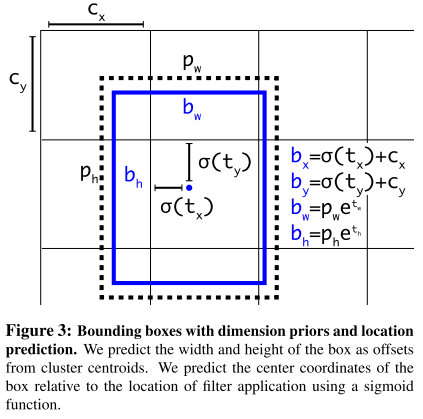
- Fine-Grained Features:小物体需要更精细的特征图。采用passthrough层将高分辨率特征concat低分辨率特征,类似于ResNet。
Multi-Scale Training:每隔10batch,网络随机选择新的图像尺寸。
Faster
- Darknet-19
- Training for classification
- Training for detection
Stronger
- Hierarchical classification
- Dataset combination with WordTree
- Joint classification and detection
网络架构
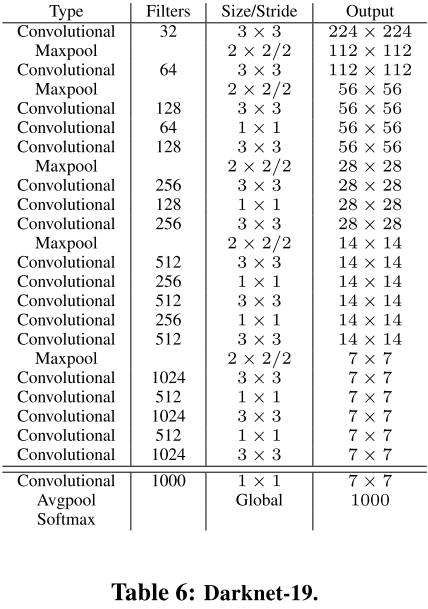
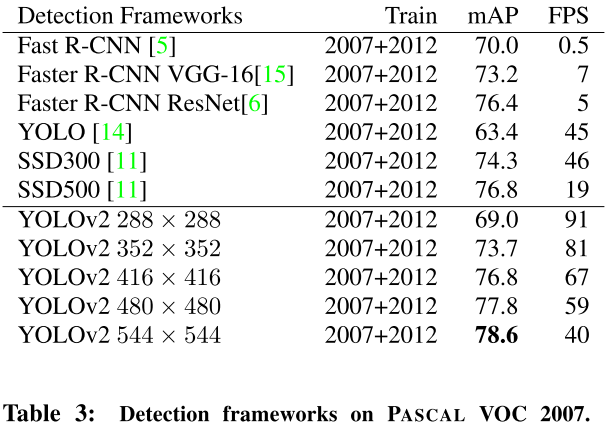
实验结果
YOLOv3
YOLOv3: An Incremental Improvement
核心思想
- Bounding Box Prediction:和v2一样使用聚类来获得anchor并预测bbox坐标。
- Class Prediction:不使用softmax,使用二元交叉熵进行类别预测。
- Predictions Across Scales:跨尺度预测,类似FPN使用3个尺度,预测为\(N\times N\times[3*(4+1+80)]\),4个box offsets、1个obj prediction和80个类prediction。
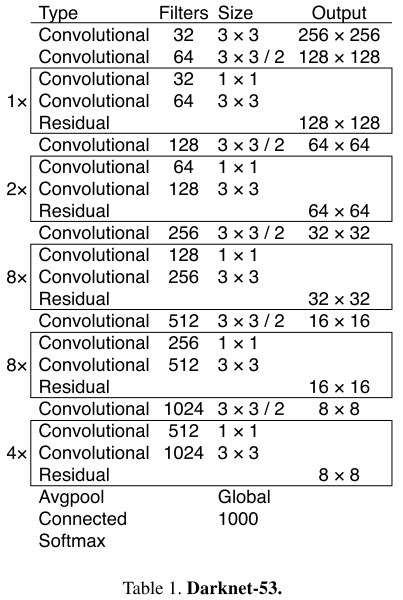
- Feature Extractor:Darknet-53,加入了Residual。
网络架构
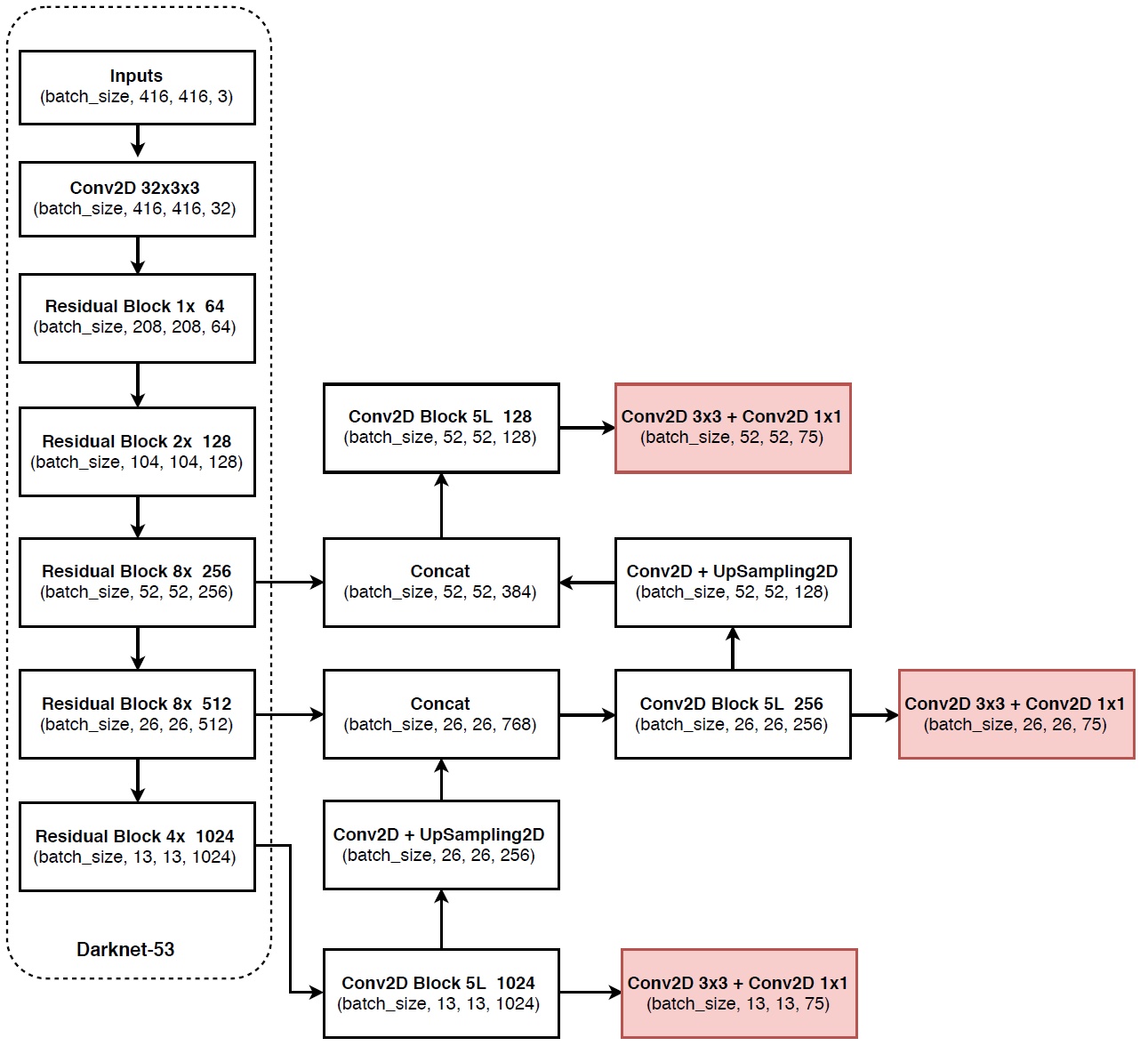
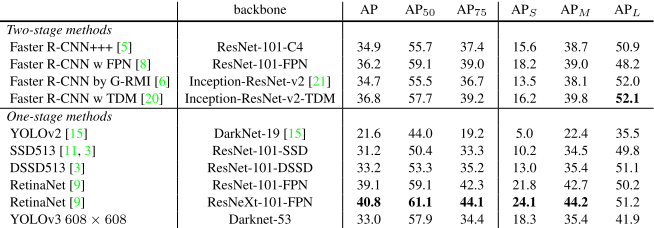
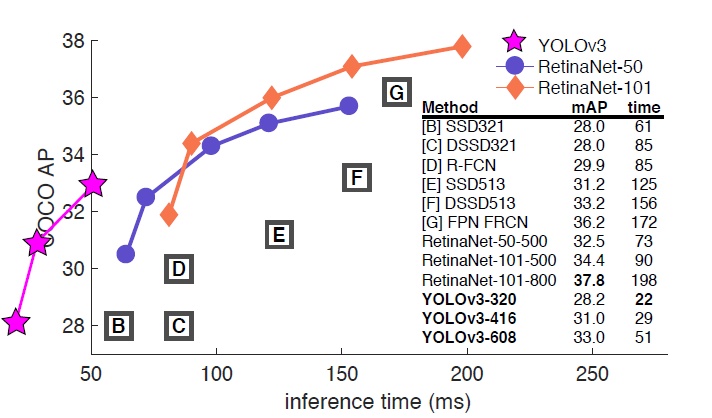
实验结果
参考
- paper
[1]Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[2]Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
[3]Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271.
[4]Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
- blog
What do we learn from single shot object detectors (SSD, YOLOv3), FPN & Focal loss (RetinaNet)?
物体检测丨浅析One stage detector「YOLOv1、v2、v3、SSD」的更多相关文章
- 物体检测丨Faster R-CNN详解
这篇文章把Faster R-CNN的原理和实现阐述得非常清楚,于是我在读的时候顺便把他翻译成了中文,如果有错误的地方请大家指出. 原文:http://www.telesens.co/2018/03/1 ...
- 物体检测丨从R-CNN到Mask R-CNN
这篇blog是我刚入目标检测方向,导师发给我的文献导读,深入浅出总结了object detection two-stage流派Faster R-CNN的发展史,读起来非常有趣.我一直想翻译这篇博客,在 ...
- 图像分类丨ILSVRC历届冠军网络「从AlexNet到SENet」
前言 深度卷积网络极大地推进深度学习各领域的发展,ILSVRC作为最具影响力的竞赛功不可没,促使了许多经典工作.我梳理了ILSVRC分类任务的各届冠军和亚军网络,简单介绍了它们的核心思想.网络架构及其 ...
- 『计算机视觉』物体检测之RefineDet系列
Two Stage 的精度优势 二阶段的分类:二步法的第一步在分类时,正负样本是极不平衡的,导致分类器训练比较困难,这也是一步法效果不如二步法的原因之一,也是focal loss的motivation ...
- 物体检测之FPN及Mask R-CNN
对比目前科研届普遍喜欢把问题搞复杂,通过复杂的算法尽量把审稿人搞蒙从而提高论文的接受率的思想,无论是著名的残差网络还是这篇Mask R-CNN,大神的论文尽量遵循著名的奥卡姆剃刀原理:即在所有能解决问 ...
- [PyImageSearch] Ubuntu16.04 使用深度学习和OpenCV实现物体检测
上一篇博文中讲到如何用OpenCV实现物体分类,但是接下来这篇博文将会告诉你图片中物体的位置具体在哪里. 我们将会知道如何使用OpenCV‘s的dnn模块去加载一个预训练的物体检测网络,它能使得我们将 ...
- OpenCV平面物体检测
平面物体检测 这个教程的目标是学习如何使用 features2d 和 calib3d 模块来检测场景中的已知平面物体. 测试数据: 数据图像文件,比如 “box.png”或者“box_in_scene ...
- cs231n---语义分割 物体定位 物体检测 物体分割
1 语义分割 语义分割是对图像中每个像素作分类,不区分物体,只关心像素.如下: (1)完全的卷积网络架构 处理语义分割问题可以使用下面的模型: 其中我们经过多个卷积层处理,最终输出体的维度是C*H*W ...
- OpenCV学习 物体检测 人脸识别 填充颜色
介绍 OpenCV是开源计算机视觉和机器学习库.包含成千上万优化过的算法.项目地址:http://opencv.org/about.html.官方文档:http://docs.opencv.org/m ...
随机推荐
- SQL SERVER 中的*=和=*
一.* =和= * 是在sql server2000中左连接,右连接的用法相当于left join 和right join,现在sql2005和2008默认是不支持的,可以设置兼容2000或2008 ...
- NEKOGAMES
http://bbs.3dmgame.com/thread-4133434-1-1.html
- spring----IOC注解方式以及AOP
技术分析之Spring框架的IOC功能之注解的方式 Spring框架的IOC之注解方式的快速入门 1. 步骤一:导入注解开发所有需要的jar包 * 引入IOC容器必须的6个jar包 * 多引入一个:S ...
- Angular14 Visual Studio Code作为Angular开发工具常用插件安装、json-server安装与使用、angular/cli安装失败问题、emmet安装
前提准备: 搭建好Angular开发环境 1 安装Visual Studio Code 教程简单,不会的去问度娘 2 安装Chrome浏览器 教程简单,不会的趣闻度娘 3 Visual Studio ...
- 【spring boot logback】日志颜色渲染,使用logback-spring.xml自定义的配置文件后,日志没有颜色了
接着spring boot日志logback解析之后,发现使用logback-spring.xml自定义的配置文件后,日志没有颜色了 怎么办? 官网处理日志链接:https://logback.qos ...
- 太有用了,所以转:Delphi下16进制位图数据转位图
如果我们在Form中拖入一个Image控件,并设置好picture后,Alt+F12就可以看到Form的源代码中已经将图片转成了16进制字符串,如下: object Image1: TImage Le ...
- MQTT协议实现Eclipse Paho学习总结二
一.概述 前一篇博客(MQTT协议实现Eclipse Paho学习总结一) 写了一些MQTT协议相关的一些概述和其实现Eclipse Paho的报文类别,同时对心跳包进行了分析.这篇文章,在不涉及MQ ...
- Java垃圾回收机制(Garbage Collection)
引用博客地址:http://www.cnblogs.com/ywl925/p/3925637.html 以下两篇博客综合描述Java垃圾回收机制 第一篇:说的比较多,但是不详细 http://www. ...
- 【转】如何在eclipse下配置Heritrix
如何配置在eclipse下配置Heritrix 在其他帖子上看到有Eclipse 配置 Heritrix 1.14.4的文章,这里有很多内容是引用自那里.如http://extjs2.javaeye. ...
- Java Script 学习笔记 -- Ajax
AJAX 一 AJAX预备知识:json进阶 1.1 什么是JSON? JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.JSON是用字符串来表示Javas ...