Windows下mnist数据集caffemodel分类模型训练及测试
1. MNIST数据集介绍
MNIST是一个手写数字数据库,样本收集的是美国中学生手写样本,比较符合实际情况,大体上样本是这样的:

MNIST数据库有以下特性:
- 包含了60000个训练样本集和10000个测试样本集;
- 分4部分,分别是一个训练图片集,一个训练标签集,一个测试图片集,一个测试标签集,每个标签的值是0~9之间的数字;
- 原始图像归一化大小为28*28,以二进制形式保存
2. Windows+caffe框架下MNIST数据集caffemodel分类模型训练及测试
1. 下载mnist数据
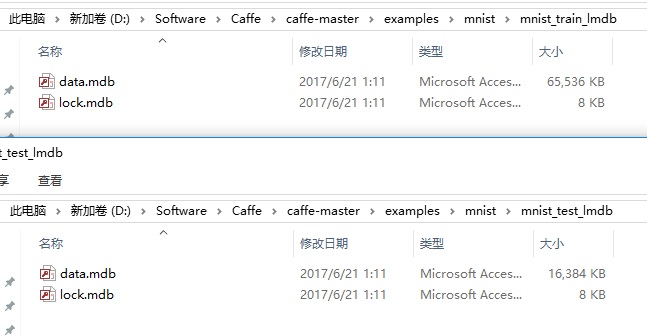
2. 将MNIST数据集转换为lmdb数据文件
- 它们都是键/值对嵌入式数据库管理系统编程库
- 虽然lmdb的内存消耗是leveldb的1.1倍,但是lmdb的处理速度比leveldb快10%到15%,另外lmdb允许多种训练模型同时读取同一组数据集。
- lmdb取代了leveldb成为了caffe默认的数据集生成格式。
.\Build\x64\Debug\convert_mnist_data.exe .\data\mnist\mnist_train_lmdb\train-images.idx3-ubyte .\data\mnist\mnist_train_lmdb\train-labels.idx1-ubyte .\examples\mnist\mnist_train_lmdb
echo.
.\Build\x64\Debug\convert_mnist_data.exe .\data\mnist\mnist_test_lmdb\t10k-images.idx3-ubyte .\data\mnist\mnist_test_lmdb\t10k-labels.idx1-ubyte .\examples\mnist\mnist_test_lmdb
pause 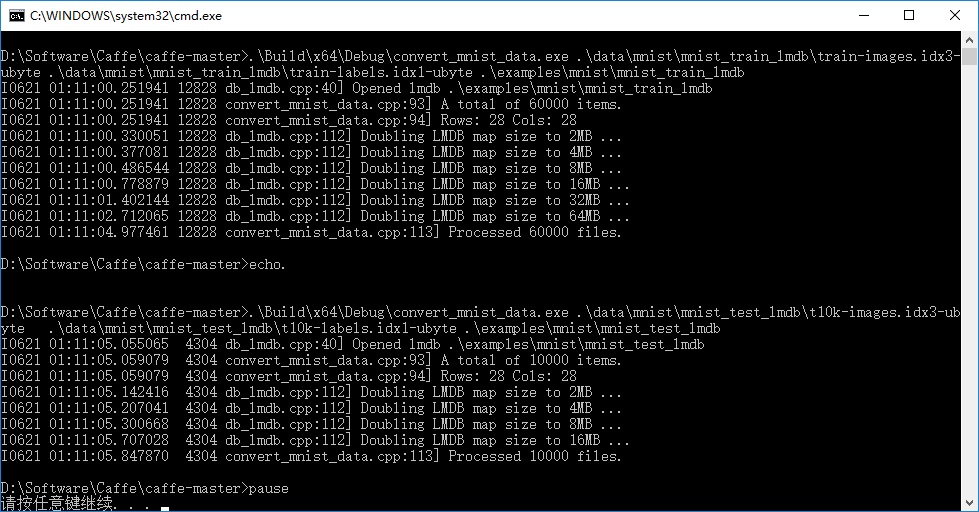
3. 计算数据库的均值文件
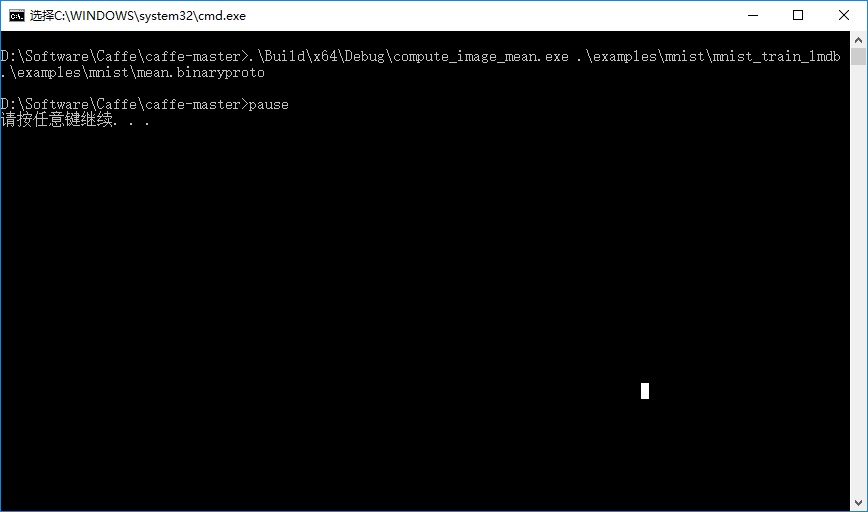
.\Build\x64\Debug\compute_image_mean.exe .\examples\mnist\mnist_train_lmdb .\examples\mnist\mean.binaryproto
pause 双击运行,执行结果:
4. lenet训练参数设置
设置lmdb文件路径
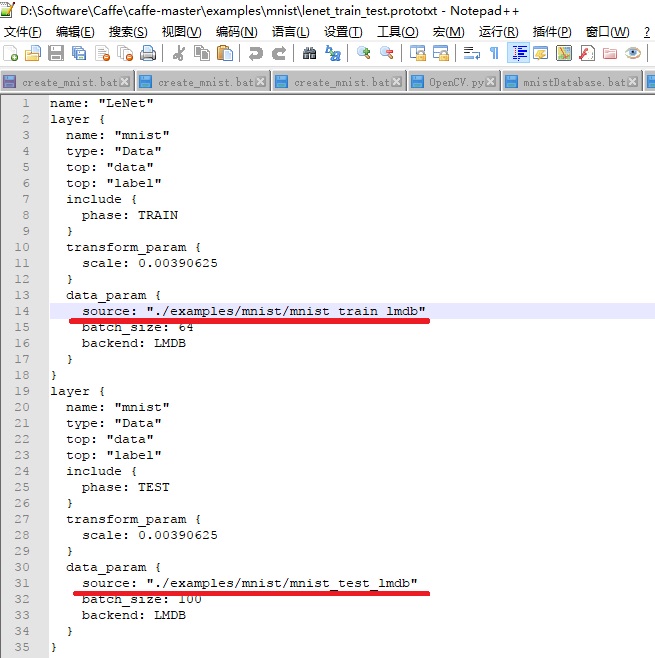
设置lenet训练参数
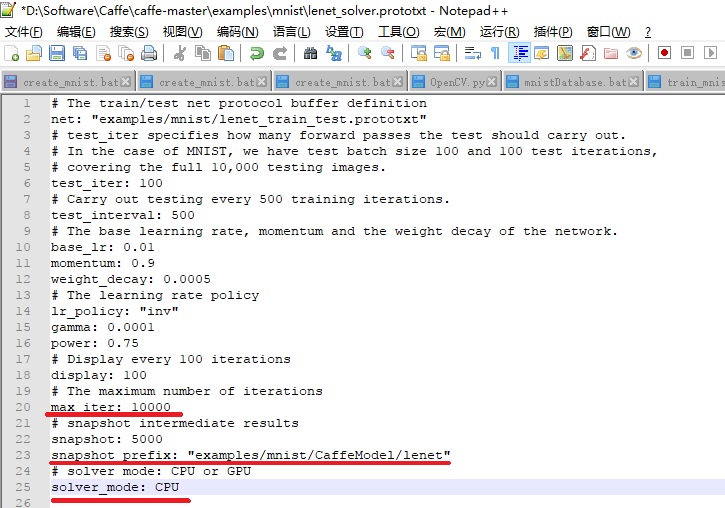
- GPU or CPU: caffe中lenet的训练参数默认是使用GPU,这里修改为CPU;
- 最大迭代次数: 最大迭代次数默认是10000,一般情况下最大迭代次数越大,训练的模型越准确,训练耗时也越长,这里max_iter的值10000不做修改。
- caffemodel生成路径:训练完成之后会生成caffemodel分类模型,默认生成路径是在mnist根目录,这里修改为mnist目录下的CaffeModel文件夹内,snapshot_prefix: "examples/mnist/CaffeModel/lenet";
5. 执行lenet模型训练,生成caffemodel
.\Build\x64\Debug\caffe.exe train --solver=examples/mnist/lenet_solver.prototxt
pause双击运行,开始训练:
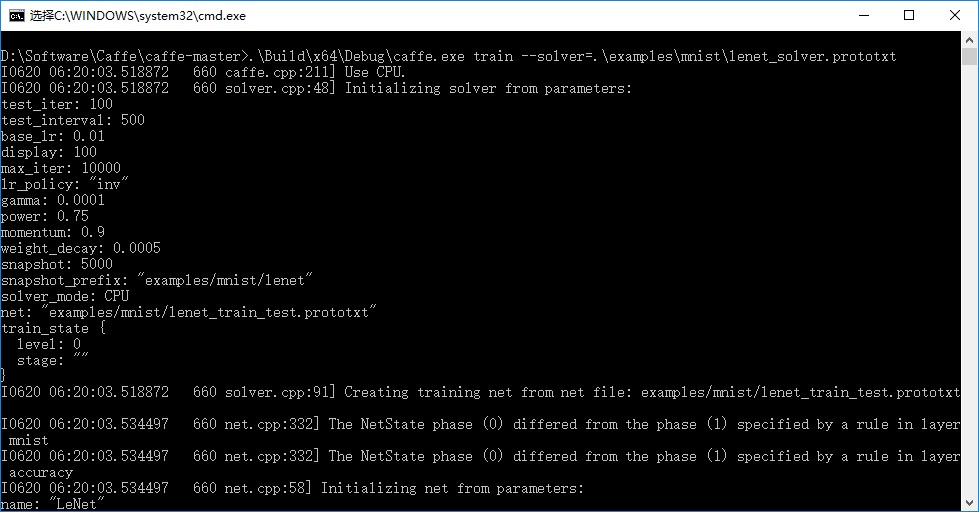
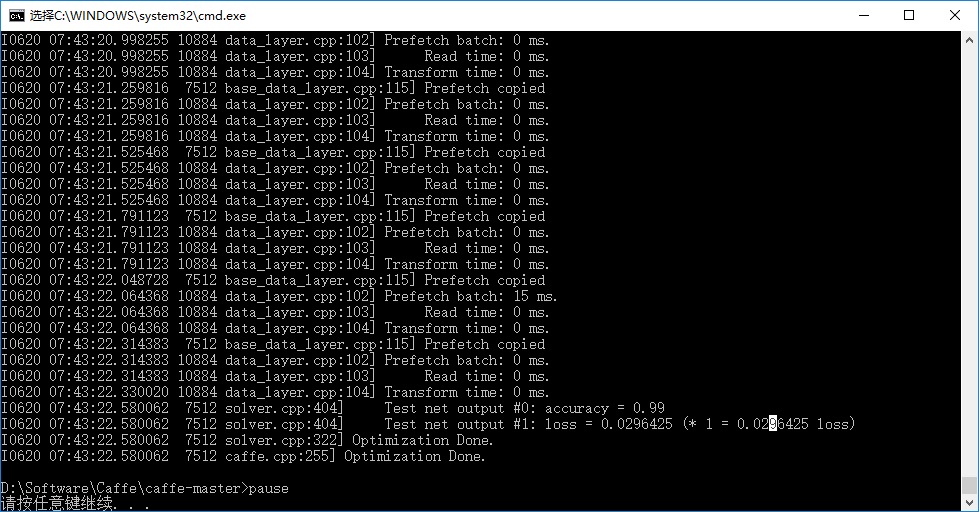
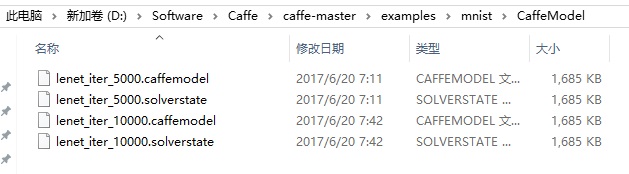
- lenet_iter_10000.caffemodel 和 lenet_iter_5000.caffemodel: 这两个文件是最终生成的caffemodel分类模型;
- lenet_iter_10000.solverstate 和 lenet_iter_5000.solverstate : 这两个文件是记录当前训练状态信息文件。在跑训练模型的时候遇到断电等异常情况导致训练中断,再次训练的时候就不必浪费时间从头开始训练,只需要调用 .solverstate文件,从上次训练中断的位置处继续训练即可,具体使用方法略过。
6. 使用caffemodel测试一下mnist测试数据集的分类准确率
.\Build\x64\Debug\caffe.exe test --model=.\examples\mnist\lenet_train_test.prototxt -weights=.\examples\mnist\CaffeModel\lenet_iter_10000.caffemodel
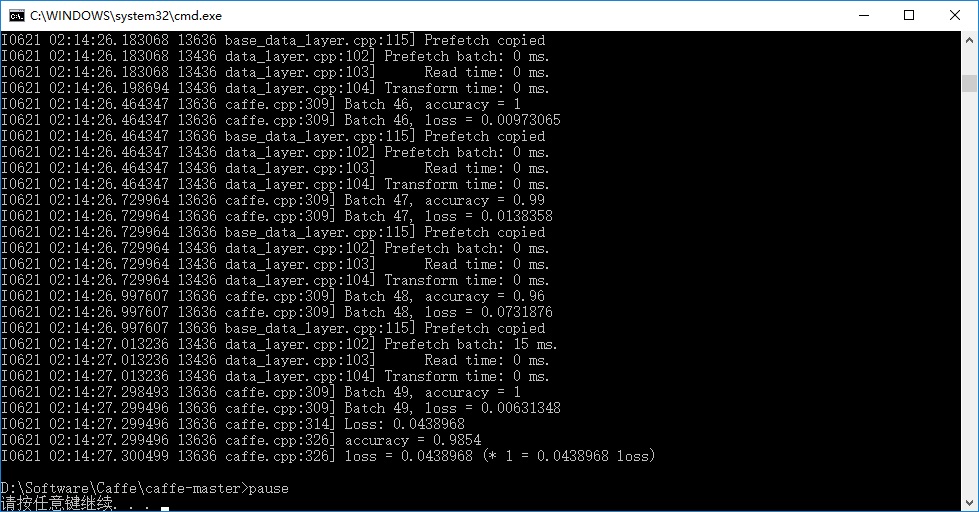
pause 程序会根据lenet_train_test.prototxt文件里设置的测试数据集的路径自动加载到测试数据,双击运行,完成之后得到测试数据集的识别准确率,约为98.5%:
Windows下mnist数据集caffemodel分类模型训练及测试的更多相关文章
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- TensorFlow 下 mnist 数据集的操作及可视化
from tensorflow.examples.tutorials.mnist import input_data 首先需要连网下载数据集: mnsit = input_data.read_data ...
- 关于 Poco::TCPServer框架 (windows 下使用的是 select模型) 学习笔记.
说明 为何要写这篇文章 ,之前看过阿二的梦想船的<Poco::TCPServer框架解析> http://www.cppblog.com/richbirdandy/archive/2010 ...
- 比较windows下的5种IO模型
看到一个很有意思的解释: 老陈有一个在外地工作的女儿,不能经常回来,老陈和她通过信件联系.他们的信会被邮递员投递到他们的信箱里. 这和Socket模型非常类似.下面我就以老陈接收信件为例讲解Socke ...
- fcn模型训练及测试
1.模型下载 1)下载新版caffe: https://github.com/BVLC/caffe 2)下载fcn代码: https://github.com/shelhamer/fcn.berkel ...
- Ubuntu16.04下caffe CPU版的图片训练和测试
一 数据准备 二.转换为lmdb格式 1.首先,在examples下面创建一个myfile的文件夹,来用存放配置文件和脚本文件.然后编写一个脚本create_filelist.sh,用来生成train ...
- windows下php7.1安装redis扩展以及redis测试使用全过程
最近做项目,需要用到redis相关知识.在Linux下,redis扩展安装起来很容易,但windows下还是会出问题的.因此,特此记下自己实践安装的整个过程,以方便后来人. 一,php中redis扩展 ...
- windows下php7.1安装redis扩展以及redis测试使用全过程(转)
最近做项目,需要用到redis相关知识.在Linux下,redis扩展安装起来很容易,但windows下还是会出问题的.因此,特此记下自己实践安装的整个过程,以方便后来人. 一,php中redis扩展 ...
- Tensorflow学习教程------利用卷积神经网络对mnist数据集进行分类_利用训练好的模型进行分类
#coding:utf-8 import tensorflow as tf from PIL import Image,ImageFilter from tensorflow.examples.tut ...
随机推荐
- jquery访问ashx文件示例
转自原文jquery访问ashx文件示例 .ashx 文件用于写web handler的..ashx文件与.aspx文件类似,可以通过它来调用HttpHandler类,它免去了普通.aspx页面的控件 ...
- Android Touch事件传递机制全面解析(从WMS到View树)
转眼间近一年没更新博客了,工作一忙起来.非常难有时间来写博客了,因为如今也在从事Android开发相关的工作,因此以后的博文也会很多其它地专注于这一块. 这篇文章准备从源代码层面为大家带来Touch事 ...
- 【转载】linux下的usb抓包方法
1 linux下的usb抓包方法 1.配置内核使能usb monitor: make menuconfig Device Drivers --> ...
- jQuery——map()函数以及它的java实现
map()函数小简单介绍 map()函数一直都是我觉得比較有用的函数之中的一个,为什么这么说呢? 先来考虑一下.你是否碰到过下面场景:须要遍历一组对象取出每一个对象的某个属性(比方id)而且用分隔符隔 ...
- C++中的字节对齐
本博客(http://blog.csdn.net/livelylittlefish)贴出作者(三二一.小鱼)相关研究.学习内容所做的笔记,欢迎广大朋友指正! 字节对齐 1. 基本概念字节对齐:计算机存 ...
- iOS UI01_UIView
// // AppDelegate.m // UI01_UIView // // Created by dllo on 15/7/29. // Copyright (c) 2015年 zhoz ...
- DGA ngram kmeans+TSNE用于绘图
# -*- coding:utf-8 -*- import sys import re import numpy as np from sklearn.externals import joblib ...
- ES不设置副本是非常脆弱的,整个文章告诉了你为什么
Delaying Shard Allocation As discussed way back in Scale Horizontally, Elasticsearch will automatica ...
- 图论之tarjan缩点
缩点,就是把一张有向有环图中的环缩成一个个点,形成一个有向无环图. 首先我介绍一下为什么这题要缩点(有人肯定觉得这是放屁,这不就是缩点的模板题吗?但我们不能这么想,考试的时候不会有人告诉你打什么板上去 ...
- POJ 3368 线段树
思路: 先统计在第i个位置当前数字已经出现的次数. 维护两个数组,一个是当前位置的数字最后一次出现的位置,另一个是当前位置的数字第一次出现的位置 查找的时候分为两种情况: 没有和边界相交(意会意会)的 ...