机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC--周振洋
机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC
精确率、召回率、F1、AUC和ROC曲线都是评价模型好坏的指标,那么它们之间有什么不同,又有什么联系呢。下面让我们分别来看一下这几个指标分别是什么意思。
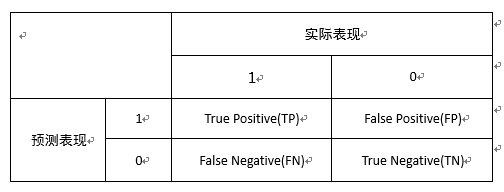
针对一个二分类问题,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况.
(1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
(2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
如下图所示:
精确率(Precision)为TP/(TP+FP),即实际是正类并且被预测为正类的样本占所有预测为正类的比例,精确率更为关注将负样本错分为正样本(FP)的情况。
召回率(Recall)为TP/(TP+FN),即实际是正类并且被预测为正类的样本占所有实际为正类样本的比例,召回率更为关注将正样本分类为负样本(FN)的情况。
F1值是精确率和召回率的调和均值,即F1=2PR/(P+R) (P代表精确率,R代表召回率),相当于精确率和召回率的综合评价指标。
有的时候,我们对recall 与 precision 赋予不同的权重,表示对分类模型的偏好:
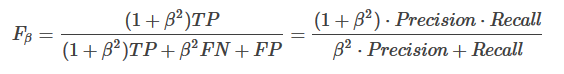
可以看到,当 ,那么就退回到了, 其实反映了模型分类能力的偏好, 的时候,precision的权重更大,为了提高,我们希望precision 越小,而recall 应该越大,说明模型更偏好于提升recall,意味着模型更看重对正样本的识别能力; 而 的时候,recall 的权重更大,因此,我们希望recall越小,而precision越大,模型更偏好于提升precision,意味着模型更看重对负样本的区分能力。
ROC曲线其实是多个混淆矩阵的结果组合,如果在上述模型中我们没有定好阈值,而是将模型预测结果从高到低排序,将每个概率值依次作为阈值,那么就有多个混淆矩阵。
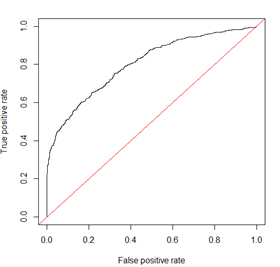
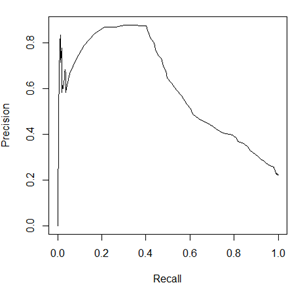
除此之外,在评价模型时还会用到KS(Kolmogorov-Smirnov)值,KS=max(TPR-FPR),即为TPR与FPR的差的最大值,KS值可以反映模型的最优区分效果,此时所取的阈值一般作为定义好坏用户的最优阈值。
相对来讲ROC曲线会稳定很多,在正负样本量都足够的情况下,ROC曲线足够反映模型的判断能力。
因此,对于同一模型,PRC和ROC曲线都可以说明一定的问题,而且二者有一定的相关性,如果想评测模型效果,也可以把两条曲线都画出来综合评价。
对于有监督的二分类问题,在正负样本都足够的情况下,可以直接用ROC曲线、AUC、KS评价模型效果。在确定阈值过程中,可以根据Precision、Recall或者F1来评价模型的分类效果。
对于多分类问题,可以对每一类分别计算Precision、Recall和F1,综合作为模型评价指标。
机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC--周振洋的更多相关文章
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- LightGBM详细用法--机器学习算法--周振洋
LightGBM算法总结 2018年08月21日 18:39:47 Ghost_Hzp 阅读数:2360 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
- 机器学习sklearn的快速使用--周振洋
ML神器:sklearn的快速使用 传统的机器学习任务从开始到建模的一般流程是:获取数据 -> 数据预处理 -> 训练建模 -> 模型评估 -> 预测,分类.本文我们将依据传统 ...
- XGBoost——机器学习--周振洋
XGBoost——机器学习(理论+图解+安装方法+python代码) 目录 一.集成算法思想 二.XGBoost基本思想 三.MacOS安装XGBoost 四.用python实现XGBoost算法 在 ...
- LightGBM的并行优化--机器学习-周振洋
LightGBM的并行优化 上一篇文章介绍了LightGBM算法的特点,总结起来LightGBM采用Histogram算法进行特征选择以及采用Leaf-wise的决策树生长策略,使其在一批以树模型为基 ...
- 准确率、精确率、召回率、F1
在搭建一个AI模型或者是机器学习模型的时候怎么去评估模型,比如我们前期讲的利用朴素贝叶斯算法做的垃圾邮件分类算法,我们如何取评估它.我们需要一套完整的评估方法对我们的模型进行正确的评估,如果模型效果比 ...
- [机器学习] 性能评估指标(精确率、召回率、ROC、AUC)
混淆矩阵 介绍这些概念之前先来介绍一个概念:混淆矩阵(confusion matrix).对于 k 元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果.对于常见的二元分类,它的混淆矩阵是 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure(对于二分类问题)
首先我们可以计算准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比.也就是损失函数是0-1损失时测试数据集上的准确率. 下面在介绍时使用一下例子: 一个 ...
- Recall(召回率)and Precision(精确率)
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7668501.html 前言 机器学习中经过听到" ...
随机推荐
- HDU 1429 胜利大逃亡(续)(bfs+状态压缩,很经典)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1429 胜利大逃亡(续) Time Limit: 4000/2000 MS (Java/Others) ...
- AngularJS 二 指令介绍
初始化AngularJS框架 ng-app指令: 在NG-程序指令是AngularJS应用程序的起点.它自动初始化AngularJS框架.AngularJS框架将在加载整个文档之后首先检查HTML文档 ...
- HTML简介及基本标记
HTML简介 HTML是Hypertext Markup Language的英文缩写,即超文本标记语言 使用 HTML 语言可以: 控制页面和内容的外观 插入的链接检索联机信息 创建表单,收集用户的信 ...
- ArrayList使用
package com.nrxt; import java.util.ArrayList; /** * 概述: * 功能: * 作者:郑肖亚 * 创建时间:2019/3/13 22:01 */ pub ...
- 【TOJ 5065】最长连续子序列(前缀和)
Description 给定一系列非负整数,求最长的连续子序列,使其和是7的倍数. Input 第一行为正整数N(1<=N<=50000),接下来有N行,每行有一个非负整数,所有整数不大于 ...
- C++调用WMI类查询获取操作系统名
#define _WIN32_DCOM #include <iostream> #include <comdef.h> #include <Wbemidl.h> u ...
- Linux 服务器之间文件传输
linux的scp命令: scp就是secure copy的简写,用于在linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器. 有时我们需要获得远程服务器上 ...
- fullPage.js全屏滚动插件API
API sectionsColor:['green','orange','red','lime']; //设置背景颜色 可以为每一个section设置background-color属性 contro ...
- CP-ABE ToolKit 安装笔记
博主论文狗,好久没有来贴博客,最近做实验需要用到属性加密,了解了下CP-ABE,前来记录一下: 网上相关的博文较多,博主看了大部分的,认为下面这两个看完了基本就可以成功安装. 可参见博文: http: ...
- PHP学习课程和培训方向学习路线分享
php语言的优越性,集结了很多的开发爱好者,无论行业前景和个人发展来说,php正飞速的发展,php在不断兼容着类似closures和命名空间 等技术,同时兼顾性能和当下流行的框架.版本是7之后,一直在 ...