想买保时捷的运维李先生学Java性能之 垃圾收集器
前言
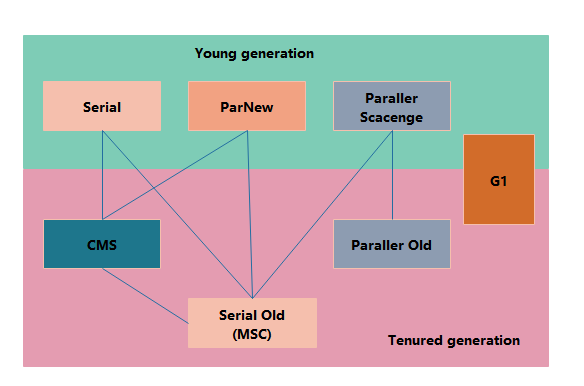
一、Serial收集器
二、ParNew收集器
三、Paraller Scanvenge收集器
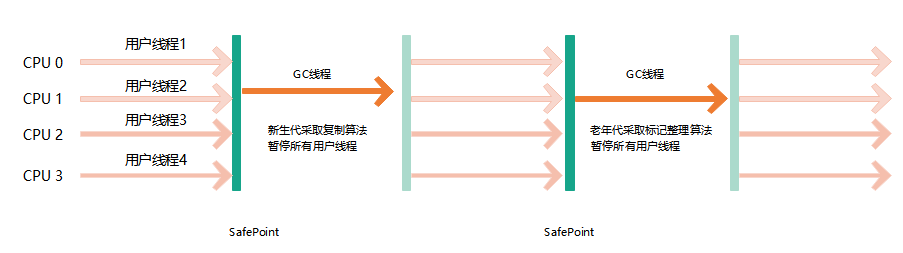
4、Serial Old收集器

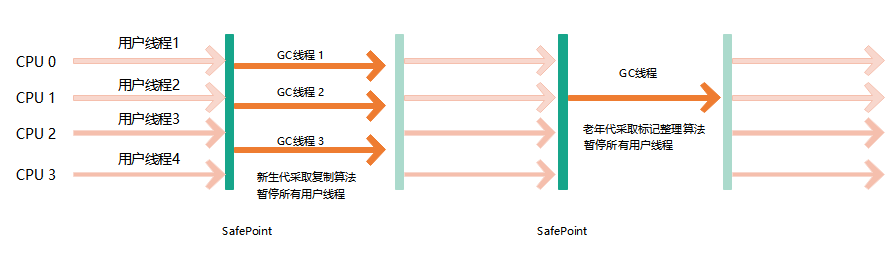
五、parallel Old 收集器
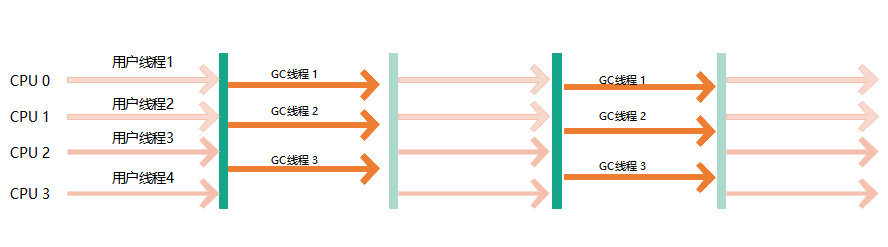
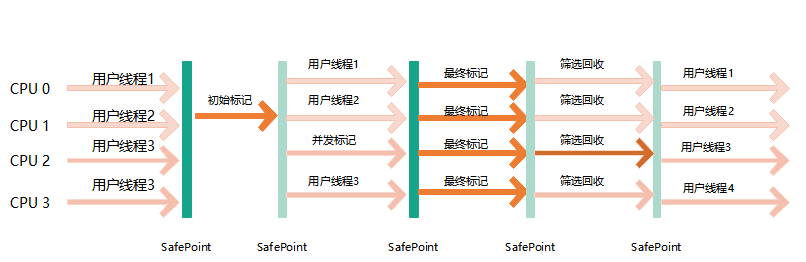
6、CMS收集器

七、G1(Garbage-First)收集器
想买保时捷的运维李先生学Java性能之 垃圾收集器的更多相关文章
- 想买保时捷的运维李先生学Java性能之 垃圾收集算法
前言 从原来只知道-Xms.-Xmx是设置内存的,到现在稍微理解了一些堆内存等Java虚拟机的一些知识.明白了技术这一个东西还是得要有输入才能实践,原理与实践要相辅相成,后续把JVM的监控好好总结一下 ...
- 想买保时捷的运维李先生学Java性能之 运行时数据区域
前言 不知道自己不知道,不知道自己知道,知道自己不知道,知道自己知道,目前处于知道自己不知道这个阶段,很痛苦啊,干了4年了运维,是一个坎.越来越发觉想要走得远,还是得扎根底. 一.运行时数据区域 ...
- 想买保时捷的运维李先生学Java性能之 生存与毁灭
一.判断对象是否存活 1.引用计数算法 给对象中添加一个引用计数器,每当有一个地方引用它时,计数器就加1:当引用失效时,计数器的值就减1:任何时刻计数器为0的对象是不可能再被使用的.引用计 ...
- 想买保时捷的运维李先生学Java性能之 JIT即时编译器
前言 本文记录日常学习<深入理解Java虚拟机>,不知道为啥感觉看一遍也就过了,喜欢动动手理解理解,这样才有点感觉,静不下心来的时候,看书抄书也可以用这个办法. 一.什么是JIT(Just ...
- Linux运维不可不知的性能监控和调试工具
Linux运维不可不知的性能监控和调试工具 1 nagios Nagios是一个开源监控解决方案,我觉得他可以监控一切 ,可以看一下我以前的文章:NAGIOS 2 ps #用来查看程序的运行情况 ps ...
- Python_oldboy_自动化运维之路_函数,装饰器,模块,包(六)
本节内容 上节内容回顾(函数) 装饰器 模块 包 1.上节内容回顾(函数) 函数 1.为什么要用函数? 使用函数之模块化程序设计,定义一个函数就相当于定义了一个工具,需要用的话直接拿过来调用.不使用模 ...
- 从零开始学 Java - Spring AOP 拦截器的基本实现
一个程序猿在梦中解决的 Bug 没有人是不做梦的,在所有梦的排行中,白日梦最令人伤感.不知道身为程序猿的大家,有没有睡了一觉,然后在梦中把睡之前代码中怎么也搞不定的 Bug 给解决的经历?反正我是有过 ...
- 从零起步做到Linux运维经理, 你必须管好的23个细节
“不想成为将军的士兵,不是好士兵”-拿破仑 如何成为运维经理? 一般来说,运维经理大概有两种出身:一种是从底层最基础的维护做起,通过出色的维护工作,让公司领导对这个人非常认可,同时对Linux运维工作 ...
- 从零起步做到Linux运维经理,你必须管好的23个细节
不想成为将军的士兵,不是好士兵-拿破仑 如何成为运维经理?成为运维经理需要什么样的能力?我想很多运维工程师都会有这样的思考和问题. 如何成为运维经理.一般来说,运维经理大概有两种出身,一种是从底层最基 ...
随机推荐
- 从四个问题透析Linux下C++编译&链接
摘要:编译&链接对C&C++程序员既熟悉又陌生,熟悉在于每份代码都要经历编译&链接过程,陌生在于大部分人并不会刻意关注编译&链接的原理.本文通过开发过程中碰到的四个典型 ...
- JAVA基础之代码简洁之道
引言 普通的工程师堆砌代码,优秀的工程师优雅代码,卓越的工程师简化代码.如何写出优雅整洁易懂的代码是一门学问,也是软件工程实践里重要的一环.--来自网络 背景 软件质量,不但依赖于架构及项目管理,更与 ...
- Django 联合唯一UniqueConstraint
from django.db import models class UserAttention(models.Model): watcher = models.ForeignKey('user.Us ...
- python中numpy.savetxt 参数
转载:https://blog.csdn.net/qq_36535820/article/details/99543188 numpy.savetxt 参数 numpy.savetxt(fname,X ...
- STM32之旅4——USART
STM32之旅4--USART 串口也是用的比较多的,在STM32CubeMX中生成代码后,需要添加一些代码才可以用. drv_usart.h: #ifndef __DRV_USART_H #defi ...
- 执行新增和修改操作报错connection is read-only. Queries leading to data modification are not allowed
出现这个问题的原因是默认事务只有只读权限,因此要添加下面的每一个add*,del*,update*等等. 分别给予访问数据库的权限. 方法名的前缀有该关键字设置了read-only=true,将其改为 ...
- CentOS7 下 swap 分区的创建、删除及相关配置
一般我们在购买云服务器(例如:阿里云ECS.腾讯云服务器)的时候,选择 CentOS 7 系统之后,登录系统,发现 swap 大小为 0(即没有分配). 如果我们想在该 服务器上安装 Oracle 数 ...
- 用ip xfrm搭ipsec隧道
拓扑如下 基本的IP配置就不说了,直接写重点,在LS上配置 #配置SA ip xfrm state add src 194.168.10.4 dst 194.168.10.5 proto esp sp ...
- Javascript判断数据类型的五种方式及其特殊性
Javascript判断数据类型的五种方式及区别 @ 目录 typeof instanceof Object.prototype.toString isArray iisNaN ----------- ...
- 《Kafka笔记》2、环境搭建、Topic管理
目录 一.Kafka环境搭建和Topic管理 1 单机环境搭建 1.1 环境准备 1.1.1 JDK 安装 1.1.2 配置主机名和ip 1.1.3 关闭防火墙和防火墙开机自启动 1.1.4 zook ...