爬虫实战 豆瓣音乐top250 xpath
刷知乎时刷到一篇爬取豆瓣音乐top250的,然后看了看,感觉自己的爬虫又更上一层楼了哈啊哈哈,尤其是发现xpath这么好用的东西。
不过也有一个感慨,就是有很多种方式都可以获得想要的数据,对于入门的新人来说着实有些不友好,明确不了方向
话不多说,先贴网站https://music.douban.com/top250
我们这时候看到的网页应该是这样的,以防以后发生变化

看了豆瓣那篇文章之后给我的一个启示就是先爬到一个自己需要的资源,如果成功了,然后就批量爬取剩下的资源。
这里我们就简单的爬取一下标题,评分和音乐链接好了
查看网页代码,然后选中标题所在的地方右键复制,如下图
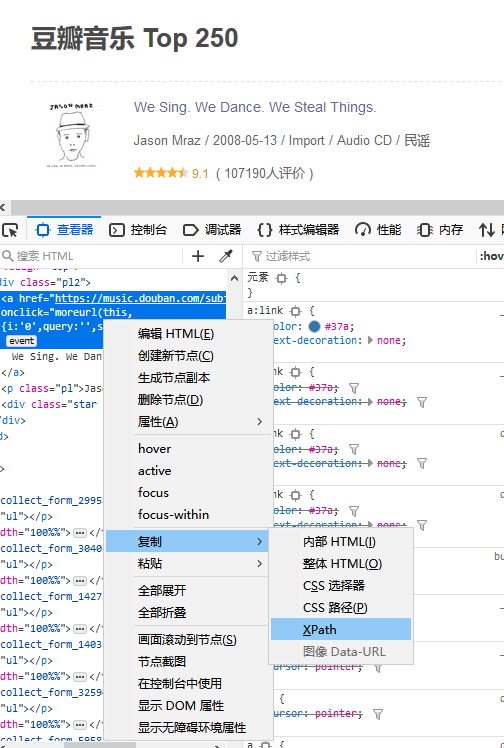
他会自动复制一个xpath
比如我拿到就得这个样子的/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tbody/tr/td[2]/div/a,以供之后用。不过要要先进行一个简单的处理,复制来的xpath可能会多带一个tbody标签,把这个删除就,不然会爬取不到数据。然后再这个xpath后加上/text(),表示我想要获取的是里面的文本内容
我们可以先试着爬取第一个标题
from lxml import etree
import requests url = 'https://music.douban.com/top250'
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url , headers = kv).text
s = etree.HTML(r)
title = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tr/td[2]/div/a/text()')[0]
print(title)
输出结果如下
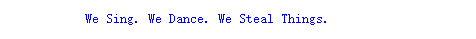
看来是成功的获取到了标题,接下来如法炮制,还有评分和音乐链接,评分没什么好说的,和标题一样的操作就好了,但是音乐链接有点特殊,他是href属性里的数据,其实也难不倒xpath,在这后面加上@href即可,同理,想要别的也可以用@来获取
话不多说直接上代码
from lxml import etree
import requests url = 'https://music.douban.com/top250'
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url , headers = kv).text
s = etree.HTML(r)
title = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tr/td[2]/div/a/text()')[0]
score = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tr/td[2]/div/div/span[2]/text()')[0]
music= s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table[1]/tr/td[2]/div/a/@href')[0]
print(title,score,music)
获取到的效果就是这个样子啦

如果想要获取下一条,那么很简单,去分析下一条的xpath,这里不多赘述,发现是table里的参数发生了变化,那我们就可以改一下xpath,先找到/html/body/div[3]/div[1]/div/div[1]/div/table这一块,然后再这一块里找到后面想要的数据,爬取出来就可以了,直接上代码吧
from lxml import etree
import requests
import json
import re def getUrl():
for i in range(10):
url = 'https://music.douban.com/top250?start={}'.format(i*25) spyder(url) def spyder(url):
#模拟浏览器
kv = {'user-agent':'Mozilla/5.0'}
html = requests.get(url , headers = kv).text
s = etree.HTML(html) trs = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div/table/tr') for tr in trs:
href = tr.xpath('./td[2]/div/a/@href')[0]
title = tr.xpath('./td[2]/div/a/text()')[0].strip()
score = tr.xpath('./td[2]/div/div/span[2]/text()')[0].strip()
numbers = tr.xpath('./td[2]/div/div/span[3]/text()')[0].strip().replace(" ","").replace("\n","")
img = tr.xpath('./td[1]/a/img/@src')[0].strip() items = [href,title,score,numbers,img] with open('temp.txt','a',encoding = 'utf-8') as f:
f.write(json.dumps(items,ensure_ascii=False) + '\n') if '_main_':
getUrl()
这段代码是我看的那篇文章里的,希望诸君能好好消化利用
爬虫实战 豆瓣音乐top250 xpath的更多相关文章
- <爬虫实战>豆瓣电影TOP250(三种解析方法)
1.豆瓣电影排行.py # 目标:爬取豆瓣电影排行榜TOP250的电影信息 # 信息包括:电影名字,上映时间,主演,评分,导演,一句话评价 # 解析用学过的几种方法都实验一下①正则表达式.②Beaut ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
- 【Python爬虫】:使用高性能异步多进程爬虫获取豆瓣电影Top250
在本篇博文当中,将会教会大家如何使用高性能爬虫,快速爬取并解析页面当中的信息.一般情况下,如果我们请求网页的次数太多,每次都要发出一次请求,进行串行执行的话,那么请求将会占用我们大量的时间,这样得不偿 ...
- #1 爬虫:豆瓣图书TOP250 「requests、BeautifulSoup」
一.项目背景 随着时代的发展,国人对于阅读的需求也是日益增长,既然要阅读,就要读好书,什么是好书呢?本项目选择以豆瓣图书网站为对象,统计其排行榜的前250本书籍. 二.项目介绍 本项目使用Python ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- 实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB 豆瓣TOP网址:传送门 一.连接数据库 打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,d ...
- 第一个爬虫经历----豆瓣电影top250(经典案例)
因为要学习数据分析,需要从网上爬取数据,所以开始学习爬虫,使用python进行爬虫,有好几种模拟发送请求的方法,最基础的是使用urllib.request模块(python自带,无需再下载),第二是r ...
- python3[爬虫实战] 使用selenium,xpath爬取京东手机
使用selenium ,可能感觉用的并不是很深刻吧,可能是用scrapy用多了的缘故吧.不过selenium确实强大,很多反爬虫的都可以用selenium来解决掉吧. 思路: 入口: 关键字搜索入口 ...
- 爬取豆瓣音乐TOP250的数据
参考网址:https://music.douban.com/top250 因为详细页的信息更丰富,本次爬虫在详细页中进行,因此先爬取进入详细页的网址链接,进而爬取数据. 需要爬取的信息有:歌曲名.表演 ...
随机推荐
- B. Modulo Equality
当时想到的第一个想法是用拓展欧几里得解方程,求x的最小正解.一发交了之后发现爆long long,因为m是1e9. 因此本题的正解是暴力,保证有解的情况下,那么a数组中的一个数必然对应着b数组中的一个 ...
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 【spring】jdbcTemplate之sql参数注入
demo @Repository("jdbcDao") public class JdbcTemplateDao { @Autowired private JdbcTemplate ...
- while else ,pass执行else,break不执行else
count = 0while count <=5: count += 1 if count == 3:pass print("Loop".count) else: print ...
- CF1093E Intersection of Permutations [分块 +bitset]
大家好, 我非常喜欢暴力数据结构, 于是就用分块A了此题 分块题,考虑前缀和 \(b_i\) 表示 bitset 即 \(0\) ~ $i $ 出现过的数字,然后考虑直接暴力复制块然后前缀和,修改也很 ...
- oracle备份与还原数据
一.表数据备份与还原 creat table 备份表 select * from 原表 where insert into 原表 select * from 备份表 二.利用备份 ...
- element-ui 1.4.13
Form 表单 rules 表单校验函数需要访问实例中的属性时应该把校验规则写为computed,校验函数写入methods <el-form-item prop="taxableIn ...
- python3练习100题——044
41-43讲关于python的变量范围,没有什么别的内容,我删除了. 原题链接:http://www.runoob.com/python/python-exercise-example44.html ...
- C#中删除目录以及目录下文件的方法
场景 C#中根据文件夹路径,将文件夹以及文件夹下文件删除. 注: 博客主页: https://blog.csdn.net/badao_liumang_qizhi关注公众号 霸道的程序猿 获取编程相关电 ...
- 841. 字符串哈希(hash)
给定一个长度为n的字符串,再给定m个询问,每个询问包含四个整数l1,r1,l2,r2l1,r1,l2,r2,请你判断[l1,r1l1,r1]和[l2,r2l2,r2]这两个区间所包含的字符串子串是否完 ...