程序员眼中的 SQL Server-非聚集索引能给我们带来什么?
写在前面
最近在做的一个项目,页面访问的时候很慢(大概几秒钟的样子),然后用日志记录的方式,来排查这个问题,最后发现是 Entity Framework 初始化的一个坑(大概要花 6-7 秒),详见:《来,给Entity Framework热热身》,但是除了这个问题,还发现当一些用户数据量很大的时候,访问也是有些慢,这个就不是 Entity Framework 的问题了(因为初始化已完成),用 Sql Server Profiler 来跟踪页面访问的时 SQL 的执行情况,因为应用程序很简单,页面加载的时候,跟踪检测到三个 SQL 执行,看了下也没什么问题(两个获取数量,一个获取列表),数量获取的 SQL,这个应该执行会很快,所以把分析焦点放在了那个获取列表的 SQL 上,因为 SQL 没什么问题,那应该是关于这条 SQL 建的索引有问题。注:上面所说项目中大概有 100 万的数据。
关于数据库中的索引概念,记得在很早之前整理了一篇博文《T-Sql(八)字段索引和数据加密》,现在来看,写的真是一坨屎,概念讲的再多没个毛用,关键在于对实际应用中产生问题的分析。在研究这个问题之前,搜了一些相关资料,主要来自园中的几位 SQL Server 大神(CareySon、桦仔、听风吹雨等),稍微看了下,关于索引,主要是一些数据库专业术语,看的不是很明白,作为程序员,我们知道索引分为聚集性索引和非聚集性索引,聚集性索引一般为主键(也可以不是),在创建表的时候会自动创建,针对上面我那个应用查询问题,查询条件是一些非主键字段,所以这边探讨下非聚集性索引。
我不会说一些数据库概念,所以只能用做一些实践来理解概念的意义,以下应用场景中的用例是虚拟出来的,只是作为个人研究使用。
程序员应该有刨根问底的怪癖,虽然这是个数据库问题。
应用场景
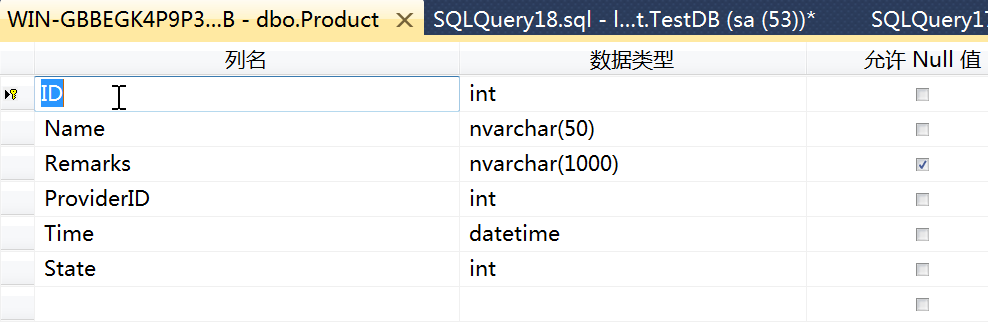
有一个 Product 表,字段如下:
数据添加脚本:
begin tran
declare @index int
set @index=0
while(@index<1000000)
begin
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题1','我是测试备注1我是测试备注1我是测试备注1我是测试备注1我是测试备注1我是测试备注1',1,GETDATE(),0)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题2','我是测试备注2我是测试备注2我是测试备注2我是测试备注2我是测试备注2我是测试备注2',1,GETDATE(),1)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题3','我是测试备注3',3,GETDATE(),1)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题4','我是测试备注4我是测试备注4我是测试备注4我是测试备注4我是测试备注4我是测试备注4',4,GETDATE(),1)
set @index=@index+1
end
commit
Product 表中插入了四百万的数据,为了接近我们现实生产环境,所以对数据进行了不同插入。
一般应用环境查询,有时候我们会针对一个字段进行 where 查询,有时候也会 and 另一个字段进行查询,这个时候,关于这两个字段的索引怎么建?还是不需要建?是分别建两个?还是建一个组合的?其实说真的,可能看到这的数据库大神会莞尔一笑,但是作为程序员,这些我真不知道,搜索的资料中也并没有对这些鸡毛蒜皮进行的说明,没办法,只能自己瞎折腾下。我们下面要做是 ProviderID 和 State 的查询操作,有分别查询,也有组合查询,然后我们再对 Product 表建立这两个字段的索引,看看有什么不同之处?还有就是针对不同的索引方式,查询又会有什么不同?我们睁大眼睛来看一下。
问题分析
我再对上面的分析进行说明下,首先,查询主要为2种:
- where ProviderID=?
- where ProviderID=? and State=?
非聚集性索引的创建主要为3种:
- 不创建索引
- ProviderID 字段索引
- ProviderID 和 State 字段索引
针对这个应用场景和上面的分析,会得出 3*2 六种结果,其实我最想知道的是下面的第三种,即创建一个组合字段索引,对单个字段的查询会不会有影响?还有就是反过来,单个字段的索引创建,对组合字段查询会不会有影响?当然试过了才知道,看一下执行结果。
执行结果
测试脚本:
declare @begin_date datetime
declare @end_date datetime
select @begin_date = getdate()
select * from [dbo].[Product] where ...
select @end_date = getdate()
select datediff(ms,@begin_date,@end_date) as '用时/毫秒'
为了接近测试结果,每次语句执行三次,然后再取平均值,截图太麻烦了,这边就直接贴下执行结果。
不创建索引
where ProviderID=1(二百万数据)
执行结果:13806毫秒,13380毫秒,12730毫秒
平均结果:13305毫秒where ProviderID=1 and State=1(一百万数据)
执行结果:6556毫秒,6613毫秒,6706毫秒
平均结果:6625毫秒
创建索引字段 ProviderID
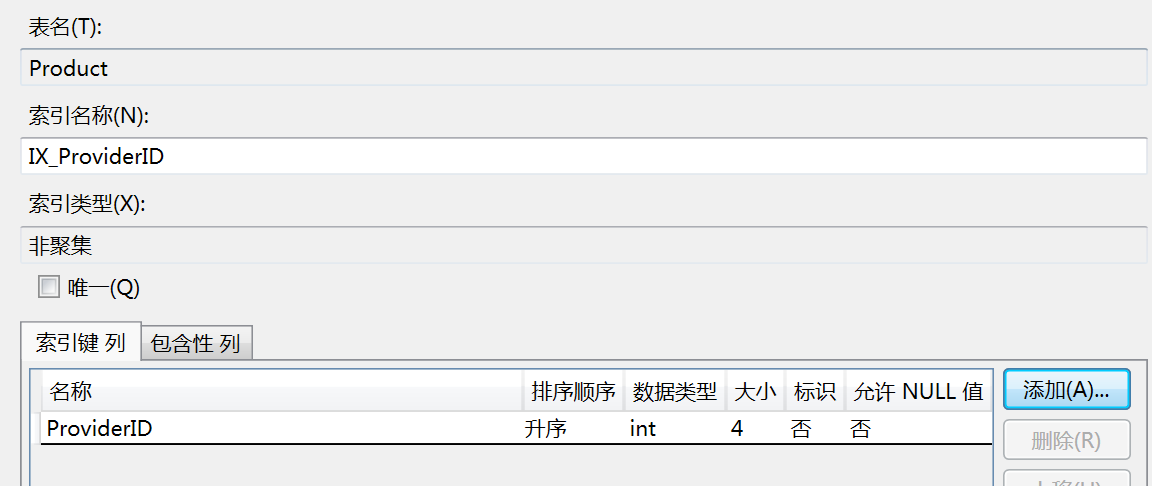
where ProviderID=1
执行结果:13986毫秒,13810毫秒,15853毫秒
平均结果:14549毫秒where ProviderID=1 and State=1
执行结果:7153毫秒,7190毫秒,13950毫秒
平均结果:7122毫秒
创建索引字段 ProviderID 和 State
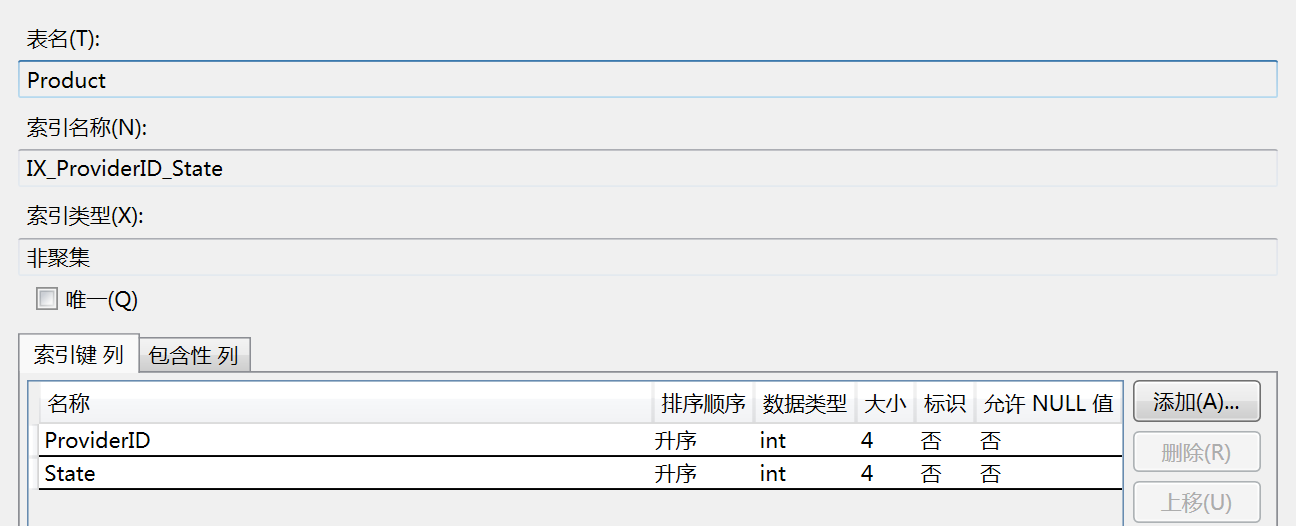
where ProviderID=1
执行结果:13840毫秒,14163毫秒,15853毫秒
平均结果:14618毫秒where ProviderID=1 and State=1
执行结果:7033毫秒,7220毫秒,7023毫秒
平均结果:7152毫秒
结果分析

虽然测试的有些不完整,但是看到结果,哥有些凌乱了(建了索引,性能反而会降低?),难道是我插入的数据有问题?还是创建索引有问题?还是我人品有问题???坐等数据库大神指教。。。
程序员眼中的 SQL Server-非聚集索引能给我们带来什么?的更多相关文章
- 程序员眼中的 SQL Server-执行计划教会我如何创建索引?
先说点废话 以前有 DBA 在身边的时候,从来不曾考虑过数据库性能的问题,但是,当一个应用程序从头到脚都由自己完成,而且数据库面对的是接近百万的数据,看着一个页面加载速度像乌龟一样,自己心里真是有种挫 ...
- SQL查询优化:详解SQL Server非聚集索引(转载)
本文是转载,原文地址 http://tech.it168.com/a2011/1228/1295/000001295176.shtml 在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索 ...
- SQL Server 非聚集索引的覆盖,连接,交叉和过滤 <第二篇>
在SQL Server中,非聚集索引其实可以看做是一个含有聚集索引的表,但相对实际的表来说,非聚集索引中所存储的表的列数要少得多,一般就是索引列,聚集键(或RID).非聚集索引仅仅包含源表中的非聚集索 ...
- T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
写在前面:这是第一篇T-SQL查询高级系列文章.但是T-SQL查询进阶系列还远远没有写完.这个主题放到高级我想是因为这个主题需要一些进阶的知识作为基础..如果文章中有错误的地方请不吝指正.本篇文章 ...
- SQL Server的聚集索引和非聚集索引
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引)…… (一) ...
- 但从谈论性能点SQL Server选择聚集索引键
简单介绍 在SQL Server中,数据是按页进行存放的.而为表加上聚集索引后,SQL Server对于数据的查找就是依照聚集索引的列作为keyword进行了. 因此对于聚集索引的选择对性能的影响就变 ...
- 探究SQL添加非聚集索引,性能提高几十倍之谜
上周,技术支持反映:客户的一个查询操作需要耗时6.1min左右,在跟进代码后,简化了数据库的查询后仍然收效甚微.后来,技术总监分析了sql后,给其中的一个表添加的一个非聚集索引(三个字段)后,同样的查 ...
- SQL SERVER中非聚集索引的覆盖,连接,交叉,过滤
1.覆盖索引:select和where中包含的结果集中应存在“非聚集索引列”,这样就不用查找基表了,索引表即可搞定: 2.索引交叉:索引的交叉可以理解成建立多个非聚集索引之间的join,如表实体一 ...
- 图解SQL Server:聚集索引、唯一索引、主键
http://www.cnblogs.com/chenxizhang/archive/2010/01/14/1648042.html
随机推荐
- Win10 下安装 NodeJS
1,右键点击底部导航栏win(开始)弹出,使用 命令提示符(管理员A) 2,输入命令,进入安装文件目录,输入 msiexec/package node-v4.4.4-x64.msi ----弹出安 ...
- C语言中的插入排序(2016-12-30)
直接插入排序: 算法思想:假设待排序的记录存放在数组R[1--n]中,初始时,i=1,R[1]自成一个有序区,无序区为R[2--n].然后从i=2起直到i=n,依次将R[i]插入当前的有序区R[1.. ...
- 使用JDBC调用存储过程
DELIMITER $$ DROP PROCEDURE IF EXISTS `jdbc`.`addUser` $$ ),in birthday date,in money float,out pid ...
- UI控件(UISegmentedControl)
@implementation ViewController - (void)viewDidLoad { [super viewDidLoad]; NSArray* segmentArray = [[ ...
- 自己动手写一个简单的MVC框架(第一版)
一.MVC概念回顾 路由(Route).控制器(Controller).行为(Action).模型(Model).视图(View) 用一句简单地话来描述以上关键点: 路由(Route)就相当于一个公司 ...
- 扩展Bootstrap Tooltip插件使其可交互
最近在公司某项目开发中遇见一特殊需求,请笔者帮助,因此有了本文的插件.在前端开发中tooltip是一个极其常用的插件,它能更好向使用者展示更多的文档等帮助信息.它们通常都是一些静态文本信息.但同事他们 ...
- A*寻路算法
对于初学者而言,A*寻路已经是个比较复杂的算法了,为了便于理解,本文降低了A*算法的难度,规定只能横竖(四方向)寻路,而无法直接走对角线,使得整个算法更好理解. 简而言之,A*寻路就是计算从起点经过该 ...
- Spark DAGSheduler生成Stage过程分析实验
RDD.Action触发SparkContext.run,这里举最简单的例子rdd.count() /** * Return the number of elements in the RDD. */ ...
- Atitit 软件开发中 瓦哈比派的核心含义以及修行方法以及对我们生活与工作中的指导意义
Atitit 软件开发中 瓦哈比派的核心含义以及修行方法以及对我们生活与工作中的指导意义 首先我们指明,任何一种行动以及教派修行方法都有他的多元化,只看到某一方面,就不能很好的评估利弊,适不适合自己使 ...
- Atitit Mysql查询优化器 存取类型 范围存取类型 索引存取类型 AND or的分析
Atitit Mysql查询优化器 存取类型 范围存取类型 索引存取类型 AND or的分析 Atitit Mysql查询优化器 存取类型 范围存取类型 索引存取类型 AND or的分析1 存 ...