机器学习六--K-means聚类算法
机器学习六--K-means聚类算法
想想常见的分类算法有决策树、Logistic回归、SVM、贝叶斯等。分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应。但是很多时候上述条件得不到满足,尤其是在处理海量数据的时候,如果通过预处理使得数据满足分类算法的要求,则代价非常大,想想如果给你50个G这么大的文本,里面已经分好词,这时需要将其按照给定的几十个关键字进行划分归类,监督学习的方法确实有点困难,而且也不划算,前期工作做得太多了。
这时候可以考虑使用聚类算法,我们只需要知道这几十个关键字是什么就可以了。聚类属于无监督学习,相比于分类,聚类不依赖预定义的类和类标号的训练实例。本文首先介绍聚类的基础——距离与相异度,然后介绍一种常见的聚类算法——K-means聚类。
在正式讨论聚类前,我们要先弄清楚一个问题:如何定量计算两个可比较元素间的相异度。前面的这些知识弄懂了,加上K-means的定义,基本上就可以大概理解K-means的算法了,不算一个特别难的算法。用通俗的话说,相异度就是两个东西差别有多大,例如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能我们直观感受到的。但是,计算机没有这种直观感受能力,我们必须对相异度在数学上进行定量定义。
设X={x1,x2,x3,,,,xn},Y={y1,y2,y3,,,,yn} ,其中X,Y是两个元素项,各自具有n个可度量特征属性,那么X和Y的相异度定义为:d=(X,Y)=f(X,Y)->R,其中R为实数域。也就是说相异度是两个元素对实数域的一个映射,所映射的实数定量表示两个元素的相异度。
下面介绍不同类型变量相异度计算方法。
标量
标量也就是无方向意义的数字,也叫标度变量。现在先考虑元素的所有特征属性都是标量的情况。例如,计算X={2,1,102}和Y={1,3,2}的相异度。一种很自然的想法是用两者的欧几里得距离来作为相异度,欧几里得距离的定义如下:

其意义就是两个元素在欧氏空间中的集合距离,因为其直观易懂且可解释性强,被广泛用于标识两个标量元素的相异度。将上面两个示例数据代入公式,可得两者的欧氏距离为:
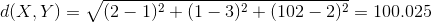
除欧氏距离外,常用作度量标量相异度的还有曼哈顿距离和闵可夫斯基距离,两者定义如下:
曼哈顿距离: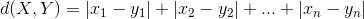
闵可夫斯基距离: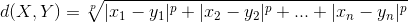
欧氏距离和曼哈顿距离可以看做是闵可夫斯基距离在p=2和p=1下的特例。
0-1规格化
下面要说一下标量的规格化问题。上面这样计算相异度的方式有一点问题,就是取值范围大的属性对距离的影响高于取值范围小的属性。例如上述例子中第三个属性的取值跨度远大于前两个,这样不利于真实反映真实的相异度,为了解决这个问题,一般要对属性值进行规格化。所谓规格化就是将各个属性值按比例映射到相同的取值区间,这样是为了平衡各个属性对距离的影响。通常将各个属性均映射到[0,1]区间,映射公式为:
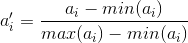
其中max(ai)和min(ai)表示所有元素项中第i个属性的最大值和最小值。例如,将示例中的元素规格化到[0,1]区间后,就变成了X’={1,0,1},Y’={0,1,0},重新计算欧氏距离约为1.732。
二元变量
所谓二元变量是只能取0和1两种值变量,有点类似布尔值,通常用来标识是或不是这种二值属性。对于二元变量,上一节提到的距离不能很好标识其相异度,我们需要一种更适合的标识。一种常用的方法是用元素相同序位同值属性的比例来标识其相异度。
设有X={1,0,0,0,1,0,1,1},Y={0,0,0,1,1,1,1,1},可以看到,两个元素第2、3、5、7和8个属性取值相同,而第1、4和6个取值不同,那么相异度可以标识为3/8=0.375。一般的,对于二元变量,相异度可用“取值不同的同位属性数/单个元素的属性位数”标识。
上面所说的相异度应该叫做对称二元相异度。现实中还有一种情况,就是我们只关心两者都取1的情况,而认为两者都取0的属性并不意味着两者更相似。例如在根据病情对病人聚类时,如果两个人都患有肺癌,我们认为两个人增强了相似度,但如果两个人都没患肺癌,并不觉得这加强了两人的相似性,在这种情况下,改用“取值不同的同位属性数/(单个元素的属性位数-同取0的位数)”来标识相异度,这叫做非对称二元相异度。如果用1减去非对称二元相异度,则得到非对称二元相似度,也叫Jaccard系数,是一个非常重要的概念。
分类变量
分类变量是二元变量的推广,类似于程序中的枚举变量,但各个值没有数字或序数意义,如颜色、民族等等,对于分类变量,用“取值不同的同位属性数/单个元素的全部属性数”来标识其相异度。
序数变量
序数变量是具有序数意义的分类变量,通常可以按照一定顺序意义排列,如冠军、亚军和季军。对于序数变量,一般为每个值分配一个数,叫做这个值的秩,然后以秩代替原值当做标量属性计算相异度。
向量
对于向量,由于它不仅有大小而且有方向,所以闵可夫斯基距离不是度量其相异度的好办法,一种流行的做法是用两个向量的余弦度量,这个应该大家都知道吧,其度量公式为:
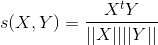
其中||X||表示X的欧几里得范数。要注意,余弦度量度量的不是两者的相异度,而是相似度!
什么是聚类?
所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。
与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域,相应的算法也非常的多。本文仅介绍一种最简单的聚类算法——k均值(k-means)算法。
k均值算法的计算过程非常直观:
1、从D中随机取k个元素,作为k个簇的各自的中心。
2、分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇。
3、根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。
4、将D中全部元素按照新的中心重新聚类。
5、重复第4步,直到聚类结果不再变化。
6、将结果输出。
时间复杂度:O(T*n*k*m)
空间复杂度:O(n*m)
n:元素个数,k:第一步中选取的元素个数,m:每个元素的特征项个数,T:第5步中迭代的次数
参考:
T2噬菌体(很多理解都是借鉴这位大牛的,还在阅读学习TA的其他博文)
总结
接下来的目标就是Logistic回归、SVM。之前看过很多遍有关这两个算法的博客,但是理解还是不够深入,继续学习,希望有所收获。
机器学习六--K-means聚类算法的更多相关文章
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习:Python实现聚类算法(三)之总结
考虑到学习知识的顺序及效率问题,所以后续的几种聚类方法不再详细讲解原理,也不再写python实现的源代码,只介绍下算法的基本思路,使大家对每种算法有个直观的印象,从而可以更好的理解函数中参数的意义及作 ...
- 机器学习——详解经典聚类算法Kmeans
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第12篇文章,我们一起来看下Kmeans聚类算法. 在上一篇文章当中我们讨论了KNN算法,KNN算法非常形象,通过距离公 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 机器学习——利用K-均值聚类算法对未标注数据分组
聚类是一种无监督的学习,它将相似的对象归到同一簇中.它有点像全自动分类.聚类方法几乎可以应用到所有对象,簇内的对象越相似,聚类的效果越好. K-均值(K-means)聚类算法,之所以称之为K-均值是因 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
随机推荐
- [Solution] 一步一步WCF(2) 终结点Endpoint
繁忙的一天又一天,不管其他,先继续WCF吧. Endpoint包含地址,绑定,契约三要素.WCF作为一个Windows平台下最大的通信框架.通过终结点承载了所有通信功能.所以终结点的作用将非常重要. ...
- 计算几何 : 凸包学习笔记 --- Graham 扫描法
凸包 (只针对二维平面内的凸包) 一.定义 简单的说,在一个二维平面内有n个点的集合S,现在要你选择一个点集C,C中的点构成一个凸多边形G,使得S集合的所有点要么在G内,要么在G上,并且保证这个凸多边 ...
- C#设计模式——观察者模式(Observer Pattern)
一.概述在软件设计工作中会存在对象之间的依赖关系,当某一对象发生变化时,所有依赖它的对象都需要得到通知.如果设计的不好,很容易造成对象之间的耦合度太高,难以应对变化.使用观察者模式可以降低对象之间的依 ...
- 安装jdk For Windows
1.下载JDK查看最新:http://www.oracle.com/technetwork/java/javase/downloads/index.html根据操作系统选择合适的JDK进行下载2.运行 ...
- VS2013 编译程序时提示 无法查找或打开 PDB 文件
"Draw.exe"(Win32): 已加载"C:\Users\YC\Documents\Visual Studio 2013\Projects\Draw\Debug\ ...
- lavarel框架中如何使用ajax提交表单
开门见山,因为laravel以post形式提交数据时候需要加{{csrf_field()}}防止跨站攻击,所以当你用ajax提交表单时候自然也要加 在网上看了很多的解决方式,我是用下面这种方法解决的: ...
- 解决My eclipse 工程发布时端口占用问题
如果运行后如图的错,需要进行如下操作来解决: a:打开cmd,输入netstat -ano 找到本地地址为8080的最后一项的数字,这个数字就是端口号. b:再输入taskkill /t /pid 端 ...
- 中国快递包裹总量的预测-基于SARIMA模型
code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs && docu ...
- 开启Windows Server 2008 R2上帝模式
TAG标签: 摘要:这个“God Mode” 应该大部分的网友都听过了,只是在 Windows Server 2008 R2 上也支持此一功能.启用方式非常简单,在桌面新建一个文件夹,命名为: God ...
- CSS层次选择器温故-2
1.层次选择器 通过HTML的DOM元素间的层次关系获取元素,层次关系包括后代.父子.相邻兄弟和通用兄弟,通过其中某类关系可以方便快捷地选定需要的元素 2.语法 3.兼容性 IE7以及以上版本 4.后 ...