精确率与召回率,RoC曲线与PR曲线
在机器学习的算法评估中,尤其是分类算法评估中,我们经常听到精确率(precision)与召回率(recall),RoC曲线与PR曲线这些概念,那这些概念到底有什么用处呢?
首先,我们需要搞清楚几个拗口的概念:
1. TP, FP, TN, FN
- True Positives,TP:预测为正样本,实际也为正样本的特征数
- False Positives,FP:预测为正样本,实际为负样本的特征数
- True Negatives,TN:预测为负样本,实际也为负样本的特征数
- False Negatives,FN:预测为负样本,实际为正样本的特征数
听起来还是很费劲,不过我们用一张图就很容易理解了。图如下所示,里面绿色的半圆就是TP(True Positives), 红色的半圆就是FP(False Positives), 左边的灰色长方形(不包括绿色半圆),就是FN(False Negatives)。右边的 浅灰色长方形(不包括红色半圆),就是TN(True Negatives)。这个绿色和红色组成的圆内代表我们分类得到模型结果认为是正值的样本。
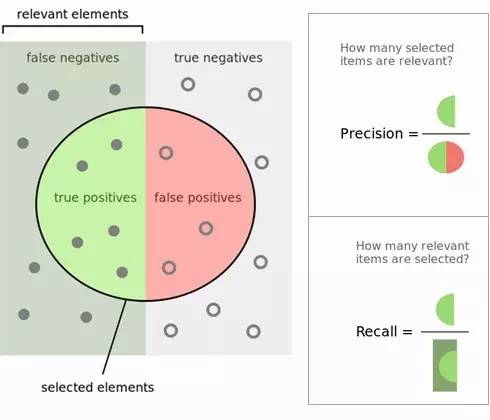
2. 精确率(precision),召回率(Recall)与特异性(specificity)
精确率(Precision)的定义在上图可以看出,是绿色半圆除以红色绿色组成的圆。严格的数学定义如下:
\(P = \frac{TP}{TP + FP }\)
召回率(Recall)的定义也在图上能看出,是绿色半圆除以左边的长方形。严格的数学定义如下:
\(R = \frac{TP}{TP + FN }\)
特异性(specificity)的定义图上没有直接写明,这里给出,是红色半圆除以右边的长方形。严格的数学定义如下:
\(S = \frac{FP}{FP + TN }\)
有时也用一个F1值来综合评估精确率和召回率,它是精确率和召回率的调和均值。当精确率和召回率都高时,F1值也会高。严格的数学定义如下:
\(\frac{2}{F_1} = \frac{1}{P} + \frac{1}{R}\)
有时候我们对精确率和召回率并不是一视同仁,比如有时候我们更加重视精确率。我们用一个参数\(\beta\)来度量两者之间的关系。如果\(\beta>1\), 召回率有更大影响,如果\(\beta<1\),精确率有更大影响。自然,当\(\beta=1\)的时候,精确率和召回率影响力相同,和F1形式一样。含有度量参数\(\beta\)的F1我们记为\(F_\beta\), 严格的数学定义如下:
\(F_\beta = \frac{(1+\beta^2)*P*R}{\beta^2*P + R}\)
我们熟悉了精确率, 召回率和特异性,后面的RoC曲线和PR曲线就好了解了。
3. RoC曲线和PR曲线
有了上面精确率, 召回率和特异性的基础,理解RoC曲线和PR曲线就小菜一碟了。
以召回率为y轴,以特异性为x轴,我们就直接得到了RoC曲线。从召回率和特异性的定义可以理解,召回率越高,特异性越小,我们的模型和算法就越高效。也就是画出来的RoC曲线越靠近左上越好。如下图左图所示。从几何的角度讲,RoC曲线下方的面积越大越大,则模型越优。所以有时候我们用RoC曲线下的面积,即AUC(Area Under Curve)值来作为算法和模型好坏的标准。
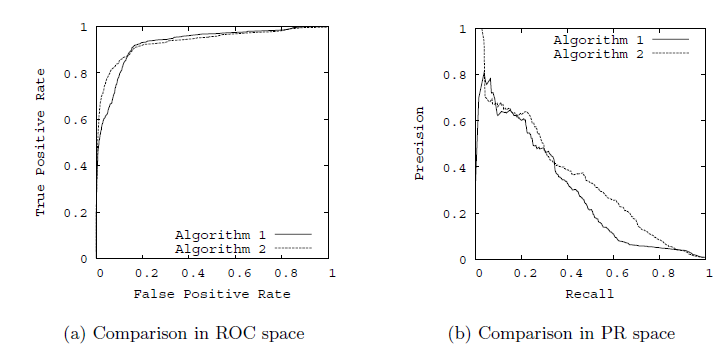
以精确率为y轴,以召回率为x轴,我们就得到了PR曲线。仍然从精确率和召回率的定义可以理解,精确率越高,召回率越高,我们的模型和算法就越高效。也就是画出来的PR曲线越靠近右上越好。如上图右图所示。
使用RoC曲线和PR曲线,我们就能很方便的评估我们的模型的分类能力的优劣了。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
精确率与召回率,RoC曲线与PR曲线的更多相关文章
- 机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC--周振洋
机器学习性能指标精确率.召回率.F1值.ROC.PRC与AUC 精确率.召回率.F1.AUC和ROC曲线都是评价模型好坏的指标,那么它们之间有什么不同,又有什么联系呢.下面让我们分别来看一下这几个指标 ...
- 精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?
https://www.52ml.net/19370.html 精度.召回.F1点直观理解 图片来自:http://blog.csdn.net/marising/article/details/654 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC
参考资料:https://zhuanlan.zhihu.com/p/46714763 ROC/AUC作为机器学习的评估指标非常重要,也是面试中经常出现的问题(80%都会问到).其实,理解它并不是非常难 ...
- 准确率、精确率、召回率、F1
在搭建一个AI模型或者是机器学习模型的时候怎么去评估模型,比如我们前期讲的利用朴素贝叶斯算法做的垃圾邮件分类算法,我们如何取评估它.我们需要一套完整的评估方法对我们的模型进行正确的评估,如果模型效果比 ...
- 目标检测评价指标mAP 精准率和召回率
首先明确几个概念,精确率,召回率,准确率 精确率precision 召回率recall 准确率accuracy 以一个实际例子入手,假设我们有100个肿瘤病人. 95个良性肿瘤病人,5个恶性肿瘤病人. ...
- 二分类算法的评价指标:准确率、精准率、召回率、混淆矩阵、AUC
评价指标是针对同样的数据,输入不同的算法,或者输入相同的算法但参数不同而给出这个算法或者参数好坏的定量指标. 以下为了方便讲解,都以二分类问题为前提进行介绍,其实多分类问题下这些概念都可以得到推广. ...
- ROC曲线、PR曲线
在论文的结果分析中,ROC和PR曲线是经常用到的两个有力的展示图. 1.ROC曲线 ROC曲线(receiver operating characteristic)是一种对于灵敏度进行描述的功能图像. ...
- ROC曲线 VS PR曲线
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
随机推荐
- 我听说 C...
我听说在 c 语言的世界里,goto 和异常处理都是声名狼藉的东西,而我认为它们在一起就能化解各自的问题.
- iOS AFNetWorking 3.1 的网络解析
AFNetworking 3.0中废弃: AFURLConnectionOperation AFHTTPRequestOperation AFHTTPRequestOperationManager ...
- Windows下ADT环境搭建
1.JDK安装 下载JDK(点我下载),安装成功后在我的电脑->属性->高级->环境变量->系统变量中添加以下环境变量: JAVA_HOME值为C:\Program Files ...
- centos 7.2 安装PHP7.1+apache2.4.23
安装准备: http://ftp.cuhk.edu.hk/pub/packages/apache.org//httpd/httpd-2.4.23.tar.gz 下载apache http://cn ...
- 安卓初級教程(5):TabHost的思考
package com.myhost; import android.os.Bundle; import android.view.LayoutInflater; import android.wid ...
- DOMO1
以下是Demo首页的预览图 demo下载:http://www.eoeandroid.com/forum.php?mod=attachment&aid=NjE0Njh8ZTIyZDA2M2N8 ...
- Javaee中文乱码解决方法
分类: javaee2015-07-09 16:35 29人阅读 评论(0) 收藏 编辑 删除 post 中文乱码解决方式 接受数据的时候设置 request.setCharacterEncoding ...
- 【腾讯Bugly干货分享】让 CodeReview 这股清流再飞一会儿
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/ToYeT4Y4pzx0ii9Z92fo-Q 作者:刘 ...
- 架构之路(七)MVC点滴
我们目前正在开发中的是任务管理系统,一个前端复杂的项目,所以我们先从MVC讲起吧. WebForm 随着ASP.NET MVC的兴起,WebForm已成昨日黄花,但我其实还很想为WebForm说几句. ...
- ASP.Net MVC3 图片上传详解(form.js,bootstrap)
图片上传的插件很多,但很多时候还是不能切合我们的需求,我这里给大家分享个我用一个form,file实现上传四张图片的小demo.完全是用jquery前后交互,没有用插件. 最终效果图如下: 玩过花田人 ...