hbase与mapreduce集成
一:运行给定的案例
1.获取jar包里的方法

2.运行hbase自带的mapreduce程序
lib/hbase-server-0.98.6-hadoop2.jar
3.具体运行
注意命令:mapredcp。
HADOOP_CLASSPATH是当前运行时需要的环境。

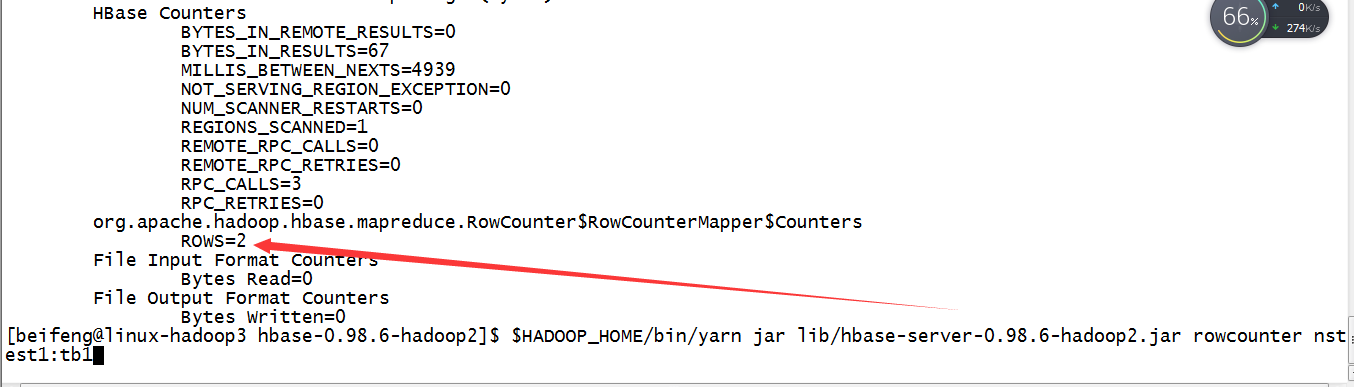
4.运行一个小方法
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar rowcounter nstest1:tb1
二:自定义hbase的数据拷贝
1.需求
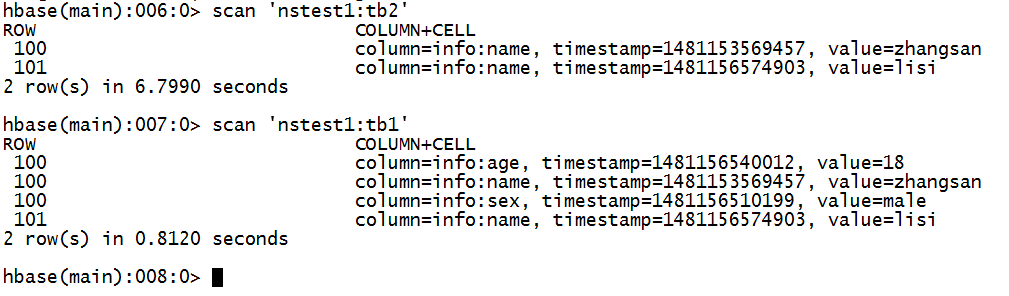
将nstest1:tb1的数据info:name列拷贝到nstest1:tb2
2.新建tb2表

3.书写mapreduce程序
输入:rowkey,result。
package com.beifeng.bigdat; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class HBaseMRTest extends Configured implements Tool{
/**
* map
* @author *
*/
public static class tbMap extends TableMapper<ImmutableBytesWritable, Put>{ @Override
protected void map(ImmutableBytesWritable key, Result value,Context context) throws IOException, InterruptedException {
Put put=new Put(key.get());
for(Cell cell:value.rawCells()){
if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
put.add(cell);
context.write(key, put);
}
}
}
} }
/**
* reduce
* @author *
*/
public static class tbReduce extends TableReducer<ImmutableBytesWritable, Put, ImmutableBytesWritable>{ @Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values,Context context)throws IOException, InterruptedException {
for(Put put:values){
context.write(key, put);
}
} } public int run(String[] args) throws Exception {
Configuration conf=super.getConf();
Job job =Job.getInstance(conf, "hbasemr");
job.setJarByClass(HBaseMRTest.class);
Scan scan=new Scan();
TableMapReduceUtil.initTableMapperJob(
"nstest1:tb1",
scan,
tbMap.class,
ImmutableBytesWritable.class,
Put.class,
job);
TableMapReduceUtil.initTableReducerJob(
"nstest1:tb2",
tbReduce.class,
job);
boolean issucess=job.waitForCompletion(true);
return issucess?0:1;
}
public static void main(String[] args) throws Exception{
Configuration conf=HBaseConfiguration.create();
int status=ToolRunner.run(conf, new HBaseMRTest(), args);
System.exit(status);
} }
4.打成jar包
5.运行语句
加上需要的export前提。
$HADOOP_HOME/bin/yarn jar /etc/opt/datas/HBaseMR.jar com.beifeng.bigdat.HBaseMRTest
6.效果
hbase与mapreduce集成的更多相关文章
- HBase概念学习(七)HBase与Mapreduce集成
这篇文章是看了HBase权威指南之后,依据上面的解说搬下来的样例,可是略微有些不一样. HBase与mapreduce的集成无非就是mapreduce作业以HBase表作为输入,或者作为输出,也或者作 ...
- HBase 与 MapReduce 集成
6. HBase 与 MapReduce 集成 6.1 官方 HBase 与 MapReduce 集成 查看 HBase 的 MapReduce 任务的执行:bin/hbase mapredcp; 环 ...
- 074 hbase与mapreduce集成
一:运行给定的案例 1.获取jar包里的方法 2.运行hbase自带的mapreduce程序 lib/hbase-server-0.98.6-hadoop2.jar 3.具体运行 注意命令:mapre ...
- 【HBase】HBase与MapReduce集成——从HDFS的文件读取数据到HBase
目录 需求 步骤 一.创建maven工程,导入jar包 二.开发MapReduce程序 三.结果 需求 将HDFS路径 /hbase/input/user.txt 文件的内容读取并写入到HBase 表 ...
- hbase运行mapreduce设置及基本数据加载方法
hbase与mapreduce集成后,运行mapreduce程序,同时需要mapreduce jar和hbase jar文件的支持,这时我们需要通过特殊设置使任务可以同时读取到hadoop jar和h ...
- 【HBase】HBase与MapReduce的集成案例
目录 需求 步骤 一.创建maven工程,导入jar包 二.开发MapReduce程序 三.运行结果 HBase与MapReducer集成官方帮助文档:http://archive.cloudera. ...
- 大数据技术之_11_HBase学习_02_HBase API 操作 + HBase 与 Hive 集成 + HBase 优化
第6章 HBase API 操作6.1 环境准备6.2 HBase API6.2.1 判断表是否存在6.2.2 抽取获取 Configuration.Connection.Admin 对象的方法以及关 ...
- Hbase与hive集成与对比
HBase与Hive的对比 1.Hive (1) 数据仓库 Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询. (2) 用于数据分析.清洗 ...
- 《OD大数据实战》HBase整合MapReduce和Hive
一.HBase整合MapReduce环境搭建 1. 搭建步骤1)在etc/hadoop目录中创建hbase-site.xml的软连接.在真正的集群环境中的时候,hadoop运行mapreduce会通过 ...
随机推荐
- Android 编程下如何调整 SwipeRefreshLayout 的下拉刷新距离
SwipeRefreshLayout 的下拉刷新距离比较短,并且也没有提供设置下拉距离的 API,但是看 SwipeRefreshLayout 的源码,会发现有一个内部变量 mDistanceToTr ...
- Maven中多模块的编译顺序
在多模块的工程中,如果模块之间存在依赖关系,那模块的编译必须要有顺序的要求.例如:P(parent)中包含A模块和B模块,且A模块依赖于B模块,那么在P中的pom,xml中需申明为: <modu ...
- TODO:Half Half的设计
IMessageHandler :消息同步处理接口 AbsQueue:消息队列处理层,可以使用Template Method进行设计 INetWorkLayer:专门处理网络IO的,并附带多线程与异步 ...
- ZOJ2539 Energy Minimization(最小割)
题目大概说,给一个n个格子的矩阵,每个格子都有一个数字pi.求这个函数的最小值: 其中xi的取值是0或1,v0.v1已知,j是和i在矩阵中上下左右相邻的位置且j>i. 这个式子有三个加数组成A+ ...
- BZOJ3931 [CQOI2015]网络吞吐量(最大流)
没啥好说的,有写过类似的,就是预处理出最短路上的边建容量网络. #include<cstdio> #include<cstring> #include<queue> ...
- SplendidCRM 如何添加及使用中文语言包
SplendidCRM 功能很强大,也支持多国语言,但关于中文语言安装的介绍在网上一直都找到,自已摸索了一下,成功使SplendidCRM应用中文,以下是安装方法. 版本号:SplendidCRM 7 ...
- POJ 3373 Changing Digits(DP)
题目链接 记录路径的DP,看的别人的思路.自己写的也不好,时间居然2000+,中间的取余可以打个表,优化一下. 写的各种错,导致wa很多次,写了一下午,自己构造数据,终于发现了最后一个bug. dp[ ...
- [插头DP自我总结]
[HNOI 2007]神奇游乐园 #include <bits/stdc++.h> #define maxn 110 using namespace std; typedef long l ...
- COJ969 WZJ的数据结构(负三十一)
WZJ的数据结构(负三十一) 难度级别:D: 运行时间限制:3000ms: 运行空间限制:262144KB: 代码长度限制:2000000B 试题描述 A国有两个主基站,供给全国的资源.定义一个主基站 ...
- C# DateTime 日期加1天 减一天 加一月 减一月 等方法(转)
//今天 DateTime.Now.Date.ToShortDateString(); //昨天,就是今天的日期减一 DateTime.Now.AddDays(-1).ToShortDateStrin ...