第九篇 数据表设计和保存item到json文件
上节说到Pipeline会拦截item,根据设置的优先级,item会依次经过这些Pipeline,所以可以通过Pipeline来保存文件到json、数据库等等。
下面是自定义json
#存储item到json文件
class JsonWithEncodingPipeline(object):
def __init__(self):
#使用codecs模块来打开文件,可以帮我们解决很多编码问题,下面先初始化打开一个json文件
import codecs
self.file = codecs.open('article.json','w',encoding='utf-8')
#接着创建process_item方法执行item的具体的动作
def process_item(self, item, spider):
import json
#注意ensure_ascii入参设置成False,否则在存储非英文的字符会报错
lines = json.dumps(dict(item),ensure_ascii=False) + "\n"
self.file.write(lines)
#注意最后需要返回item,因为可能后面的Pipeline会调用它
return item
#最后关闭文件
def spider_close(self,spider):
self.file.close()
scrapy内置了json方法:
from scrapy.exporters import JsonItemExporter
除了JsonItemExporter,scrapy提供了多种类型的exporter
class JsonExporterPipeline(object):
#调用scrapy提供的json export导出json文件
def __init__(self):
#打开一个json文件
self.file = open('articleexport.json','wb')
#创建一个exporter实例,入参分别是下面三个,类似前面的自定义导出json
self.exporter = JsonItemExporter(self.file,encoding='utf-8',ensure_ascii=False)
#开始导出
self.exporter.start_exporting()
def close_spider(self,spider):
#完成导出
self.exporter.finish_exporting()
#关闭文件
self.file.close()
#最后也需要调用process_item返回item
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
和自定义json相比,存的文件由【】
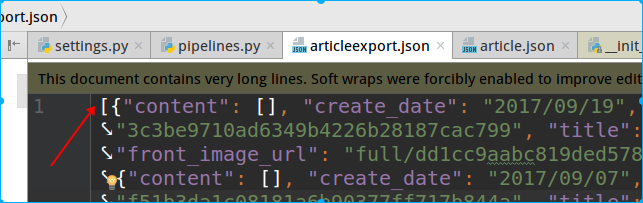
通过源码可以看到如下:
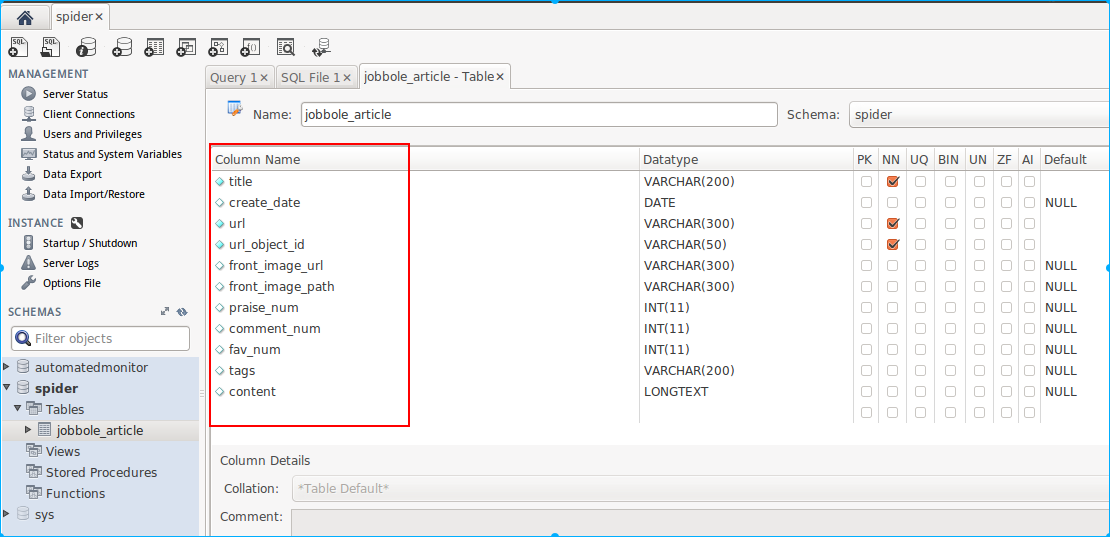
接着是如何把数据存储到mysql,我这开发环境是ubuntu,支持的mysql-client工具不多,免费的就用Mysql Workbench,也可以使用navicat(要收费)
spider要创建的一张表,和ArticleSpider项目里的item一一对应就行。
然后接下来是配置程序连接mysql
这里我使用第三方库pymysql来连接mysql,安装方式很简单,可以使用pycharm内置的包安装,也可以在虚拟环境用pip安装
然后直接在pipline里创建mysql的pipline
import pymysql
class MysqlPipeline(object):
def __init__(self):
"""
初始化,建立mysql连接conn,并创建游标cursor
"""
self.conn = pymysql.connect(
host='localhost',
database='spider',
user='root',
passwd='',
charset='utf8',
use_unicode=True
)
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
#要执行的sql语句
insert_sql = """
insert into jobbole_article(title,create_date,url,url_object_id,
front_image_url,front_image_path,praise_num,comment_num,fav_num,tags,content)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
#使用游标的execute方法执行sql
self.cursor.execute(insert_sql,(item["title"],item['create_date'],
item['url'],item['url_object_id'],
item['front_image_url'],item['front_image_path'],
item['praise_num'],item['comment_num'],item['fav_num'],
item['tags'],item['content']))
#commit提交才能生效
self.conn.commit()
return item
上面的这种mysql存储方式是同步的,也就是execute和commit不执行玩,是不能继续存储数据的,而且明显的scrapy爬取速度会比数据存储到mysql的速度快些,
所以scrapy提供了另外一种异步的数据存储方法(一种异步的容器,还是需要使用pymysql)
首先把mysql的配置连接信息写进setting配置文件,方便后期修改
MYSQL_HOST = "localhost"
MYSQL_DBNAME = 'spider'
MYSQL_USER = "root"
MYSQL_PASSWORD = ""
接着在pipeline中导入scrapy提供的异步的接口:adbapi
from twisted.enterprise import adbapi
完整的pipeline如下:
class MysqlTwistedPipeline(object):
#下面这两个函数完成了在启动spider的时候,就把dbpool传入进来了
def __init__(self,dbpool):
self.dbpool = dbpool #通过下面这种方式,可以很方便的拿到setting配置信息
@classmethod
def from_settings(cls,setting):
dbparms = dict(
host = setting['MYSQL_HOST'],
db = setting['MYSQL_DBNAME'],
user = setting['MYSQL_USER'],
password = setting['MYSQL_PASSWORD'],
charset = 'utf8',
#cursorclass = pymysql.cursors.DictCursor, use_unicode = True, ) #创建连接池,
dbpool = adbapi.ConnectionPool("pymysql",**dbparms) return cls(dbpool) # 使用twisted将mysql插入变成异步执行
def process_item(self, item, spider):
# 指定操作方法和操作的数据
query = self.dbpool.runInteraction(self.do_insert,item)
#处理可能存在的异常,hangdle_error是自定义的方法
query.addErrback(self.handle_error,item,spider) def handle_error(self,failure,item,spider):
print(failure) def do_insert(self,cursor,item):
#执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql = """
insert into jobbole_article(title,create_date,url,url_object_id,
front_image_url,front_image_path,praise_num,comment_num,fav_num,tags,content)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
# 使用游标的execute方法执行sql
cursor.execute(insert_sql, (item["title"], item['create_date'],
item['url'], item['url_object_id'],
item['front_image_url'], item['front_image_path'],
item['praise_num'], item['comment_num'], item['fav_num'],
item['tags'], item['content']))
注意:导入pymysql需要单独导入cursors
import pymysql
import pymysql.cursors
一般我们只需要修改do_insert方法内容就行
还有,传递给的item要和数据表的字段对应上,不能以为不传值就会自动默认为空(但是存储到json文件就是这样)
除了pymysql,还可以通过安装mysqlclient连接数据库,但安装前需要先安装别的包,否则会报错
ubuntu需要安装:
(one_project) laoni@ubuntu:~$ sudo apt-get install libmysqlclient-dev
centos下需要安装:
(one_project) laoni@ubuntu:~$ sudo yum install python-devel mysql-devel
第九篇 数据表设计和保存item到json文件的更多相关文章
- SpringBoot + Vue + ElementUI 实现后台管理系统模板 -- 后端篇(五): 数据表设计、使用 jwt、redis、sms 工具类完善注册登录逻辑
(1) 相关博文地址: SpringBoot + Vue + ElementUI 实现后台管理系统模板 -- 前端篇(一):搭建基本环境:https://www.cnblogs.com/l-y-h/p ...
- 【原创】C#搭建足球赛事资料库与预测平台(3) 基础数据表设计
本博客所有文章分类的总目录:http://www.cnblogs.com/asxinyu/p/4288836.html 开源C#彩票数据资料库系列文章总目录:http://www.cn ...
- 【原创】C#搭建足球赛事资料库与预测平台(4) 比赛信息数据表设计
本博客所有文章分类的总目录:[总目录]本博客博文总目录-实时更新 开源C#彩票数据资料库系列文章总目录:[目录]C#搭建足球赛事资料库与预测平台与彩票数据分析目录 本篇文章开始将逐步介 ...
- 【原创】C#搭建足球赛事资料库与预测平台(6) 赔率数据表设计2
本博客所有文章分类的总目录:[总目录]本博客博文总目录-实时更新 开源C#彩票数据资料库系列文章总目录:[目录]C#搭建足球赛事资料库与预测平台与彩票数据分析目录 本篇文章开始将逐步介 ...
- MySql数据表设计,索引优化,SQL优化,其他数据库
MySql数据表设计,索引优化,SQL优化,其他数据库 1.数据表设计 1.1数据类型 1.2避免空值 1.3text类型优化 2.索引优化 2.1索引分类 2.2索引优化 3.SQL优化 3.1分批 ...
- PHP 开发 APP 接口 学习笔记与总结 - APP 接口实例 [5] 版本设计分析及数据表设计
APP 版本升级以及 APP 演示 ① 版本升级分析以及数据表设计 ② 版本升级接口开发以及 APP 演示 /** * version_upgrade 版本升级信息表 */ CREATE TABLE ...
- mysql status关键字 数据表设计中慎重使用
mysql status关键字 数据表设计中慎重使用
- 中小型WEB系统权限日志数据表设计
中小型WEB系统权限日志数据表设计 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMjc1MDU3OA==/font/5a6L5L2T/fontsi ...
- 数据表设计之主键自增、UUID或联合主键
最近在做数据库设计的时候(以MySQL为主),遇到不少困惑,因为之前做数据库表设计,基本上主键都是使用自增的形式,最近因为这种做法,被领导指出存在一些不足,于是我想搞明白哪里不足. 一.MySQL为什 ...
随机推荐
- PAT甲级——A1141 PATRankingofInstitution【25】
A clique is a subset of vertices of an undirected graph such that every two distinct vertices in the ...
- 【痛定思痛】TCP 三次握手学习
前言:今天滴滴面试失败,痛定思痛,好好复习面试中最惨淡的计算机网络部分 面试中,面试官问我TCP与UDP最大的区别是什么,答:TCP可靠,UDP不可靠,一个面向有连接,一个面向无连接,一个快一个慢:追 ...
- jQuery层次选择器再探究(原创)
关于层次选择器的详解: 1)可以选取某一个元素的所有的后代元素,得到一个jQuery对象的集合--->$('prev descendant') 2)可以选取某一个元素的子辈的所有的元素,得到一个 ...
- 转 笔记本无线和有线的MAC地址修改
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/xueqiang03/article/details/80741734无线网卡的mac地址在出厂时就被 ...
- mysql的时间存储格式
虽然mysql提供了datatime和timestamp两种存储时间的格式,但是如果设计较多计算,应存INT(11)类型.
- 天天用Synchronized,底层原理是个啥?
作者:liuxiaopeng https://www.cnblogs.com/paddix/p/5367116.html Synchronized 的基本使用 Synchronized 的作用主要有三 ...
- 将xml文件转为txt文件
import os import re import sys import glob import xml.etree.ElementTree as ET def xml_to_txt(indir,o ...
- Zookeeper-技术专区-运作流程分析介绍
Zookeeper的启动流程 Zookeeper的主类是QuorumPeerMain,启动时读取zoo.cfg配置文件,如果没有配置server列表,则单机模式启动,否则按集群模式启动,这里只分析集群 ...
- Vim: Overwrite read-only file without quiting vim
当你忘记以sudo命令使用vim编辑一个只读文件时,可以执行以下vim命令强制覆写该文件: :w !sudo tee % > /dev/null 命令太长,可在vimrc文件中做命令映射(映射为 ...
- 【文件分层】/var/run
/var/run是干什么用的 根据linux的文件系统分层结构标准(FHS)中的定义: /var/run 目录中存放的是自系统启动以来描述系统信息的文件. 比较常见的用途是daemon进程将自己的pi ...